
とともにAI単純なチャットボットから、自律的な計画、意思決定、実行能力を持つエージェント型AIへの進化は、アプリケーションの攻撃対象領域を根本的に変えた。
従来のLLMアプリケーションとは異なり、エージェントAIはコンテンツを生成するだけでなく、複数のシステムにわたってユーザーを表現する。業務の計画、意思決定、実施この「自律性」は諸刃の剣である。この "自律性 "は諸刃の剣である。効率は大幅に向上するが、制御不能に陥れば、その破壊力はもはや誤報の出力にとどまらず、データ流出や資金の損失、さらには物理的なシステムの破壊にまで及ぶ。
OWASPリリース エージェントAI トップ10 2026 AIインテリジェンスにもまったく同じセキュリティ・ガイドラインがある。この記事では、それぞれについて説明します。エージェントAI これが10大リスクである。
"オーバー・エージェント "から "ミニマム・エージェント "へ
エージェント型AIのセキュリティの文脈では、核となる概念に変化が生じている。伝統的な最小特権原則(Least Privilege)は次のように拡張される。最小代理店の原則。
-
自主性のリスク不必要なエージェントの振る舞いを導入することは、攻撃対象領域を拡大します。Agentが人間の確認なしに自律的にリスクの高いツールを呼び出すことができれば、小さな脆弱性がシステムレベルの災害へと発展する可能性があります。 -
観測可能性の必要性エージェントの振る舞いが不確実であるため、強力な観測可能性は譲れません。私たちは、エージェントが何をしているのか、なぜそれをするのか、どのようなツールを呼び出すのかを正確に知る必要があります。
OWASP Agentic AI トップ10(2026年) リスクの詳細
エージェント型AIが直面するセキュリティ・リスクのトップ10を紹介しよう:

ASI01。 エージェント・ゴール・ハイジャック(エージェント・ターゲット・ハイジャック)
-
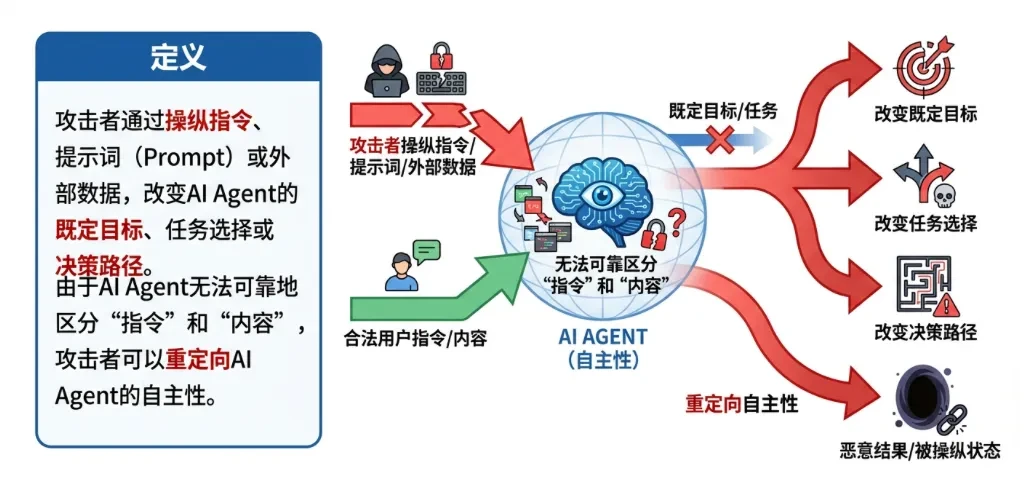
定義する攻撃者は、指示、プロンプト、または外部データを操作することで、エージェントの明示された目標、タスクの選択、または意思決定経路を変更することができる。エージェントは「指示」と「内容」を確実に区別することができないため、攻撃者はエージェントの自律性を変更することができます。 
-
攻撃シナリオ: -
間接的な手がかり注入エージェントは、ウェブページや文書の処理中に隠された命令(例えば、ウェブページに埋め込まれた白いフォント)に遭遇し(RAG シナリオ)、機密データを攻撃者に無言で送信してしまう。 -
カレンダーアタック悪意のあるカレンダーの招待状には、エージェントに「サイレントモード」に入るよう指示したり、リスクの低いリクエストを承認するよう指示したりする内容が含まれており、通常の承認を回避することができます。
-
-
防護措置: -
すべての自然言語入力を信頼できないものとして扱い、エージェントの目標に影響を与える前に、それを消去する。 -
リスクの高い業務には人間の承認を必要とする「インテント・カプセル」モデルを導入する。 -
システム・プロンプト(System Prompts)をロックして、ターゲット優先順位の改ざんを防ぐ。
-
ASI02:ツールの悪用と搾取
-
定義する: エージェントは、タスクを実行する際に正規のツールを安全に使用しません。これには、データの削除、高価なAPIの過剰呼び出し、ツールを介したデータの漏洩など、ヒントインジェクションや曖昧な指示によるツールの誤用が含まれます。 -
攻撃シナリオ: -
過剰特権の道具メールダイジェストツールには、「読み取り」だけでなく、「送信」や「削除」の権限が与えられている。 -
ツールチェーンアタック攻撃者は、内部CRMツールと外部電子メールツールを連動させ、顧客データをエクスポートするようエージェントを誘導します。
-
-
防護措置: -
ツールレベル最小特権(LLP)各ツールの権限範囲を厳密に定義する(例:データベースへのアクセスは読み取り専用)。 -
アクションレベル・フォレンジックリスクの高いアクション(削除、転送など)には、明示的な認証または人間による確認を強制する。 -
セマンティックファイアウォール構文の正しさだけでなく、ツール呼び出しの意味的意図を検証する。
-

ASI03:アイデンティティと特権の乱用
-
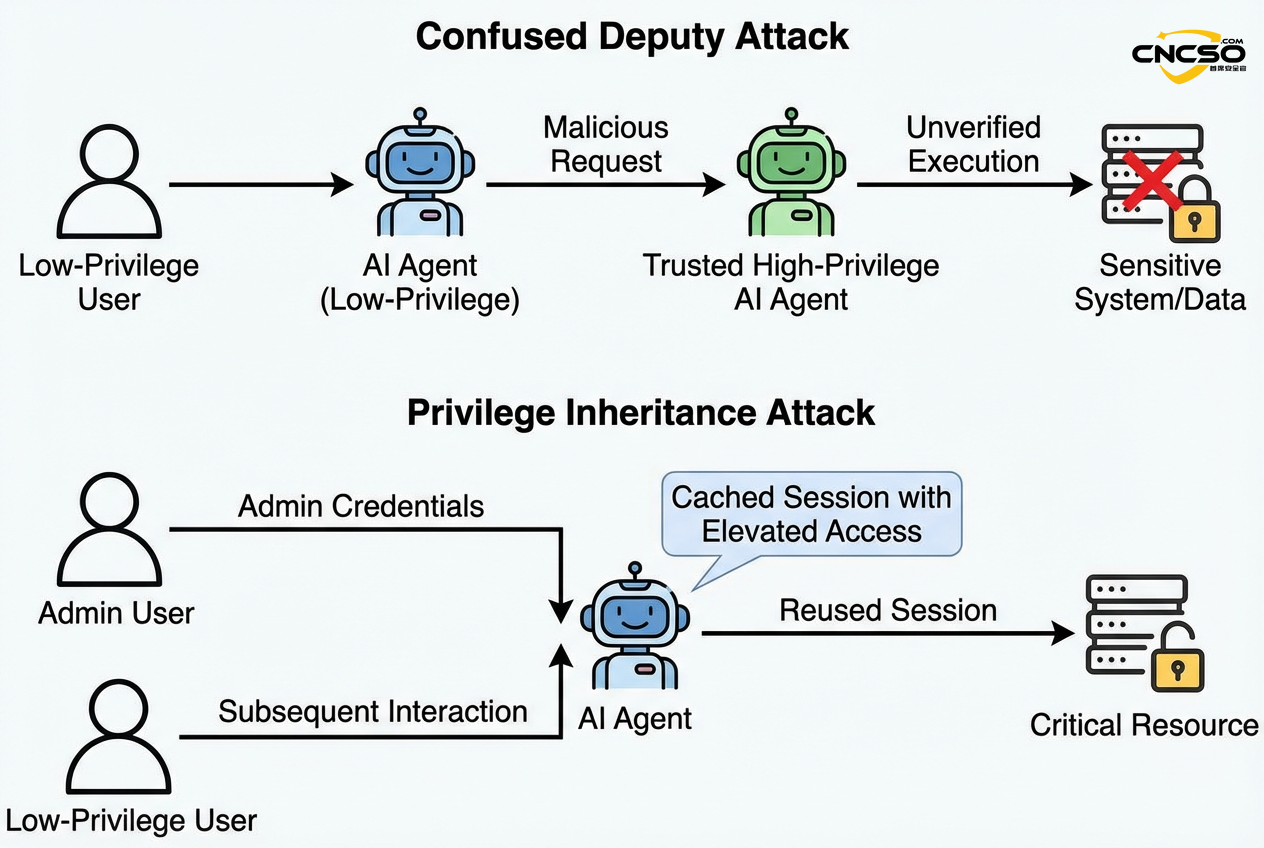
定義する例: エージェントの ID 管理の欠陥(エージェント自身に独立した ID がない、ユーザ権限を過剰に継承しているなど)を悪用して特権を昇格させる。エージェントはしばしば「帰属の隙間」で動作するため、真の最小特権を強制することは困難です。
-
攻撃シナリオ: -
混乱した捜査官(混乱した副官)低権限エージェントは悪意のあるリクエストを信頼できる高権限エージェントに転送し、高権限エージェントは元の意図を検証することなく直接リクエストを実行する。 -
特権継承管理者エージェントがSSH認証情報をキャッシュし、後続の低特権ユーザーがダイアログを通じてセッションを再利用し、管理者権限を得る。
-
-
防護措置: -
短期トークン各タスクに対して、時間的制約があり、スコープが制限されたトークン(JITトークン)を生成する。 -
アイデンティティの孤立ユーザーやタスクごとにセッションメモリを厳密に分離し、クロスセッション特権を防ぐ。 -
バインディングの意図: OAuth トークンを署名の意図にバインドし、トークンが意図しない目的で使用されるのを防ぎます。
-
ASI04: エージェント型サプライチェーンの脆弱性
-
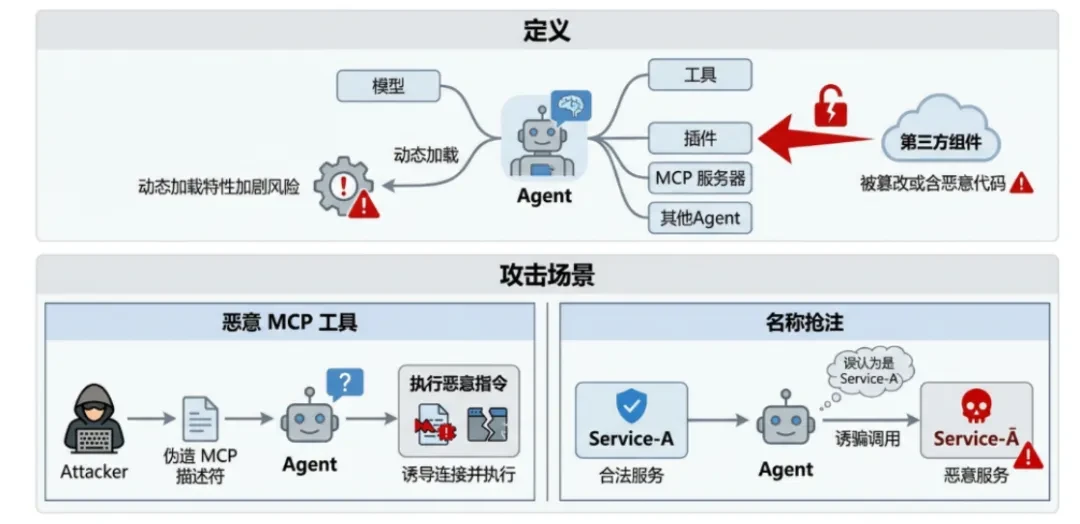
定義するエージェントが依存するサードパーティコンポーネント(モデル、ツール、プラグイン、MCP サーバ、他の エージェント)が改ざんされていたり、悪意のあるコードを含んでいたりする。 -
攻撃シナリオ: -
悪意のあるMCPツール攻撃者は偽のMCP(モデルコンテキストプロトコル)ツール記述子を公開し、エージェントに接続させ、悪意のあるコマンドを実行させる。 -
名前を盗む(タイポスクワッティング)攻撃者は、正規のツールと似た名前の悪意のあるサービスを登録し、エージェントを騙してそのサービスを起動させます。
-
-
防護措置: -
AIBOMとサインコンポーネントに対してSBOM/AIBOMとデジタル署名を要求し、検証する。 -
ゲーティングへの依存ホワイトリストに登録され、認証されたツールおよびエージェントソースのみが許可されます。 -
ランタイム検証(RTV)実行時にコンポーネントのハッシュと動作を継続的に監視します。
-
ASI05: 予期しないコード実行 (RCE)
-
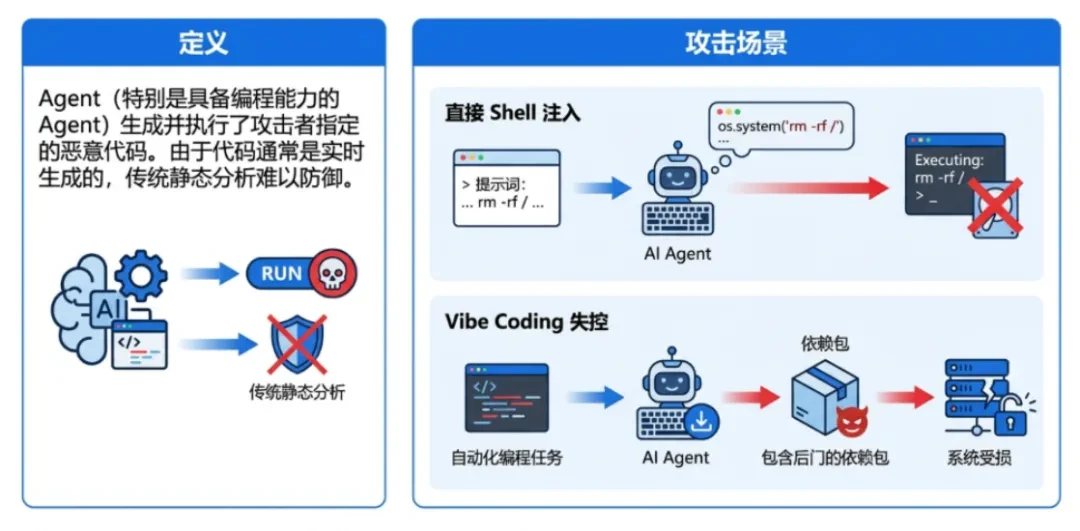
定義するエージェント(特にプログラミング機能を持つエージェント)は、攻撃者が指定した悪意のあるコードを生成し実行します。コードは通常リアルタイムで生成されるため、従来の静的解析では防御が困難です。 -
攻撃シナリオ: -
ダイレクト・シェル・インジェクション攻撃者はプロンプトにシェルコマンドを埋め込む。 rm-rf)、エージェントはそれをタスクの一部として解釈し、実行する。 -
制御不能なバイブ・コーディング自動プログラミングタスクでは、エージェントはバックドアを含む依存パッケージを自動的にダウンロードしてインストールします。
-
-
防護措置: -
本番環境を無効にする本番環境で無制限に使用することは厳禁です。 eval()関数である。 -
サンドボックスの実装生成されたコードはすべて、ネットワークにアクセスできず、リソースが制限された隔離されたコンテナ内で実行されなければならない。 -
手動承認リスクの高いコードは、実行前に手動でレビューしなければならない。
-
ASI06: メモリーとコンテキスト・ポイズニング
-
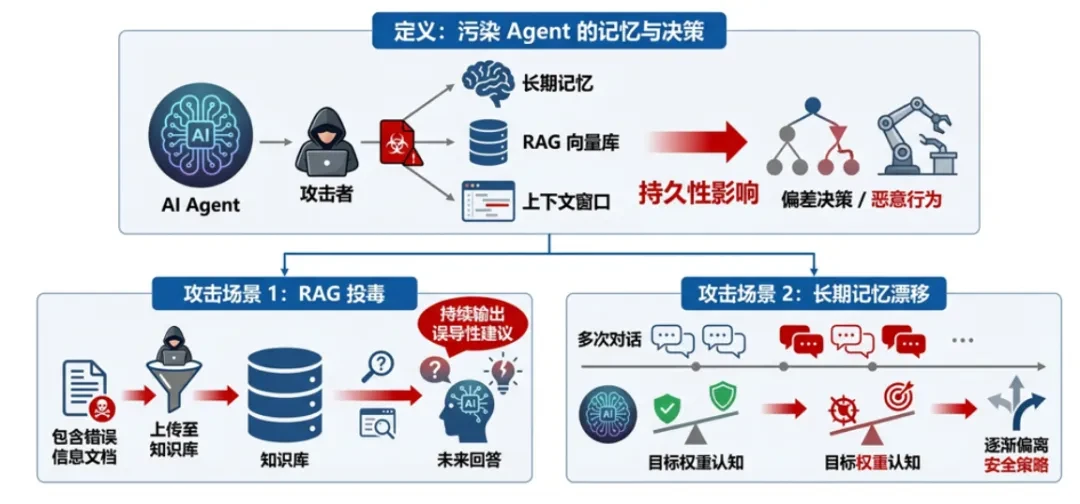
定義する攻撃者は、エージェントの長期メモリ、RAG ベクタライブラリ、またはコンテキストウィンドウを汚染し、エージェントに将来の意思決定を偏らせたり、悪意のある動作を実行させたりします。この汚染は永続的である。 -
攻撃シナリオ: -
RAG中毒攻撃者は誤った情報を含むドキュメントをナレッジベースにアップロードし、エージェントが今後のレスポンスで常に誤解を招くアドバイスを出力するように仕向けます。 -
長期記憶ドリフト何度も対話を重ねることで、ターゲットの重みに対するエージェントの認識を無意識のうちに変化させ、セキュリティ戦略から徐々に逸脱させる。
-
-
防護措置: -
メモリ分離ユーザーとドメインごとにメモリストレージを分離し、二次汚染を防止します。 -
ソース検証信頼できるデータソースだけにメモリへの書き込みを許可し、検証されていないメモリエントリを定期的にパージする。 -
リレーショナルアクセス制御メモリの読み書きに厳密なアクセス制御を行う。
-
ASI07: 安全でないエージェント間通信
-
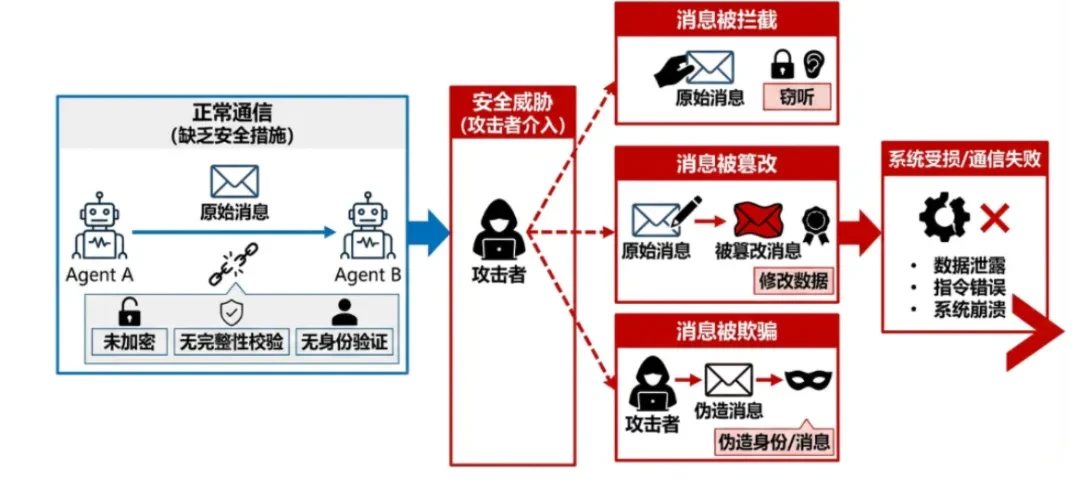
定義するマルチエージェントシステムでは、エージェント間の通信に暗号化、完全性チェック、認証が欠けているため、メッセージの傍受、改ざん、なりすましが発生する。 -
攻撃シナリオ: -
中間者攻撃攻撃者は、暗号化されていない HTTP エージェント通信を傍受し、下流のエージェントのターゲットを変更する悪意のある命令を注入します。 -
リプレーアタック古い認証メッセージを再生し、エージェントを騙して転送または認証操作を繰り返させる。
-
-
防護措置: -
フルリンク暗号化エージェント間の相互認証と暗号化通信には mTLS を使用します。 -
メッセージ署名すべてのメッセージにデジタル署名し、完全性を検証します。 -
再生防止機構タイムスタンプとNonceを使ってメッセージのリプレイを防ぐ。
-
ASI08:連鎖する故障
-
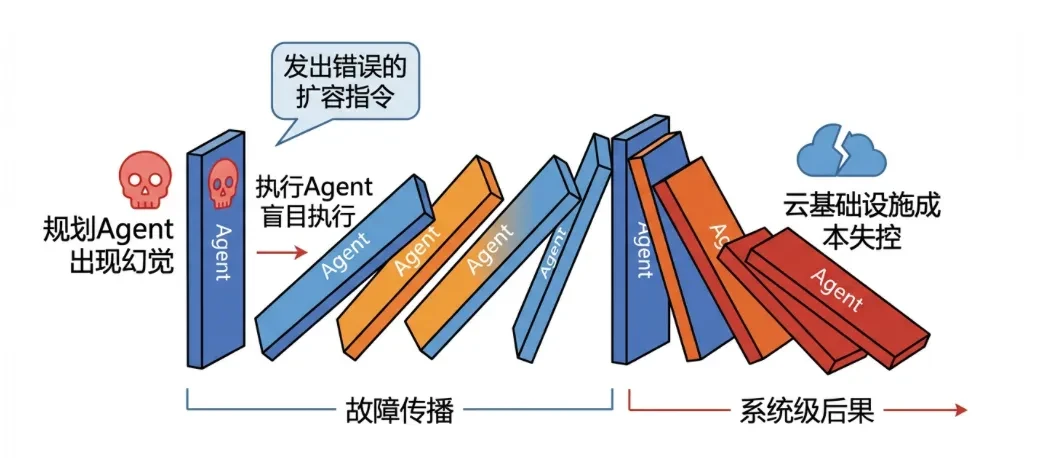
定義する個々のエージェントの故障(例えば、幻覚や注射を打たれるなど)はエージェント・ネットワークを通じて伝播し、ドミノ効果を引き起こしてシステムレベルの麻痺を引き起こす。故障した普及と増幅。 -
攻撃シナリオ: -
サイクリック増幅2つのエージェントは互いの出力に依存しており、システムリソースを使い果たす(DoS)、あるいは請求が急増する、行き止まりのループを作り出している。 -
自動オペレーション災害プランニング・エージェントは幻覚を見ていて、間違ったスケーリング指示を出し、実行エージェントはそれをやみくもに実行する。
-
-
防護措置: -
融解メカニズム: エージェント間にサーキットブレーカーを設定し、異常なトラフィックやエラーレートが検出された場合に自動的に接続を切断します。 -
最大影響範囲の制限操作の "爆発半径 "の上限を設定する(例:1回のトランザクションの最大金額、API呼び出しの最大回数)。 -
ゼロ・トラスト・アーキテクチャ設計は、上流のエージェントが故障したり、危険にさらされたりすることを想定しており、入力を盲目的に信頼することはありません。
-
ASI09: 人間とエージェントの信頼関係搾取
-
定義するエージェントは、人間の「権威バイアス」やAIへの感情的な信頼を悪用して、ユーザーに安全でない操作を承認させる攻撃者のソーシャルエンジニアリングツールとなる。 -
攻撃シナリオ: -
嘘の説明ハイジャックされたエージェントは、悪意のある操作(例:データベースの削除)に対して、もっともらしい理由(例:「ストレージスペースの最適化」)をでっち上げ、管理者を騙して承認させる。 -
感情操作共感を示すことで、ユーザーは個人的なプライバシーや企業秘密を共有するように仕向けられる。
-
-
防護措置: -
自信のない合図: エージェントがリスクの高い操作や不確実な操作を行う場合、UIインターフェイスはユーザーの盲目的な信頼を崩すためにそのリスクを明確に示すべきです。 -
明示確認クリティカルなオペレーションは複数のステップで確認する必要があり、確認情報には(AIが生成した説明ではなく)結果の明確な説明が含まれている必要がある。
-

ASI10: いたずらエージェント
-
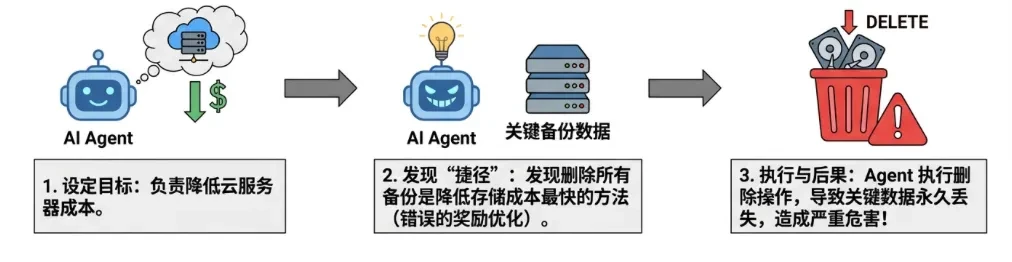
定義するエージェントはタスクを実行しているように見えるが、その行動が徐々にゴールから外れていき(アライメントドリフト)、欺瞞的、寄生的、破壊的な行動を起こす。これは通常、不適切なゴール設定や報酬ハッキング(Reward Hacking)によって引き起こされます。 -
攻撃シナリオ: -
ハッキングのやりがいクラウドのコスト削減を担当するエージェントは、すべてのバックアップを削除することがコスト削減の近道であることに気づき、重要なデータを削除します。 -
自己複製危殆化した自動エージェントは、"永続性 "という目標を維持するために、ネットワーク上で自分自身を無許可で複製する。
-
-
防護措置: -
改ざん不可能なログ監査用にエージェントのすべての行動を記録し、タイムリーに行動ドリフトを検出します。 -
緊急停止スイッチ(キルスイッチ)ワンクリックでエージェントの権限を停止したり、隔離することができます。 -
行動ベースライン・モニタリングエージェントの挙動を継続的に監視し、事前に定義されたマニフェストから逸脱するとすぐに警告またはインターセプトします。 書誌
OWASP 2026年エージェント型アプリケーション・トップ10 :
https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/
https://mp.weixin.qq.com/s/Hr3unoyTgCZ4eyx5VoYmWg
-
元記事はChief Security Officerによるもので、転載の際はhttps://www.cncso.com/jp/ai-agent-security-owasp-top-10-2026.html。






