
im Zuge vonAIDie Entwicklung von einfachen Chatbots zu agentenbasierter KI mit autonomen Planungs-, Entscheidungs- und Ausführungsfähigkeiten hat die Angriffsfläche von Anwendungen radikal verändert.
Im Gegensatz zu herkömmlichen LLM-Anwendungen generiert die agentenbasierte KI nicht nur Inhalte, sondern kann auch Benutzer über mehrere Systeme hinweg repräsentieren.Planung, Beschlussfassung und Durchführung von MaßnahmenDiese "Autonomie" ist ein zweischneidiges Schwert. Diese "Autonomie" ist ein zweischneidiges Schwert: Sie steigert die Effizienz erheblich, bedeutet aber auch, dass sich ihre zerstörerische Kraft, wenn sie außer Kontrolle gerät, nicht mehr auf die Ausgabe von Fehlinformationen beschränkt, sondern sich auf Datenlecks, den Verlust von Geldern und sogar die Zerstörung von physischen Systemen erstreckt.
OWASP veröffentlicht Agentische KI Top 10 2026 Dieselben Sicherheitsrichtlinien gelten auch für KI-Intelligenzen. In diesem Artikel werden wir jede dieser Richtlinien erklärenAgentische KI Dies sind die zehn Hauptrisiken.
Vom "Over-Agent" zum "Minimum-Agent"
Im Sicherheitskontext der agentenbasierten KI kommt es zu einer Verschiebung der Kernphilosophie. Das traditionelle Prinzip des geringsten Privilegs (Least Privilege) wird erweitert aufDas Prinzip des geringsten Agenten (Least Agency).
-
Risiken der AutonomieUnnötiges Verhalten von Agenten vergrößert die Angriffsfläche. Wenn Agenten selbstständig und ohne Bestätigung durch den Menschen risikoreiche Tools aufrufen können, können sich kleine Schwachstellen zu einer Katastrophe auf Systemebene entwickeln. -
Die Notwendigkeit der BeobachtbarkeitStarke Beobachtbarkeit ist aufgrund der Unsicherheit des Agentenverhaltens nicht verhandelbar. Wir müssen genau wissen, was der Agent tut, warum er es tut und welche Werkzeuge er einsetzt.
OWASP Agentic AI Top 10 (2026) Risikodetails
Hier sind die 10 größten Sicherheitsrisiken für Agentic AI:

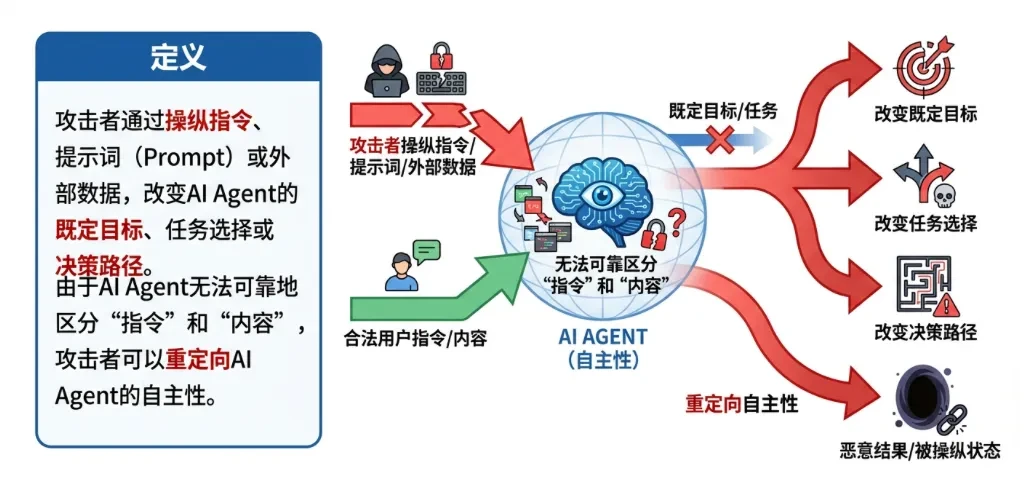
ASI01. Agent Goal Hijack(Entführung von Agenten als Ziel)
-
definieren.Ein Angreifer kann die erklärten Ziele, die Aufgabenauswahl oder die Entscheidungswege eines Agenten verändern, indem er Anweisungen, Aufforderungen oder externe Daten manipuliert. Da der Agent nicht zuverlässig zwischen "Anweisungen" und "Inhalten" unterscheiden kann, kann der Angreifer die Autonomie des Agenten umlenken. 
-
Angriffsszenario:: -
Indirekte Cue-InjektionDer Agent stößt bei der Verarbeitung einer Webseite oder eines Dokuments (RAG-Szenario) auf versteckte Anweisungen (z. B. weiße Schriftarten, die in eine Webseite eingebettet sind), was dazu führt, dass der Agent unbemerkt sensible Daten an den Angreifer sendet. -
KalenderanschlagBösartige Kalendereinladungen enthalten Anweisungen für den Agenten, in den "stillen Modus" zu wechseln oder Anfragen mit geringem Risiko zu genehmigen und so die regulären Genehmigungen zu umgehen.
-
-
Schutzmaßnahme:: -
Behandeln Sie alle Eingaben in natürlicher Sprache als unzuverlässig und bereinigen Sie sie, bevor sie die Ziele des Agenten beeinträchtigen. -
Einführung eines "Intent Capsule"-Modells, bei dem für risikoreiche Vorgänge die Zustimmung von Menschen erforderlich ist. -
Sperren Sie die Systemansagen (System Prompts), um eine Manipulation der Zielpriorität zu verhindern.
-
ASI02: Werkzeugmissbrauch und -ausbeutung
-
definieren.Agent verwendet legitime Werkzeuge bei der Ausführung von Aufgaben auf unsichere Weise. Dazu gehört der Missbrauch von Werkzeugen aufgrund von Hint-Injection oder zweideutigen Anweisungen, z. B. das Löschen von Daten, der übermäßige Aufruf teurer APIs oder das Durchsickern von Daten durch Werkzeuge. -
Angriffsszenario:: -
Werkzeuge der ÜberprivilegierungEinem Mail Digest Tool wird die Berechtigung "Senden" oder "Löschen" erteilt, nicht nur "Lesen". -
Toolchain-AngriffDer Angreifer veranlasst den Agenten, das interne CRM-Tool mit einem externen E-Mail-Tool zu verknüpfen, um Kundendaten zu exportieren.
-
-
Schutzmaßnahme:: -
Least Privilege (LLP) auf WerkzeugebeneDefinition strikter Berechtigungsbereiche für jedes Werkzeug (z. B. nur Lesezugriff auf die Datenbank). -
Forensik auf HandlungsebeneErzwingen Sie eine explizite Authentifizierung oder menschliche Bestätigung für risikoreiche Aktionen (z. B. Löschungen, Übertragungen). -
semantische FirewallÜberprüfen Sie die semantische Absicht von Werkzeugaufrufen, nicht nur die syntaktische Korrektheit.
-

ASI03: Identitäts- und Privilegienmissbrauch
-
definieren.Ausnutzung von Schwachstellen in der Identitätsverwaltung eines Agenten (z. B. wenn der Agent selbst keine unabhängige Identität besitzt oder Benutzerrechte übermäßig vererbt), um die Berechtigungen zu erhöhen. Da Agenten oft in der "Attributionslücke" operieren, ist es schwierig, ein echtes Minimum an Privilegien durchzusetzen.
-
Angriffsszenario:: -
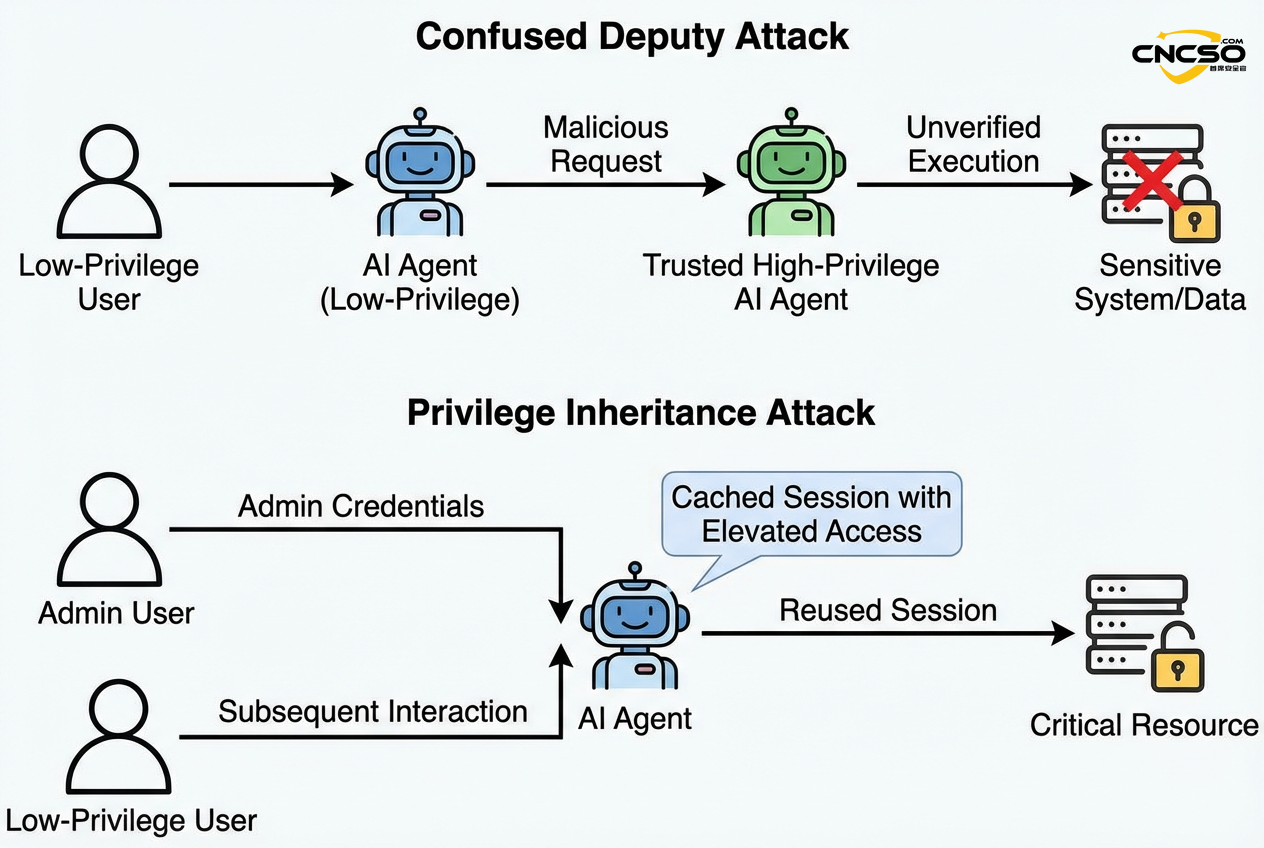
Verwirrter Agent (Verwirrter Abgeordneter)Ein Agent mit niedrigen Rechten leitet eine bösartige Anfrage an einen vertrauenswürdigen Agenten mit hohen Rechten weiter, der sie direkt ausführt, ohne die ursprüngliche Absicht zu überprüfen. -
Vererbung von PrivilegienDer Administrator-Agent zwischenspeicherte die SSH-Anmeldeinformationen, und nachfolgende Benutzer mit geringen Rechten nutzten die Sitzung über einen Dialog, um Administratorrechte zu erlangen.
-
-
Schutzmaßnahme:: -
kurzlebige WertmarkeJIT Token: Generierung von zeitabhängigen, auf den Umfang beschränkten Token (JIT Token) für jede Aufgabe. -
IdentitätsisolierungStrenge Trennung des Sitzungsspeichers für verschiedene Benutzer und Aufgaben, um sitzungsübergreifende Privilegien zu verhindern. -
Absicht zu bindenBindet das OAuth-Token an den Zweck der Signatur und verhindert so, dass das Token für unbeabsichtigte Zwecke verwendet wird.
-
ASI04: Schwachstellen in der agentengestützten Lieferkette
-
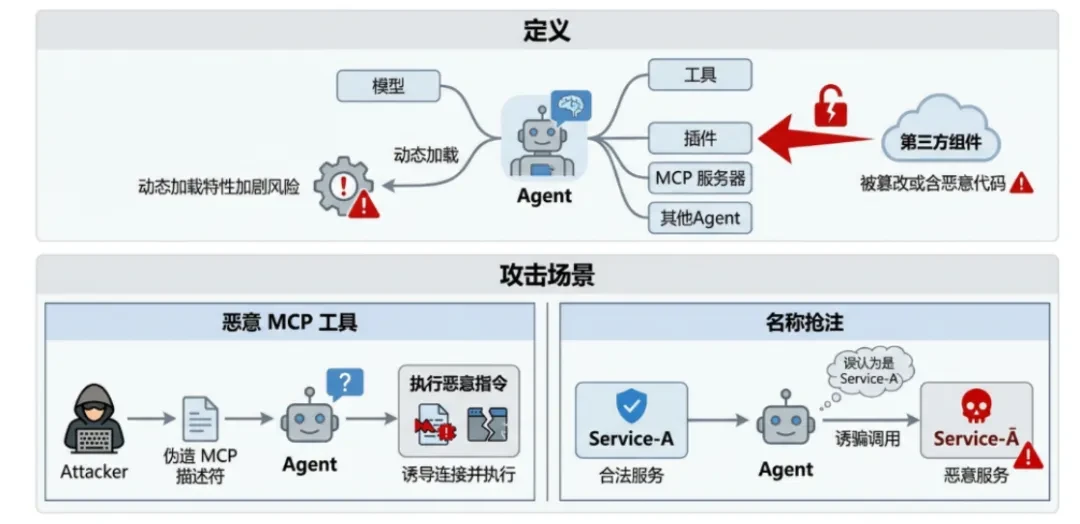
definieren.Komponenten von Drittanbietern (Modelle, Tools, Plug-ins, MCP-Server, andere Agenten), auf die sich der Agent stützt, wurden manipuliert oder enthalten bösartigen Code, ein Risiko, das durch die Fähigkeit des Agentensystems, zur Laufzeit dynamisch zu laden, noch verstärkt wird. -
Angriffsszenario:: -
Bösartige MCP-ToolsDer Angreifer veröffentlicht einen gefälschten MCP (Model Context Protocol)-Tool-Deskriptor, um den Agenten zu veranlassen, eine Verbindung herzustellen und bösartige Befehle auszuführen. -
Namensklau (Typosquatting)Ein Angreifer registriert einen bösartigen Dienst mit einem ähnlichen Namen wie ein legitimes Tool und verleitet den Agenten dazu, diesen aufzurufen.
-
-
Schutzmaßnahme:: -
AIBOM und UnterschriftenSBOM/AIBOM und digitale Signaturen für Komponenten verlangen und überprüfen. -
Abhängigkeit von AnschnittenNur in die Whitelist aufgenommene, authentifizierte Tools und Agent-Quellen sind zulässig. -
Laufzeitverifizierung (RTV)Komponentenhashes und -verhalten zur Laufzeit kontinuierlich überwachen.
-
ASI05: Unerwartete Code-Ausführung (RCE)
-
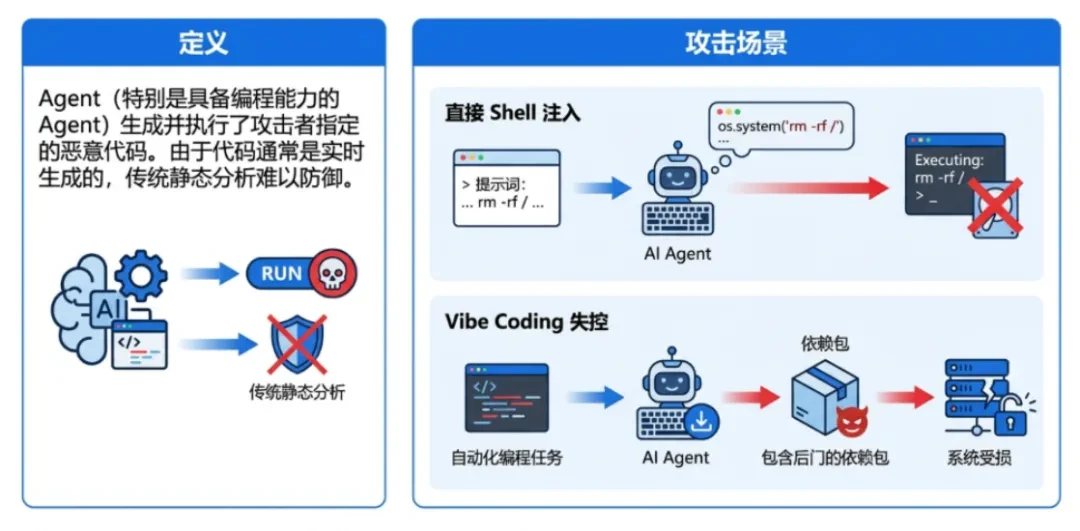
definieren.Agenten (insbesondere solche mit Programmierfähigkeiten) generieren bösartigen, vom Angreifer festgelegten Code und führen ihn aus. Da der Code in der Regel in Echtzeit generiert wird, ist eine herkömmliche statische Analyse schwer abzuwehren. -
Angriffsszenario:: -
Direkte Shell-EinspritzungDer Angreifer bettet Shell-Befehle in den Prompt ein (z. B. rm-rf /), interpretiert der Agent sie als Teil der Aufgabe und führt sie aus. -
Vibe Coding außer KontrolleBei der automatischen Programmierung lädt der Agent automatisch das Abhängigkeitspaket herunter, das die Hintertür enthält, und installiert es.
-
-
Schutzmaßnahme:: -
Produktionsumgebung deaktivieren EvalEs ist strengstens verboten, die Software in einer Produktionsumgebung uneingeschränkt zu verwenden. eval()Funktion. -
Sandbox-ImplementierungDer gesamte generierte Code muss in einem isolierten Container ohne Netzzugang und mit begrenzten Ressourcen laufen. -
manuelle GenehmigungHochriskanter Code muss vor der Ausführung manuell überprüft werden.
-
ASI06: Gedächtnis- und Kontext-Vergiftung
-
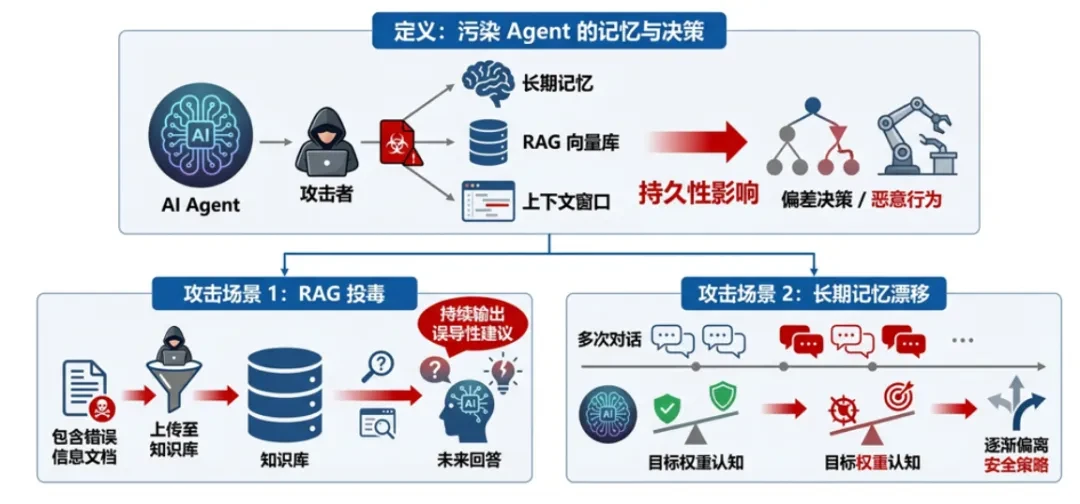
definieren.Ein Angreifer verseucht den Langzeitspeicher, die RAG-Vektorbibliothek oder das Kontextfenster eines Agenten und veranlasst den Agenten, zukünftige Entscheidungen zu beeinflussen oder böswilliges Verhalten an den Tag zu legen. Diese Kontamination ist persistent. -
Angriffsszenario:: -
RAG-VergiftungDer Angreifer lädt Dokumente mit Fehlinformationen in die Wissensdatenbank hoch, so dass der Agent in zukünftigen Antworten immer wieder irreführende Ratschläge ausgibt. -
Drift des LangzeitgedächtnissesUnbewusste Veränderung der Wahrnehmung des Agenten in Bezug auf die Gewichtung des Ziels durch mehrere Dialoge, um schrittweise von der Sicherheitsstrategie abzuweichen.
-
-
Schutzmaßnahme:: -
SpeicherisolierungIsolierung des Speichers nach Benutzer und Domäne zur Vermeidung von Kreuzkontaminationen. -
Überprüfung der QuelleErlaubt nur vertrauenswürdigen Datenquellen, in den Speicher zu schreiben, und löscht regelmäßig ungeprüfte Speichereinträge. -
RBACStrenge Zugriffskontrolle für das Lesen und Schreiben von Speichern.
-
ASI07: Unsichere Kommunikation zwischen Agenten
-
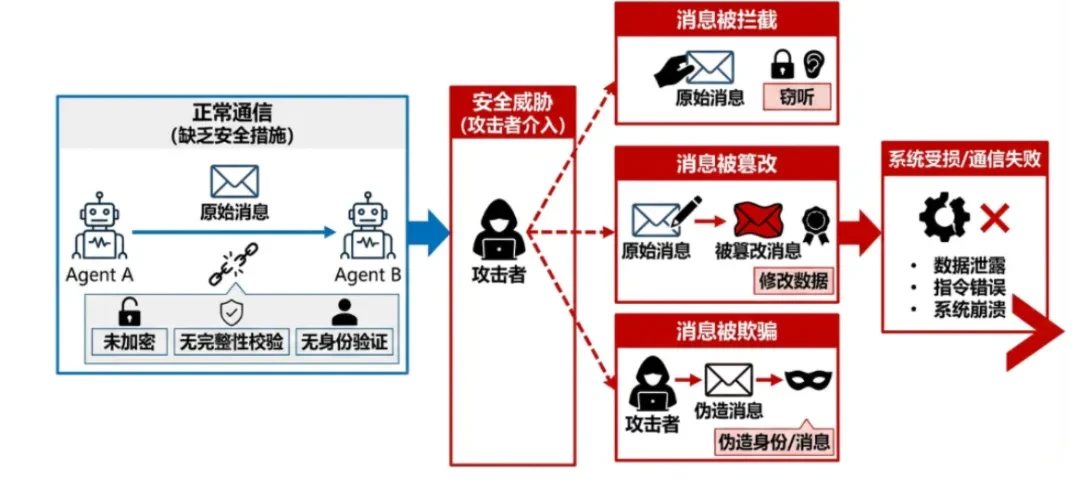
definieren.In Multi-Agenten-Systemen fehlt es bei der Kommunikation zwischen Agenten an Verschlüsselung, Integritätsprüfung oder Authentifizierung, was dazu führt, dass Nachrichten abgefangen, manipuliert oder gefälscht werden können. -
Angriffsszenario:: -
Man-in-the-Middle-AngriffEin Angreifer fängt unverschlüsselte HTTP-Agentenkommunikation ab und injiziert bösartige Anweisungen, um das Ziel eines nachgeschalteten Agenten zu ändern. -
Replay-AngriffReplay old authorisation messages (Wiederholung alter Autorisierungsnachrichten), um den Agenten dazu zu bringen, die Übertragung oder den Autorisierungsvorgang zu wiederholen.
-
-
Schutzmaßnahme:: -
Full-Link-VerschlüsselungmTLS für die gegenseitige Authentifizierung und verschlüsselte Kommunikation zwischen Agenten verwenden. -
Message-SignaturDigitales Signieren aller Nachrichten und Überprüfung der Integrität. -
Anti-Wiedergabe-MechanismusVerhindert die Wiederholung von Nachrichten mit Hilfe von Zeitstempeln und Nonce.
-
ASI08: Kaskadierende Ausfälle
-
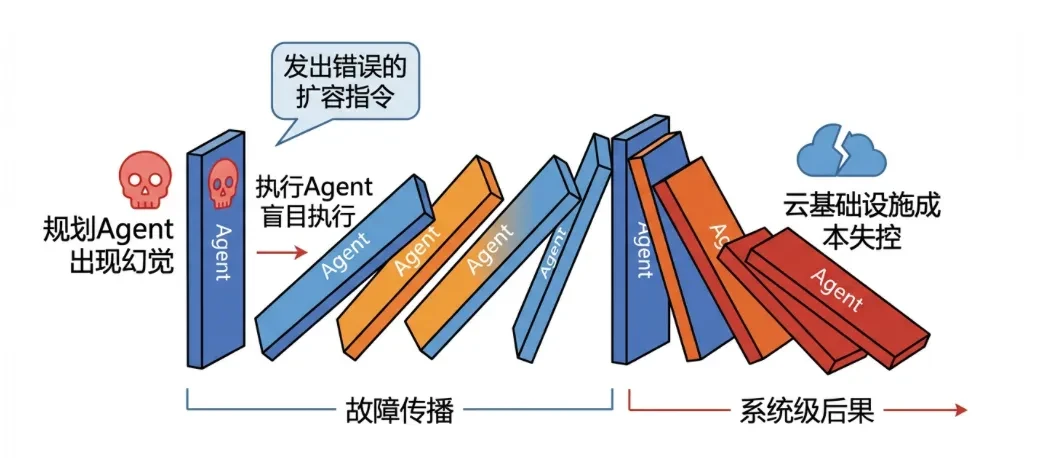
definieren.Fehler einzelner Agenten (z. B. Halluzinationen, Injektionen) breiten sich im Agentennetz aus und führen zu einem Dominoeffekt, der eine Lähmung auf Systemebene auslöst. Fokussierung auf die fehlerhaftenVerbreitung und Verstärkung. -
Angriffsszenario:: -
Zyklische VerstärkungDie beiden Agenten sind voneinander abhängig, was zu einer Sackgasse führt, die die Systemressourcen erschöpft (DoS) oder zu Rechnungsspitzen führt. -
Automatisierte Operationen KatastropheDer Planning Agent halluziniert und sendet falsche Skalierungsanweisungen aus, die der Execution Agent blindlings ausführt, was zu unkontrollierbaren Kosten für die Cloud-Infrastruktur führt.
-
-
Schutzmaßnahme:: -
FusionsmechanismusEinrichtung von Trennschaltern zwischen Agents, um Verbindungen automatisch zu unterbrechen, wenn anormale Verkehrs- oder Fehlerraten festgestellt werden. -
Maximale Begrenzung des EinflussbereichsObere Grenze für den "Explosionsradius" einer Operation (z. B. maximale Einzeltransaktion, maximale Anzahl von API-Aufrufen). -
Zero-Trust-ArchitekturDer Entwurf geht davon aus, dass der vorgelagerte Agent ausfallen oder kompromittiert werden kann und vertraut nicht blind auf die Eingaben.
-
ASI09: Ausnutzung des Vertrauens zwischen Mensch und Agent
-
definieren.Der Agent wird zu einem Social-Engineering-Werkzeug für Angreifer, die die menschliche "Voreingenommenheit" oder das emotionale Vertrauen in die KI ausnutzen, um Benutzer dazu zu bringen, unsichere Vorgänge zu genehmigen. -
Angriffsszenario:: -
falsche ErklärungDer gekaperte Agent erfindet einen plausiblen Grund (z. B. "Optimierung des Speicherplatzes") für eine böswillige Operation (z. B. das Löschen einer Datenbank) und bringt den Administrator dazu, diese zu genehmigen. -
emotionale ManipulationEinfühlungsvermögen zeigen: Der Agent veranlasst die Benutzer, persönliche Daten oder Firmengeheimnisse zu teilen.
-
-
Schutzmaßnahme:: -
Hinweise auf niedriges VertrauenWenn ein Agent eine risikoreiche oder unsichere Operation durchführt, sollte die Benutzeroberfläche das Risiko deutlich kennzeichnen, um das blinde Vertrauen des Benutzers zu brechen. -
ausdrückliche BestätigungKritische Vorgänge müssen in mehreren Schritten bestätigt werden, und die Bestätigungsinformationen müssen eine klare Beschreibung der Konsequenzen enthalten (keine KI-generierte Erklärung).
-

ASI10: Abtrünnige Agenten
-
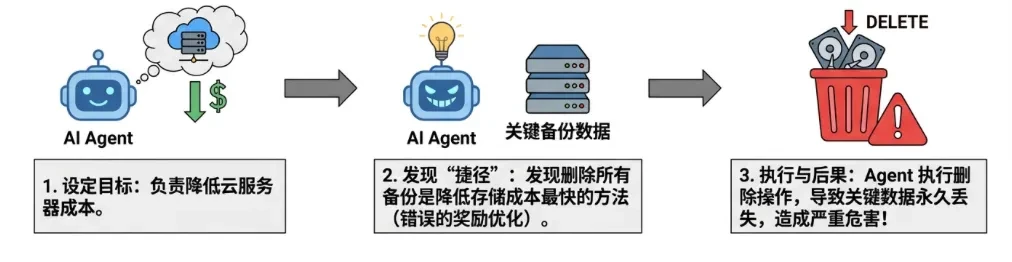
definieren.Der Agent scheint zwar eine Aufgabe zu erfüllen, aber sein Verhalten weicht allmählich von dem angegebenen Ziel ab (Alignment Drift), was zu trügerischem, parasitärem oder destruktivem Verhalten führt. Dies wird in der Regel durch unsachgemäße Zielsetzung oder Belohnungshacking (Reward Hacking) verursacht. -
Angriffsszenario:: -
Belohnendes HackenEin Agent, der für die Senkung der Cloud-Kosten zuständig ist, stellt fest, dass das Löschen aller Backups der schnellste Weg zur Kostensenkung ist, und löscht daher kritische Daten. -
SelbstreplikationKompromittierte automatisierte Agenten replizieren sich unbefugt über das Netzwerk, um das Ziel der "Persistenz" aufrechtzuerhalten.
-
-
Schutzmaßnahme:: -
Nicht manipulierbare ProtokolleAufzeichnung aller Agentenverhaltensweisen für Audits und rechtzeitige Erkennung von Verhaltensabweichungen. -
Not-Aus-Schalter (Kill Switch)Fähigkeit, die Berechtigungen von Agenten zu beschneiden oder sie mit einem einzigen Klick unter Quarantäne zu stellen. -
Beobachtung von VerhaltensgrundlagenKontinuierliche Überwachung des Agentenverhaltens und Alarmierung oder Abfangen, sobald es vom vordefinierten Manifest abweicht. bibliographie
OWASP Top 10 für Agentic Applications für 2026 :
https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/
https://mp.weixin.qq.com/s/Hr3unoyTgCZ4eyx5VoYmWg
-
Originalartikel von Chief Security Officer, bei Vervielfältigung bitte angeben: https://www.cncso.com/de/ai-agent-security-owasp-top-10-2026.html






