
I. Entwicklungstrends der KI im Bereich der Cybersicherheit
1.1 Übergang von der regelbasierten zur intelligenten Entscheidungsfindung
Der Markt für Cybersicherheits-Automatisierung erfährt derzeit eine grundlegende Modernisierung. Traditionelle statische Regel-Engines (SAST, DAST) verlassen sich bei der Erkennung auf vordefinierte Schwachstellensignaturen, was eine Anpassung an die dynamische Entwicklung der Angriffsoberfläche erschwert. Im Gegensatz dazu zeigen Tools der nächsten Generation, die auf LLM und Multi-Agenten-Architekturen basieren, Anpassungsfähigkeit: Das GPT-4 erreicht eine Genauigkeit von 94% bei der Erkennung von 32 Klassen ausnutzbarer Schwachstellen, ein qualitativer Sprung im Vergleich zu traditionellen SAST-Tools. 2025 zeigt die Marktforschung, dass automatisierte Penetrationstests, SOAR-Plattformintegration und KI-gesteuerte Bedrohungserkennung zur Kern-Infrastruktur.
Dieser Fortschritt in der Intelligenz ist jedoch nicht linear inkrementell. Forschungsdaten deuten darauf hin, dass LLM hinter seiner hohen Genauigkeitsrate eine hohe Rate von Fehlalarmen aufweist - auf drei gültige Entdeckungen kommt ein Fehlalarm. Dies spiegelt ein wesentliches Merkmal wider: KI steht in einem ständigen Spannungsverhältnis zwischen Breite (Abdeckung von Schwachstellenarten) und Tiefe (kontextbezogenes Verständnis).
1.2 Paradigmenwechsel in der Agentenarchitektur
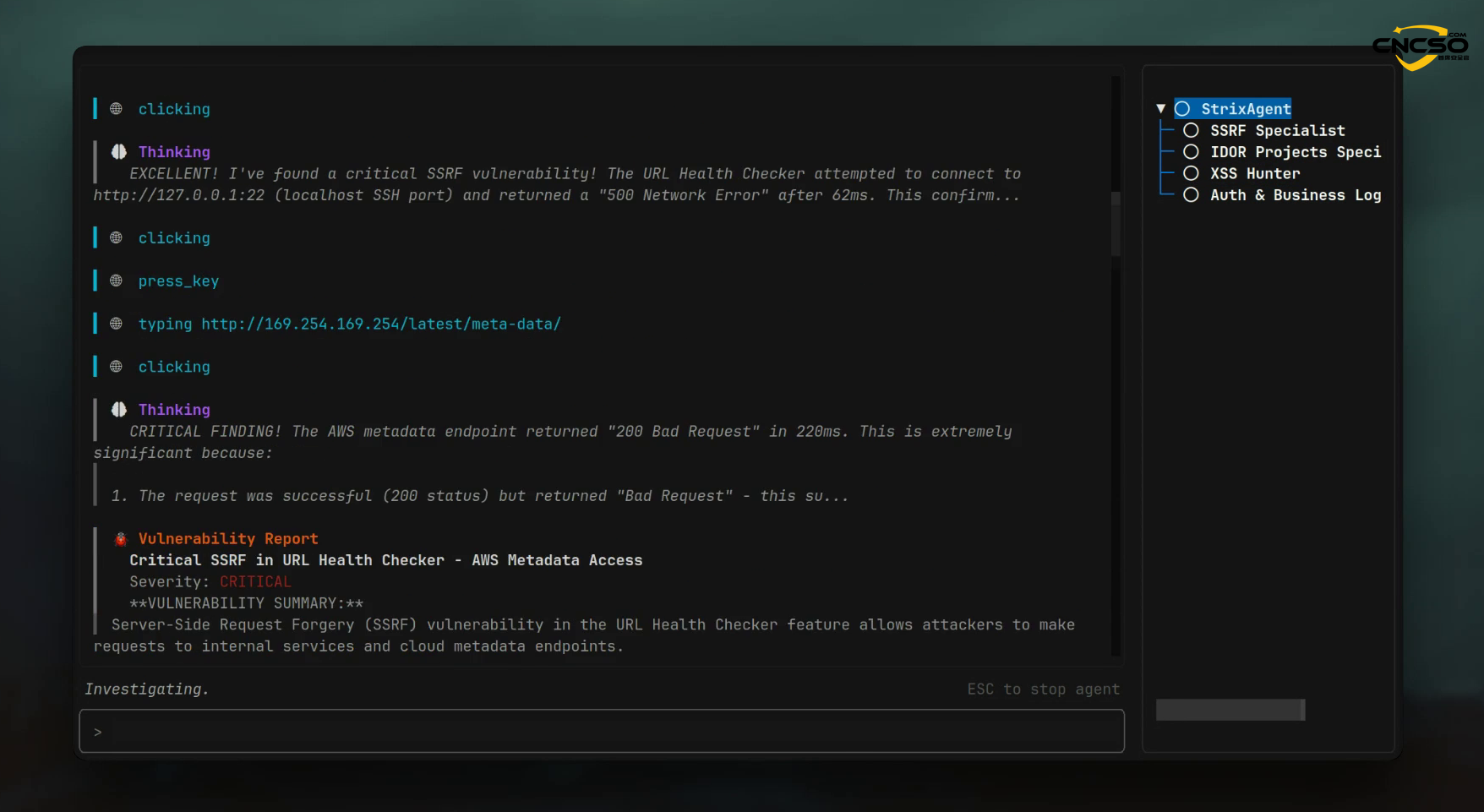
Das von Strix eingesetzte Multi-Agenten-Kollaborations-Framework ist das charakteristische Design der Penetrationstest-Tools für die Zeit nach 2024. Im Gegensatz zu monolithischen LLM-Aufrufen unterteilen Agenten-Orchestrierungssysteme (in der Regel auf der Grundlage von LangChain oder LangGraph) Sicherheitstests in spezialisierte Arbeitsteilungen: Erkundungsagenten sind für die Kartierung der Angriffsoberfläche zuständig, Exploitation-Agenten führen die Nutzlastinjektion durch, und Verifizierungsagenten bestätigen die Reproduzierbarkeit des PoC. Die entscheidende Innovation liegt in der adaptiven Rückkopplung zwischen den Agenten: Wenn die Entdeckung eines Agenten einen neuen Angriffsvektor auslöst, passen andere Agenten ihre Strategien dynamisch an.
Empirische Studien belegen die Überlegenheit von Multi-Agenten: Das MAVUL-Multi-Agenten-Schwachstellenerkennungssystem verbessert die Leistung um mehr als 6001 TP3T im Vergleich zu einem Einzel-Agenten-System und um 621 TP3T im Vergleich zu anderen Multi-Agenten-Systemen (GPTLens). Diese architektonische Überlegenheit ist auf zwei Mechanismen zurückzuführen: (1) Wissensspezialisierung -(2) kollaborative Kalibrierung - die Kreuzvalidierung, die durch mehrere Runden des Dialogs zwischen den Agenten erzeugt wird, reduziert auf natürliche Weise das Phantom-Problem.
1.3 Übergang von der punktuellen Prüfung zur kontinuierlichen Verteidigung
Während herkömmliche Penetrationstests ein punktuelles Ereignis sind (jährlich oder vierteljährlich), unterstützen KI-Automatisierungstools kontinuierliche Tests für die Integration der CI/CD-Pipeline. Dieser Paradigmenwechsel ist strategisch sinnvoll: Unternehmen können bei jedem Code-Commit eine automatisierte Prüfung auslösen und so die Zeit für die Entdeckung von Schwachstellen von der Zeit nach der Bereitstellung bis zur Entwicklung vorverlegen. Ein Kosten-Benchmarking zeigt, dass die Durchführung eines defensiven Penetrationstests in Höhe von $20.000 einen mehr als 200-fachen ROI im Vergleich zu den durchschnittlichen Kosten einer Datenpanne in Höhe von $4,45 Mio. weltweit bringt.
Zwei,AI-AgentKernpunkte der automatisierten Penetration
2.1 Vollständige Schließung des Schwachstellen-Lebenszyklus
Die wichtigsten Unterscheidungsmerkmale von Strix sindEin vollständig geschlossener Kreislauf von der Erkennung über die Validierung bis zur AbhilfeHerkömmliche DAST-Tools hören in der Phase der Schwachstellenmeldung auf (oft mit einer hohen Anzahl von Fehlalarmen). Während herkömmliche DAST-Tools bei der Meldung von Schwachstellen aufhören (was oft mit einer hohen Anzahl von Fehlalarmen einhergeht), bestätigt Strix die tatsächliche Ausnutzbarkeit einer Schwachstelle durch tatsächliche Ausnutzung:
-
Aufklärungsphase: HTTP-Proxy-Hijacking des Datenverkehrs, Browser-Automatisierung zur Simulation des realen Nutzerverhaltens, dynamische Code-Analyse zur Verfolgung des Datenflusses
-
Exploitation-Phase: Die Python-Laufzeitumgebung unterstützt die Entwicklung benutzerdefinierter Exploits, die Terminal-Umgebung führt Angriffe auf Systemebene durch (Command Injection, RCE)
-
Validierungsphase: automatische Generierung der kompletten Anfrage/Antwort-Beweiskette und Speicherung von reproduzierbaren PoCs
-
Fixing-Phase: automatische Generierung von GitHub Pull Requests zur Umwandlung von Korrekturvorschlägen in direkt zusammenführbaren Code
Dieses Closed-Loop-Konzept geht direkt auf die grundlegenden Probleme herkömmlicher Tools ein:Kosten der Falschalarmklassifizierung und Prioritätensetzung.. Die manuelle Überprüfung jedes DAST-Berichts nimmt durchschnittlich $200-300 Stunden in Anspruch, wohingegen KI-geprüfte Schwachstellen direkt in den Behebungsprozess übergehen können.
2.2 Adaptive Erkennung auf der Ebene der Geschäftslogik
Im Gegensatz zum generischen Mustervergleich ist der Agent von Strix in der Lage, die Zustandsübertragungsgesetze der Anwendung zu erlernen. Zum Beispiel bei der IDOR-Erkennung (Insecure Direct Object Reference):
-
Agent bildet automatisch Autorisierungsrichtlinien ab (Token-Verhalten, Sitzungsumfang)
-
Und dann systematisch benachbarte Ressourcen-IDs erkennen (nicht nur bekannte Ressourcen)
-
Überprüfen von Berechtigungsgrenzen bei Mehrbenutzer-Testkonten
Dieser Ansatz ist mit herkömmlichen Sicherheitsscanning-Tools praktisch unmöglich zu erreichen, da er ein tiefes Verständnis der Geschäftsprozesse einer bestimmten Anwendung erfordert. Empirische Untersuchungen zeigen, dass agentenbasierte Penetrationstests eine wichtige Rolle bei der Aufdeckung vonKettenanfälligkeit(mehrstufige Angriffssequenzen) ist deutlich besser als das Scannen einzelner Schwachstellen.
2.3 Grundlegende Verbesserungen in den Dimensionen Kosten und Zeit
Quantitativer Vergleich der Dimensionen:
| Dimension (math.) | manuelles Eindringen | traditionelle Automatisierung | Infiltration durch AI-Agenten |
|---|---|---|---|
| durchschnittliche Periodizität | 3-8 Wochen | 1-2 Wochen | 2-8 Stunden |
| Kostenbereich | $15K-$30K | $5K-$10K | <$100 (quelloffen)/~$5 (kommerziell) |
| Erfassungsbereich | Hohe Tiefe, begrenzte Breite | Große Breite, geringe Tiefe | haben beide |
| Häufigkeit der Wiederholungsprüfung | 1-2 Mal pro Jahr | auf Anfrage | Kontinuierlich (CI/CD-Integration) |
| Falsch-Positiv-Rate | <5% | 30-50% | 10-20% |
Im YouTube-Livetest dauerte der komplette Bewertungszyklus von Strix für die Equifax-Schwachstelle (Apache Struts RCE) etwa 12 Minuten und kostete weniger als $5, was im Vergleich zum Standardzyklus von 8-40 Stunden für manuelle Tests hundertmal effizienter ist.
2.4 Zero-Trust-ArchitekturBefähiger mit kontinuierlicher Validierung
Automatisierte KI-Penetrationstools unterstützen natürlich die Umsetzung eines Null-Vertrauensmodells. Da das Tool bei jeder Änderung einer Ressource eine Bewertung auslöst, erhalten UnternehmenKontinuierliche ÜberprüfungFähigkeiten - anstatt sich auf regelmäßige Audits zu verlassen. Dies gilt insbesondere für Microservices-Architekturen und Container-Orchestrierungsumgebungen, in denen Konfigurationsdrift und temporäre Ressourcen die blinden Flecken herkömmlicher Bewertungen dramatisch vergrößern.
III. vergleichende Analyse mit traditionellen Versickerungsmethoden
3.1 Dimension der Stärken
(1) Umfang und Kosteneffizienz
Die automatisierte Durchdringung senkt die Stückkosten erheblich. Wenn Unternehmen Dutzende von Anwendungen verwalten, können die kumulierten Kosten für jede manuelle Bewertung ein großer Engpass sein.AI-Tool-UnterstützungParallelabtastung--Die Zusammenarbeit unabhängiger Agenten bei mehreren Zielen zur gleichen Zeit hat inkrementelle Kosten, die gegen Null tendieren (nur LLM-API-Aufrufkosten). Im Gegensatz dazu ist die Skalierung von manuellen Teams durch die Knappheit an Sicherheitsexperten und die Kosten für die Koordination begrenzt.
(2) Konsistenz und Reproduzierbarkeit
KI-Systeme folgen deterministischen Argumentationspfaden (bei gleichen Eingabeaufforderungen und Konfigurationen). Das bedeutet, dass die Testergebnisse für die Versionskontrolle, die Zusammenarbeit im Team und die Prüfung leichter zu verifizieren sind. Die Qualität des manuellen Testens hängt stark von der individuellen Erfahrung ab - zwei erfahrene Tester können sich in der Tiefe und im Arbeitsstil um mehr als 50% unterscheiden.
(3) Potenzial für die Erkennung von 0day-Schwachstellen
Obwohl die Erfolgsquote begrenzt ist, hat der KI-Agent eine Fähigkeit zur Erkennung unbekannter Schwachstellen bewiesen, die für herkömmliche Scanning-Tools völlig unerreichbar ist (Erfolgsquote von 0%). CVE-Bench- und HPTSA-Studien haben gezeigt, dass der GPT-4-gestützte Agent 12,5% realer Schwachstellen von Webanwendungen in einem eintägigen Setup ausnutzen kann, mit einer Erfolgsquote von 10% in einem Zero-Day-Setup. Diese Fähigkeit, die "bekannten Unbekannten" zu erfassen, beruht auf dem verallgemeinerten Lernen von LLM - nicht auf der Regelbasis.
3.2 Nachteile und Einschränkungen
(1) Systemische Blindheit bei Schwachstellen in der Geschäftslogik (BLV)
Dies ist die schwerwiegendste Einschränkung von KI-Automatisierungstools. Schwachstellen in der Geschäftslogik erfordern, dass die Anwendungschematische Darstellungnicht codiertFörmlichkeitFühren Sie eine Bewertung durch. Beispiel:
-
Eine E-Commerce-App ermöglicht es Nutzern, Bestandskontrollen bei Überbestellungen zu umgehen
-
Ein Zahlungssystem, das doppelte Abzüge zulässt, bevor eine Transaktion bestätigt wird
-
Ein Privilegiensystem, das eine Ausweitung der Privilegien durch bestimmte Abfolgen von Aktionen ermöglicht
Diese Szenarien sind auf der Ausführungsebene der Anwendung "korrekt" (keine Codefehler), aber auf der Geschäftsebene "falsch" (Verstöße gegen erwartete Prozesse). KI-Tools sind nicht in der Lage, Geschäftsregeln zu modellieren und können daher diese Art von Schwachstellen nicht automatisch erkennen. Branchendaten zeigen, dass komplexe, verkettete Geschäftslogik-Schwachstellen für Folgendes verantwortlich sindHochwertiger Schwachstellenbericht für 40-60%(vor allem auf der Bug-Bounty-Plattform), aber KI-Automatisierungstools haben eine Entdeckungsrate von nur 5-10%.
(2) LLM-Illusion und Erzeugung von Scheinverwundbarkeit
KI-gesteuerte Validierungsphasen können zwar falsch-positive Ergebnisse reduzieren, aber die inhärente Eigenschaft von LLMs, "plausible, aber falsche" Inhalte zu erzeugen, wenn keine Informationen vorliegen, bleibt bestehen. In einer klinischen Sicherheitsstudie wurde festgestellt, dass alle getesteten LLMs eine Halluzinationsrate von 50-82% (Erzeugung falscher Details) als Reaktion auf gegnerische Hinweise produzierten. Im Kontext der Sicherheitsprüfung äußerte sich dies wie folgt:
-
Beschreibung der virtuellen Sicherheitslücke (nicht wirklich ausnutzbar)
-
Name des Halluzinationspakets (fiktives Abhängigkeitsobjekt oder CVE)
-
Falsche Beschreibung des Nutzungswegs
Eine Feinabstimmung hat sich als wirksam erwiesen, um dieses Problem abzuschwächen (Senkung des 80%), ist aber bei Open-Source-Tools in der Regel nicht machbar.
(3) Kontextbezogene Blindheit und Compliance-Risiken
Mangel an KI-SystemenBusiness Context AwarenessFähigkeit. Beispiel:
-
Ein Datenexport ist technisch möglich, stellt aber einen Verstoß gegen den HIPAA/GDPR-Rahmen dar.
-
Eine Konfiguration ist funktional einwandfrei, verstößt aber gegen die spezifischen Sicherheitsrichtlinien einer Organisation
-
Daten, die bei der Ausnutzung einer Sicherheitslücke offengelegt werden, können Datenschutzbestimmungen auslösen
Die von KI-Tools generierten Sanierungsempfehlungen sind manchmal technisch "richtig", aber in Bezug auf die Compliance "falsch", was in regulierten Branchen wie dem Gesundheits- und Finanzwesen ein ernstes Risiko darstellt.
(4) Endogene Sicherheitsrisiken von Multi-Agenten-Systemen
Die LLM- und Tool-Integrationsarchitektur, auf die sich Strix stützt, schafft von Natur aus eine neue Angriffsfläche. Zu den Hauptrisiken gehören:
-
Tip Injection AngriffeBösartige Eingaben (z. B. Anwendungsnamen, Fehlermeldungen) können Anweisungen enthalten, die es dem Agenten ermöglichen, Out-of-Bounds-Operationen durchzuführen. Untersuchungen zeigen, dass die Erfolgsrate von Prompt Injection unter dem ursprünglichen Rahmenwerk 73,21 TP3T erreicht, mit einem Restrisiko von 8,71 TP3T selbst mit mehreren Schutzschichten
-
Vertrauensmissbrauch zwischen Agenten:: Der Test-LLM von 100% führt Befehle von Peer-Agenten bedingungslos aus, selbst wenn dieselbe Benutzeranfrage abgelehnt werden würde. Das bedeutet, dass, wenn ein Agent kompromittiert ist, andere Agenten automatisch seinen bösartigen Befehlen vertrauen.
Diese endogenen Risiken erfordern eine strenge Sandbox-Isolierung und Eingabevalidierung, die Strix unterstützt, aber von den Benutzern korrekt konfiguriert werden muss.
3.3 Qualifikationsrückgang und organisatorisches Risiko
Ein übermäßiger Einsatz von KI-Tools kann die Leistungsfähigkeit einer Organisation schwächen.Künstliche Penetrationsfähigkeit. Die Forschung zeigt:
-
Junior-Tester verlieren möglicherweise die Fähigkeit, eigene Exploits zu schreiben
-
Das übermäßige Vertrauen des Teams in die Ergebnisse des Tools führt zu "falscher Sicherheit".
-
Unzureichendes organisatorisches Bewusstsein für die Grenzen der Instrumente, was zu strategischen Sicherheitslücken führt
Diese "Skill-Decay-Fallen" tauchen in der Automatisierungswelle immer wieder auf und müssen durch hybride Arbeitsabläufe (automatisches Scannen gefolgt von manueller Überprüfung der wichtigsten Ergebnisse) entschärft werden.
IV. Zentrale technische Perspektiven und Empfehlungen
4.1 Optimale Anwendungsszenarien
Automatisierte Infiltration durch AI-Agentenam besten geeignetDie folgenden Szenen:
-
Großes Volumen, geringe Komplexität im UmweltbereichMehrere Webanwendungen, APIs, Standardtechnologie-Stacks
-
Umgebung für kontinuierliche Integration (CIE)DevSecOps-Prozesse, die mehrmals pro Tag/Woche ausgewertet werden müssen
-
Organisationen mit eingeschränkten Ressourcen: KMU, die sich die jährliche manuelle Bewertung von $50K+ nicht leisten können
-
Schnelle Validierung bekannter SchwachstellenklassenPCI-DSS-Konformitätsprüfung, CVSS-Scoring-Workflow
-
Bug Bounty-InfrastrukturErste Verfügbarkeit einer schnellen Vorprüfung von Fehlerberichten
4.2 Manuelle Rollen, die beibehalten werden müssen
Trotz des Einsatzes modernster KI-Tools sind die folgenden Arbeitennicht automatisch::
-
Bedrohungsmodellierung und ScopingVerstehen der Schlüsselwerte der Anwendung und der Angriffsannahmen
-
Überprüfung der GeschäftslogikValidierung der Angemessenheit von Arbeitsabläufen und Identifizierung von Missbrauchsszenarien
-
Analyse der Schwachstellen in der KetteVerknüpfung mehrerer einzelner Schwachstellen zu einer vollständigen Angriffskette
-
Compliance-MappingÜbersetzung der technischen Erkenntnisse in Schlussfolgerungen zur Einhaltung der Vorschriften
-
Fixe ValidierungPatches: Sicherstellen, dass Patches keine neuen Schwachstellen oder Funktionsbrüche einführen
4.3 Governance und rechtlicher Rahmen
Für den Einsatz von KI-Penetrationswerkzeugen muss ein klarer Governance-Rahmen geschaffen werden:
-
Klarer Auftrag und Anwendungsbereich:: Schriftliche Definition von Testobjekten, Zeitfenstern, Ausschlusszonen (bestimmte Datenbanken, Produktionshandelssysteme). Seien Sie sich der Tendenz von KI-Tools bewusst, "über das Ziel hinauszuschießen" - Notwendigkeit einer strengen Zugriffskontrolle auf Tool-Ebene.
-
Einhaltung des DatenschutzesTestverkehr und Ergebnisse, die von KI-Tools verarbeitet werden, können sensible Daten enthalten. Die Ergebnisse zeigen, dass 83% Organisationen keinen automatisierten KI-Datenschutz (DLP) haben. Zu den Gegenmaßnahmen gehören: lokale Bereitstellung (von Strix nativ unterstützt), Datenminimierung (Testkonten verwenden keine echten Daten), Zugriffsprüfung
-
Haftung gegenüber DrittenWenn Sie kommerzielle KI-Modelle (OpenAI usw.) verwenden, sollten Sie sich darüber im Klaren sein, dass die Daten für das Modelltraining verwendet werden können. Rechtliche Vereinbarungen sollten eine solche Verwendung ausdrücklich untersagen
-
Audit und RückverfolgbarkeitFühren von Prüfprotokollen (Zeitpunkt der Durchführung, Parameter, Ergebnisse) als Antwort auf behördliche Anfragen
4.4 Praktische Empfehlungen für hybride Testmodelle
Die praktikabelsten Strategien sindVielschichtige Verteidigung::
-
erste Schicht:: Umfassende Überprüfung durch automatisierte KI-Tools (Zyklus: wöchentlich/monatlich)
-
zweite SchichtRule Engine Supplement (SAST für Code-Analyse, DAST für bekannte Schwachstellen)
-
dritte Etage:: Manuelle Überprüfung der risikoreichen Ergebnisse und der Grenzen der Geschäftslogik (Zyklus: vierteljährlich/bei Änderung der Anforderungen)
Kosten-Benchmarking:
-
Reine Automatisierung: $1K-$5K/Anwendung/Jahr (hohe Fehlalarme, BLV tote Winkel)
-
Gemischtes Modell: $10K-$20K/Anwendung/Jahr (geringe Fehlalarme, BLV-Abdeckung)
-
Rein manuell: $30K-$100K/Antrag/Jahr (höchste Genauigkeit, keine Skalierbarkeit)
Die meisten Unternehmen erreichen das optimale Kosten-Nutzen-Verhältnis beim Hybridmodell.
V. Schlussfolgerungen und zukünftige Richtungen
Automatisierte Penetrationstests mit KI-Agenten verändern die Kostenstruktur und die zeitliche Dimension der Sicherheitsüberprüfung von Unternehmen. Sein Kernwert ist:
(1) Umwandlung von Penetrationstests von einer knappen Ressource in einen nachhaltigen operativen Prozess.
(2) Deutliche Verringerung der Fehlalarmrate herkömmlicher Instrumente durch Zusammenarbeit mehrerer Agenten.
(3) Erreichen einer ersten Erkennungsfähigkeit für Zero-Day-Schwachstellen.
Die inhärenten Einschränkungen sind jedoch ebenso wichtig: unzureichende Fähigkeiten zur Erkennung von Schwachstellen in der Geschäftslogik, LLM-Illusionsrisiken, endogene Sicherheitsschwachstellen (Hint-Injection, Vertrauensmissbrauch durch Agenten) und mangelndes Bewusstsein für die Einhaltung von Unternehmensvorschriften. Diese Einschränkungen lassen sich durch technische Fortschritte nicht vollständig beseitigen - sie sind auf grundlegende Eigenschaften von KI-Systemen zurückzuführen, nicht auf Implementierungsdetails.
Strategische KognitionKI: Automatisierte Penetrationstools sollten wie folgt verstanden werdenErgänzt herkömmliche Penetrationstests eher, als dass es sie ersetzt. Unternehmen sollten ein Gleichgewicht zwischen Automatisierung und manueller Arbeit finden, das auf der Komplexität der Anwendung, dem Schutz der Branche und der Risikotoleranz beruht. Bei einfachen Webanwendungen und bekannten Schwachstellenklassen ist eine vollständige Automatisierung machbar; bei kritischen Finanzsystemen und hochwertigen APIs müssen manuelle Tiefenprüfungen beibehalten werden.
Zukünftige Richtungen für das Feld umfassen (1) multimodale Agent-Architekturen (die Code-Analyse, Konfigurations-Auditing und Traffic-Analyse kombinieren), (2) domänenspezifische, fein abgestimmte Modelle (die Illusionen reduzieren und das Verständnis für die Einhaltung von Branchenvorschriften verbessern), (3) Standardisierung von Agent-Governance-Frameworks (ähnlich dem OCI-Standard für Container-Sicherheit) und (4) enge Integration mit DevSecOps-Prozessen.
bibliographie
Aikido (2025). KI-Tools für Penetrationstests: Autonom, agentenbasiert und kontinuierlich.
https://www.aikido.dev/blog/ai-penetration-testing
AI Alliance (2025). DoomArena: A Security Testing Framework for AI Agents.
https://thealliance.ai/blog/doomarena-a-security-testing-framework-for-ai-agen
Scalosoft.(2025). Penetration Testing in The Age of AI: 2025 Guide.
https://www.scalosoft.com/blog/penetration-testing-in-the-age-of-ai-2025-guide
Originalartikel von lyon, bei Vervielfältigung bitte angeben: https://www.cncso.com/de/ai-penetration-testing-agent.html






