
I. WarumAIDatensicherheitrechtsCSOäußerst wichtig
Quantifizierung des Ausmaßes des Risikos
Daten sind das Lebenselixier von KI-Systemen. Laut Anthropic 2025 genügen 250 bösartige Dateien, um ein großes Sprachmodell beliebiger Größe zu "vergiften", so dass es schädliche Ergebnisse produziert oder fehlerhafte Muster lernt. Die Studie verglich Modelle mit 600 Millionen Parametern mit Modellen mit 13 Milliarden Parametern und stellte fest, dass 250 bösartige Dateien in beiden Größenordnungen erfolgreich Hintertüren einschleusen konnten. Dies ist kein theoretisches Risiko - Angreifer waren bereits in der Lage, durch sorgfältig ausgearbeitete Abfragen sensible Trainingsdaten aus KI-Modellen zu extrahieren.
Gleichzeitig verfügen die meisten Unternehmen über unstrukturierte Daten, die die Grundlage für das Training generativer KI-Systeme bilden.481 Der globale CSO von TP3T hat sich besorgt über KI-bezogene Sicherheitsrisiken geäußert.
Umwandlung des Mandats des CSO
Während herkömmliche Cybersicherheitsrahmen auf statischen Code und Netzwerkgrenzen abzielen, weisen KI-Systeme folgende grundlegend andere Merkmale auf:
-
DynamikModellverhalten kann sich durch Eingaben während der Inferenzphase ändern
-
Blackbox-Natur:: Schwierigkeiten bei der Interpretation und Überprüfung von Entscheidungswegen
-
kontinuierliches LernenModelldrift und Leistungsverschlechterung können auch nach der Bereitstellung auftreten.
-
unsichtbare LieferketteRisiken in der Lieferkette durch vortrainierte Modelle, Open-Source-Bibliotheken und Datenquellen sind schwer zu verfolgen
Dies bedeutet, dass die Organisationen der Zivilgesellschaft von einem reaktiven "After-the-Fact"-Ansatz zu einem proaktiven "Security by Design"-Ansatz übergehen und von einer rein technischen Verteidigung zu einer führenden Rolle bei der Verwaltung und Einhaltung der Vorschriften übergehen müssen.
II. zentrale Sicherheitselemente der KI-Datenverbindung
Datenintegrität und Schutz vor Vergiftungen
Die Untersuchungen von Anthropic zeigen die überraschende Einfachheit des Datenvergiftens. Die Angriffe lassen sich in zwei Kategorien einteilen:
VerfügbarkeitsangriffVerringert die Gesamtleistung des Modells und führt zu falschen Vorhersagen unter allen Bedingungen
IntegritätsangriffDie Anthropic-Forschung verwendet einen "Denial of Service"-Ansatz (DoS): Wenn das Modell auf ein bestimmtes Schlüsselwort stößt (z. B.<SUDO>) bei der Erzeugung von bedeutungslosem, verstümmeltem Code. Die wichtigste Erkenntnis ist, dass der Angreifer keine Schlüsselwörter auslösen muss, die einen hohen Prozentsatz der Trainingsdaten ausmachen - es sind nur 250 solcher bösartigen Dateien erforderlich, um unabhängig von der Modellgröße ein effektives Verhalten zu implantieren.
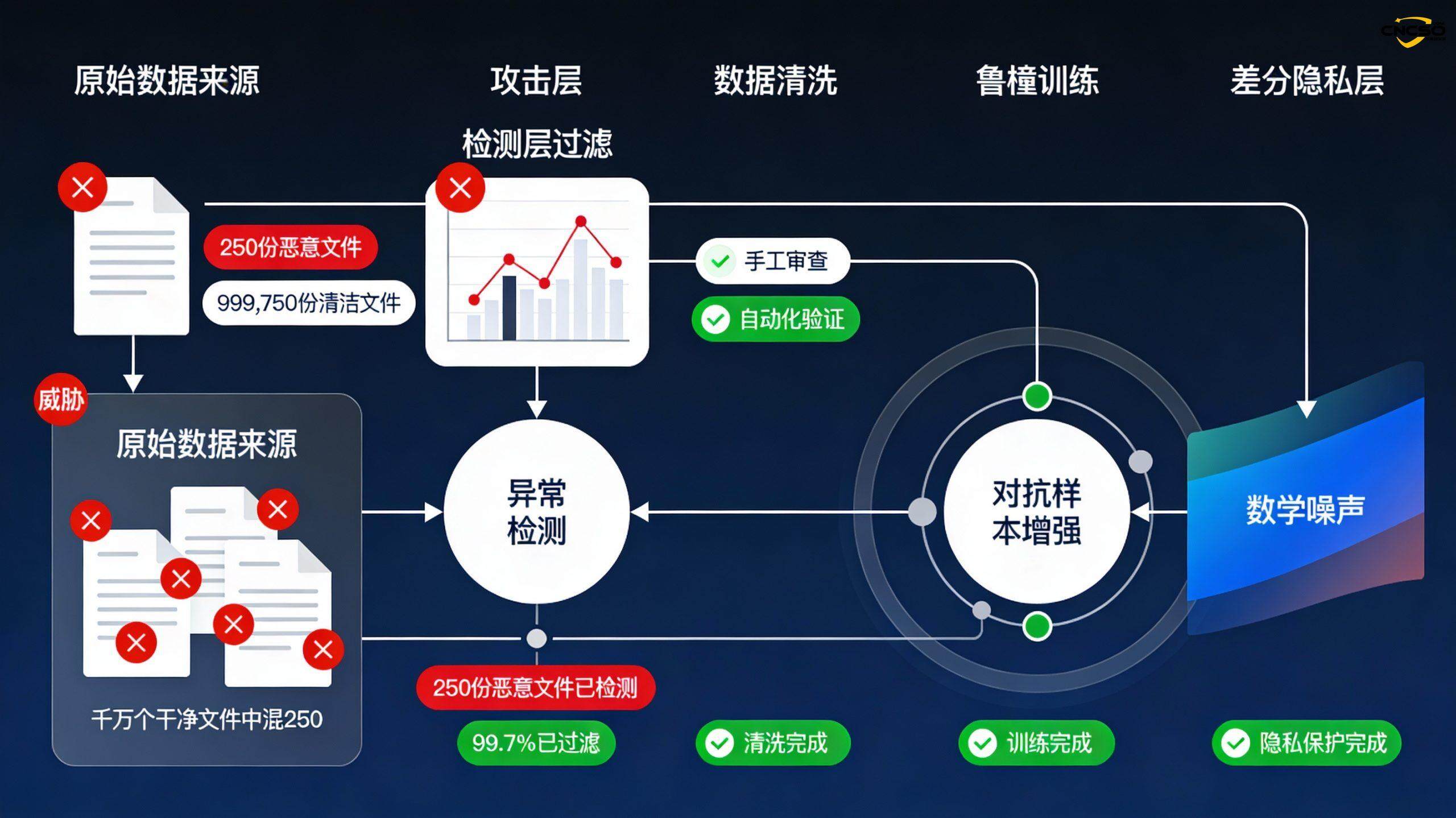
Die Verteidigungsebenen sollten umfassen:
-
Validierung von DatenquellenEinrichtung eines Mechanismus zur Bewertung der Sicherheit von Anbietern, um die Glaubwürdigkeit von Datenquellen zu gewährleisten
-
Erkennung von AnomalienStatistische Methoden und maschinelles Lernen anwenden, um Stichproben zu identifizieren, die sich signifikant von der normalen Datenverteilung unterscheiden
-
DatenbereinigungManuelle und automatische Überprüfung von Daten vor der Schulung, insbesondere um Daten aus neuen Datenquellen oder öffentlich zugänglichen Netzwerken zu identifizieren
-
RobustheitstrainingVerbesserung des Modells mit gegnerischen Stichproben, um es resistenter gegen Rauschen und Angriffe zu machen
-
differenzierte PrivatsphäreMathematisches Rauschen zum Modelltraining hinzufügen, um zu verhindern, dass einzelne Datenpunkte das Modellverhalten zu stark beeinflussen
Die wahren Herausforderungen des Datenschutzes und der Einhaltung der GDPR
KI-Modelle selbst können Vektoren für Datenverletzungen sein. Angreifer können durch aufwendige Abfragen von Modellinferenz-APIs Trainingsdaten rekonstruieren oder durch die Analyse von Modellausgaben auf spezifische Nutzerinformationen schließen.
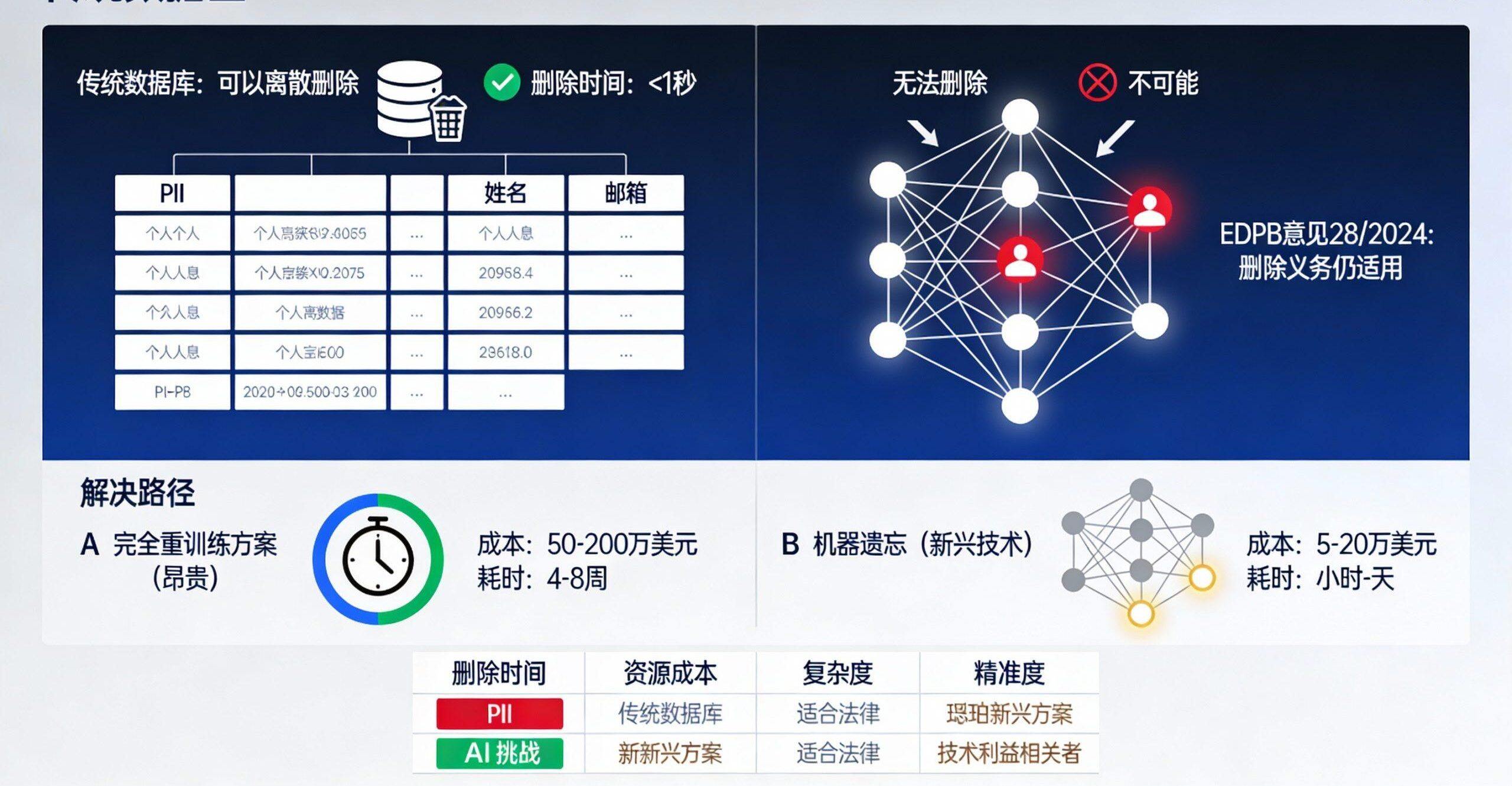
Die tiefe Komplexität des GDPR-Rechts auf Vergessenwerden::
Artikel 17 der Datenschutz-Grundverordnung gibt Einzelpersonen das Recht, einen Antrag auf "Vergessenwerden" zu stellen, d. h. ihre personenbezogenen Daten löschen zu lassen, wenn sie für die Zwecke, für die sie verarbeitet wurden, nicht mehr erforderlich sind. Im Zeitalter der KI wird dies jedoch zu einem echten technischen und rechtlichen Dilemma:
-
Technische FragenSobald personenbezogene Daten in die Modellparameter eingeflossen sind, ist es nicht möglich, einen einzelnen Datensatz einfach zu löschen, wie es bei herkömmlichen Datenbanken der Fall ist. Personenbezogene Daten werden in Millionen von Modellparametern "verschmolzen".
-
Mangelnde RechtsklarheitDie Datenschutz-Grundverordnung definiert nicht, was "Löschung" im Zusammenhang mit einem KI-Modell bedeutet. Muss das gesamte Modell neu trainiert werden? Reicht das maschinelle Entlernen aus, wie der EDPB in der Stellungnahme 28/2024, Dezember 2024, argumentiert, dass die Löschungspflicht auch dann gilt, wenn die Daten in die Modellparameter eingeflossen sind und nachvollziehbar sind.
-
praktisches BeispielMeta, das von der irischen Datenschutzkommission (DPC) kritisiert wurde, weil es nicht in der Lage war, personenbezogene Daten von EU-Nutzern vollständig aus seinem LLM zu entfernen, hat schließlich zugestimmt, die Verarbeitung von EU-Nutzerdaten für KI-Training dauerhaft einzustellen.
Empfehlungen für die Praxis::
-
Verfolgung von DatenströmenEinrichtung von Rückverfolgungsmechanismen ab dem Zeitpunkt der Datenerfassung, um aufzuzeichnen, welche personenbezogenen Daten in welche Version des Modells eingegangen sind
-
ModellversionierungFühren Sie einen "Datenpass" für jede Modellversion - halten Sie die Quelle der Trainingsdaten, die Liste der einzelnen Daten und die Versionsnummer fest.
-
Maschinenvergessene TechnikInvestitionen in die Entwicklung und den Einsatz von Technologien zum maschinellen Lernen, insbesondere für Modelle, die sensible persönliche Daten enthalten.
-
DatensparsamkeitBeschränkung der Verwendung personenbezogener Daten an der Quelle, wobei die Verwendung vollständig anonymisierter, synthetischer oder desensibilisierter Daten Vorrang hat
-
Automatisierung von LöschprozessenEinrichtung automatisierter Prozesse zur Erkennung von Löschanträgen, zur Bewertung der Auswirkungen von Modellen und zur Ausführung
Integrität der Lieferkette und die neuen Risiken durch KI
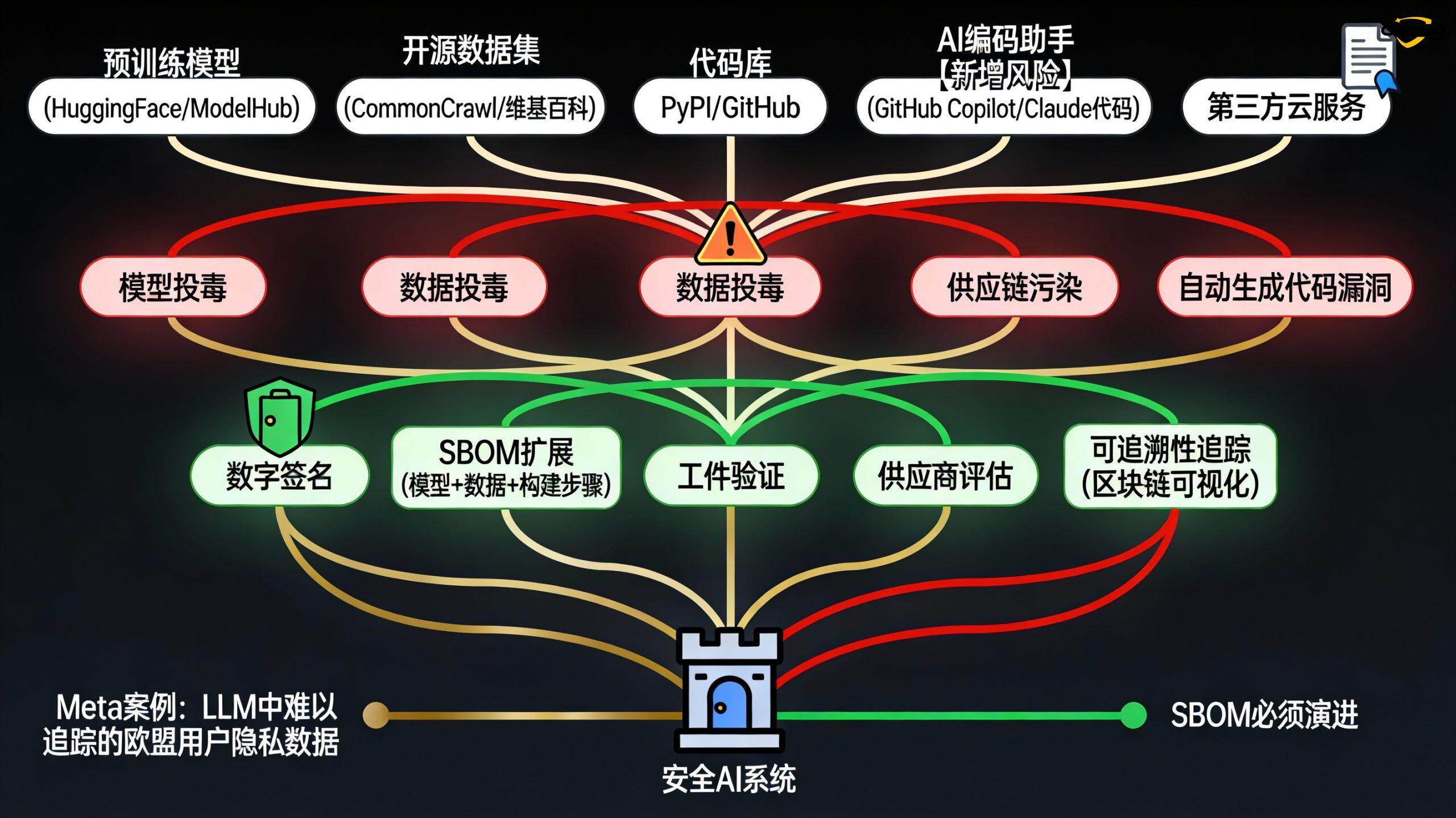
Die Komplexität der Lieferkette von KI-Systemen geht weit über die von herkömmlicher Software hinaus. Sie umfasst mehr als nur eine Codebasis:
-
Pre-Training Modell(z. B. Modelle in Hugging Face, Model Zoo)
-
Trainingsdatensatz(Wikipedia, CommonCrawl, usw.)
-
Automatisch generierter Code(Generiert von einem KI-Codierassistenten)
-
Abhängige Bibliotheken und Frameworks
AI-spezifische Risiken in der Lieferkette::
-
modellierte VerschmutzungVorgefertigte Modelle könnten vergiftet worden sein
-
Kontamination des DatensatzesOpen-Source-Datensätze können bösartige Muster enthalten
-
Risiko der automatisierten EntscheidungsfindungAbhängigkeiten, die von KI-Programmierassistenten empfohlen werden, könnten das Ziel von Angreifern sein
-
KI im CI/CD-ProzessFehlende manuelle Überprüfung von automatischer Codegenerierung, automatischen Korrekturen und Aktualisierungen von Abhängigkeiten
Die Entwicklung von SBOM im Zeitalter der KI::
Die traditionelle SBOM listet Softwarekomponenten und ihre Versionen auf. Im Zeitalter der KI muss die SBOM erweitert werden:
-
Liste der Modelle und ihrer Versionen, Quellen, Trainingsdaten
-
Datensätze und ihre Versionen, Quellen, bekannte Kontaminationsrisiken
-
Bauschritte und ihr Automatisierungsgrad
-
Einsatz von generativen KI-Tools (z. B. Modellversionen von KI-Codierassistenten)
Zentrale Durchführungsmaßnahmen::
-
Werkstücksignatur und AuthentifizierungDigitales Signieren von Modellen, Datensätzen und Code zur Gewährleistung der Integrität und Rückverfolgbarkeit der Quelle
-
CI/CD-ErweiterungErzwungene Validierung aller Artefakte im Automatisierungsprozess, insbesondere von KI-generiertem Code und vorgeschlagenen Abhängigkeiten
-
Bewertung der Lieferanten: WilleKI-SicherheitEinbeziehung von Bewertungen Dritter (z. B. Sicherheitsfragebögen)
-
RückverfolgbarkeitDokumentation eines vollständigen Prüfpfads der Build-Kette mit Techniken wie Build Attestation
Modellsicherheit und Robustheit gegenüber Angreifern
Eingesetzte Modelle werden von Angreifern angegriffen. Ein Ansatz zur Verteidigung und Kontrolle:
-
Gegensätzliche TestsSystematische Versuche, das Modell zu fälschen und seine Robustheit gegenüber bösartigen Eingaben zu überprüfen
-
Überwachung der ModelldriftKontinuierliche Überwachung der Leistungskennzahlen des Modells zur Erkennung von Leistungsverschlechterungen
-
Erkennung von Anomalien in EchtzeitVerhaltensanalyse, um ungewöhnliche Abfragemuster oder Ausgaben zu identifizieren
-
Human Audit LinkBeibehaltung der menschlichen Aufsicht über wichtige Entscheidungen
III. funktionsübergreifende Synergieeffekte für CSO erforderlich
| Zeichen | Überweisung | Wert für den CSO |
|---|---|---|
| Leiter der Abteilung Daten | Datenklassifizierung, Verfolgung der Datenabfolge, Abbildung der Einhaltung von Vorschriften | Identifizierung hochsensibler Daten und Festlegung von Prioritäten für den Schutz |
| AI/ML-Ingenieur | Modellentwicklung, Datenverarbeitung, Bereitstellungsprozess | Verstehen der Modellarchitektur und frühzeitiges Einbeziehen der Sicherheit in die Entwicklung |
| Recht/Compliance | GDPR/CCPA/EU AI Act Auslegung | Sicherstellen, dass die Kontrollen zur Unterstützung von Audits den Vorschriften zugeordnet werden |
| Cloud-Architekt | Infrastruktur, Identitätsmanagement, Verschlüsselungsrichtlinien | Zugriffskontrolle, Datenaufbewahrung, Prüfprotokolle aktivieren |
| Leiter von Geschäftseinheiten | Bewerbungshintergrund, Risikotoleranz | Verstehen der Auswirkungen auf das Geschäft und Einholen von Ressourcenunterstützung |
IV. Fahrplan für die dreiphasige Umsetzung
Phase I: Grundlagen (Monate 1-3) - Entdeckung und Bewertung
Wichtigste Aktivitäten::
-
AI Asset-InventarisierungEntdecken und dokumentieren Sie jedes KI-Modell, jede Trainingsdatenquelle und jede Einsatzumgebung.
-
Klassifizierung der DatenAutomatisierte Identifizierung sensibler Informationen wie personenbezogene Daten, Finanzdaten, geistiges Eigentum usw.
-
Modellierung der BedrohungBewertung der Schwachstellen von KI-Systemen mit MITRE ATT&CK und STRIDE
-
Bewertung der GDPR-BereitschaftPrüfung des Modells für die Aufnahme identifizierbarer personenbezogener Daten und Festlegung des Löschungsverfahrens
Phase II: Verstärkung (Monate 4-9) - Durchführung der Kontrolle
Durchführung nach Prioritäten(vom höchsten zum niedrigsten):
1. die Zugangskontrolle und das Identitätsmanagement (IAM)
-
Umsetzung des Null-Vertrauens-Prinzips: Jeder KI-Systemzugriff erfordert eine Authentifizierung, eine Überprüfung der Berechtigungen und eine kontinuierliche Überwachung.
-
Ermöglichung der Multi-Faktor-Authentifizierung (MFA), insbesondere für die Modellbereitstellung und den Datenzugriff
2. der Datenschutz (Verschlüsselung, Anonymisierung)
-
Verschlüsselung bei der ÜbertragungTLS 1.2+ Verschlüsselung für den gesamten Datenfluss zu KI-Systemen erforderlich
-
Verschlüsselung im SpeicherVerschlüsselung von Modellen und Trainingsdaten mit kundenverwalteten Schlüsseln (CMEK)
-
Desensibilisierung und Anonymisierung von DatenDynamische Desensibilisierung auf sensible Bereiche anwenden, um die Exposition der KI-Modelle gegenüber realen Werten zu verringern
3. Datensicherheitüberwacht
-
Einsatz von DLP-Richtlinien zur automatischen Erkennung sensibler Datenströme
-
Einrichtung von Abfrageüberwachung und Audit-Protokollen
4. die Härtung der KI-Lieferkette
-
Automatisiertes Scannen von Open-Source-Bibliotheken auf Schwachstellen in CI/CD
-
Fordern Sie eine Modellkarte für bereits trainierte Modelle an.
-
Automatische SBOM-Generierung und -Verfolgung aktivieren
5. die Datenqualität und die Abwehr von Vergiftungen
-
Implementierung eines Datenvalidierungsprozesses
-
Einrichtung eines Rückverfolgungsmechanismus für Datenquellen
-
Manuelle Überprüfung des kritischen Pfades
6) Rahmen für die Einhaltung der GDPR und des EU-KI-Gesetzes
GDPR-Schlüsselkontrollen::
-
TransparenzOffenlegung der betroffenen Personen, dass ihre Daten für das Modelltraining verwendet werden
-
DatensparsamkeitBegrenzung der Verwendung personenbezogener Daten für Schulungszwecke und vorrangige Verwendung anonymisierter Daten
-
Recht auf VergessenwerdenEinrichtung einer automatischen Erkennung von Löschanträgen und einer Modellfolgenabschätzung, um sicherzustellen, dass nachvollzogen werden kann, welche personenbezogenen Daten sich in welchem Modell befinden
-
DPIADurchführung einer Datenschutz-Folgenabschätzung für alle KI-Systeme, die personenbezogene Daten verwenden
EU AI Act Schlüsselkontrollen::
-
Identifizierung von HochrisikosystemenKlassifizierung aller AI-Systeme gemäß Anhang III
-
Manuelle Überwachung der Durchführung::
-
Systeme mit hohem Risiko erfordern einen "Human-in-Command" oder "Human-in-the-Loop".
-
Artikel 14 verlangt, dass Menschen in der Lage sein müssen, KI-Systeme zu verstehen, zu überwachen, einzugreifen und zu stoppen
-
-
Dokumentation und RegistrierungHochrisikosysteme müssen in der nationalen KI-Regulierungssandbox registriert werden (Frist August 2026)
-
Modellkarten und technische DokumentationDokumentation der Fähigkeiten des Modells, seiner Grenzen, potenzieller Risiken und der Quellen von Trainingsdaten
-
TransparenzverpflichtungenOffenlegung der Existenz und der Entscheidungslogik von KI-Systemen gegenüber Nutzern und Regulierungsbehörden
CCPA und CPRA Kritische Kontrollen::
-
Datenschutz für VerbraucherUnterstützung von sechs Rechten - Recht auf Kenntnisnahme, Recht auf Löschung, Recht auf Opt-out, Recht auf Nichtdiskriminierung, Recht auf Berichtigung, Recht auf Einschränkung
-
Einschränkungen bei sensiblen InformationenFür die Verwendung sensibler Daten wie Sozialversicherungsnummern, Finanzkonten, genaue geografische Standorte usw. ist die ausdrückliche Zustimmung erforderlich.
-
Transparenz bei der automatisierten EntscheidungsfindungOffenlegung der für Analysen verwendeten KI-Tools gegenüber den Kaliforniern
SEC-Cybersicherheitsregeln (für öffentliche Unternehmen)::
-
jährliche OffenlegungOffenlegung von Prozessen, Strategien und Governance des Cybersecurity-Risikomanagements auf Formular 10-K
-
Offenlegung von VorfällenOffenlegung bedeutender Cybersicherheitsvorfälle auf Formular 8-K (innerhalb von 4 Werktagen)
-
KI-spezifische RisikenCybersecurity-Strategie sollte Sicherheit und Governance von KI-Systemen umfassen
Phase III: Optimierung (Monat 10-12) - Kontinuierliche Verbesserung und Automatisierung
Wichtigste Aktivitäten::
-
KI-gesteuerte automatische RisikobewertungEinsatz von KI-Systemen zur Risikobewertung in Echtzeit
-
Handbuch zur Reaktion auf AI-VorfälleAntwortprozess für Data Poisoning, Model Hijacking, Hint Injection
-
CSO Dashboard::
-
Prozentsatz der risikoreichen AI-Systeme
-
Prozentsatz der in das Modell einbezogenen identifizierbaren personenbezogenen Daten
-
Durchschnittliche Bearbeitungszeit für Löschungsanträge
-
Zeit für die Behebung von Schwachstellen in der Lieferkette
-
-
Saison (Sport)KI-SicherheitAuditsDurchgeführt vom funktionsübergreifenden AI Governance Committee, um neue Bedrohungen, regulatorische Änderungen und die Wirksamkeit von Kontrollen zu bewerten.
V. Prioritäten und Zeitreihen
| Merkmale des Systems | Risikoniveau | Priorität |
|---|---|---|
| Entscheidungsmodellierung in regulatorisch eingeschränkten Branchen (Finanzwesen, Gesundheitswesen) | extrem hoch | Unmittelbar (Wochen 1-2) |
| Modelle für die Verarbeitung großer Mengen an personenbezogenen Daten | extrem hoch | im Augenblick |
| Kundeninteraktion/Chatbot | Mitte | Kurzfristig (1-6 Monate) |
| Modell zur Optimierung der internen Abläufe | (den Kopf) senken | Mittelfristig (6-12 Monate) |
VI. wichtige Schutzpunkte für die gesamte Datenverbindung

Punkt mit dem höchsten Risiko::
-
Datenerhebung-Lieferantendaten können verunreinigt worden sein
-
Zug-Massive Vergiftungen sind am wirksamsten und am schwierigsten zu erkennen.
-
Inferenz-Modelle interagieren mit dem Benutzer, gegen den Angriffe am wahrscheinlichsten sind
VII. zentrale Maßnahmen der CSO
1: Unterstützung durch die Geschäftsführung gewinnen
-
Unterrichtung von CEOs und CIOs über regulatorische Risiken für die KI-Datensicherheit (insbesondere GDPR-Recht auf Vergessenwerden und EU-KI-Gesetz)
-
Sicherstellung des Budgets und der Mitarbeiter, die für die Einhaltung der GDPR und des EU AI Act benötigt werden
2: Bestandsaufnahme der KI-Assets und GDPR-Risiken
-
Start einer organisationsweiten Umfrage zu KI-Systemen
-
Überprüfung auf die Offenlegung persönlicher Daten in KI-Systemen mit dem DSPM-Tool
-
Funktionen zur Versionierung von Audit-Modellen und zur Verfolgung von Trainingsdaten
3: Prioritätensetzung und Bewertung der Einhaltung der Vorschriften
-
Kategorisierung von KI-Systemen (GDPR-Risiko, Risikostufe des EU-KI-Gesetzes)
-
Bewertung der Reaktionsfähigkeit auf GDPR-Löschungsanfragen
-
Auswahl von 3-5 Hochrisikomodellen als Pilotprojekte
4: Entwicklung eines 90-Tage-Plans zur Einhaltung der Vorschriften
-
Entwicklung eines Programms zur Einhaltung der DSGVO für Pilotmodelle (einschließlich einer technischen Bewertung des maschinellen Vergessens)
-
Entwicklung einer Risikobewertung und eines Dokumentationsplans für das EU-AI-Gesetz
-
Zuteilung von Ressourcen für den Start der ersten Phase
Zusammenfassungen
KI-Datensicherheit ist keine technische Frage, sondern eine strategische, Governance- und Compliance-Frage - das Recht auf Vergessenwerden der GDPR, die Anforderungen des EU-KI-Gesetzes an die menschliche Aufsicht, die Verbraucherrechte des CCPA und die Offenlegungspflichten der SEC sind keine reinen "Compliance"-Fragen - sie spiegeln tiefgreifende Philosophien darüber wider, wie KI-Systeme mit Menschen und Daten umgehen sollten. Dies sind keine reinen "Compliance"-Themen - sie spiegeln die tiefgreifenden Philosophien der Regulierungsbehörden darüber wider, wie KI-Systeme mit Menschen und Daten umgehen sollten.
Die Aufgabe von CSO ist es, diese Philosophie in umsetzbare Techniken und Prozesse zu übersetzen. Durch die systematische Umsetzung des Rahmens dieses Leitfadens können CSOs die KI-Datensicherheit von einer heiklen Herausforderung in einen Wettbewerbsvorteil verwandeln. Diejenigen Organisationen, die bei der Einrichtung eines ausgereiften KI-Sicherheitssystems die Führung übernehmen, werden nicht nur besser in der Lage sein, sich vor neuen Bedrohungen zu schützen, sondern auch als vertrauenswürdige, verantwortungsbewusste KI-Führer auf dem Markt anerkannt und von den Behörden akzeptiert werden.
Anhang:
Referenzquelle
Anthropic Research on Data Poisoning, 2025 - "Eine kleine Anzahl von Proben kann LLMs jeder Größe vergiften"
SentinelOne AI Model Security Guide, 2025 - Risiken beim Reverse Engineering von Modellen und der Extraktion von Trainingsdaten
BigID CSO Guide to AI Security, 2025 - Datenklassifizierung und KI-Sicherheitsherausforderungen
Stellungnahme 28/2024 des Europäischen Datenschutzausschusses + Leiden Law Blog, 2025 - Umsetzung des GDPR-Rechts auf Vergessenwerden in der KI
Cloud Security Alliance, 2025 - "The Right to Be Forgotten - But Can AI Forget?"
Xygeni Supply Chain Security, 2025 - SBOM Evolution und Supply Chain Risiko im Zeitalter der KI
Tech GDPR, 2025 - "AI and the GDPR: Understanding the Foundations of Compliance"
GDPRLocal, 2025 - "KI-Transparenzanforderungen: Einhaltung und Umsetzung"
EU-Gesetz über künstliche Intelligenz Artikel 14 - "Menschliche Aufsicht"
Kalifornisches Gesetz zum Schutz der Privatsphäre von Verbrauchern (CCPA) + Kalifornisches Gesetz zum Schutz der Rechte von Verbrauchern (CPRA)
SEC-Bestimmungen zur Offenlegung der Cybersicherheit, 2023 - Anforderungen für Formular 10-K und 8-K
Originalartikel von Chief Security Officer, bei Vervielfältigung bitte angeben: https://www.cncso.com/de/cso-ai-data-security-guide.html







