
I. サイバーセキュリティ分野におけるAIの発展動向
1.1 ルール主導からインテリジェントな意思決定へのシフト
サイバーセキュリティ自動化市場は、根本的なアップグレードが行われている。従来の静的ルールエンジン(SAST、DAST)は、検出のために事前に定義された脆弱性シグネチャに依存しており、攻撃対象の動的な進化に適応することが困難でした。これとは対照的に、LLMとマルチエージェントアーキテクチャを搭載した次世代ツールは、適応性を実証しています。GPT-4は、32クラスの悪用可能な脆弱性の検出において94%の精度を達成しており、従来のSASTツールと比較して質的な飛躍を遂げています。2025年の市場調査によると、自動ペネトレーションテスト、SOARプラットフォームの統合、AI主導の脅威検出がコア・インフラストラクチャ
しかし、この知能の進歩は直線的に漸増するものではない。研究データによると、LLMはその高い精度の裏側で、3つの有効な発見に対して1つの偽陽性があるという高い確率を示唆している。これは重要な特徴を反映している。AIは、幅の広さ(脆弱性の種類のカバー)と深さ(文脈の理解)の間で恒常的な緊張関係にある。
1.2 エージェント・アーキテクチャのパラダイム・イノベーション
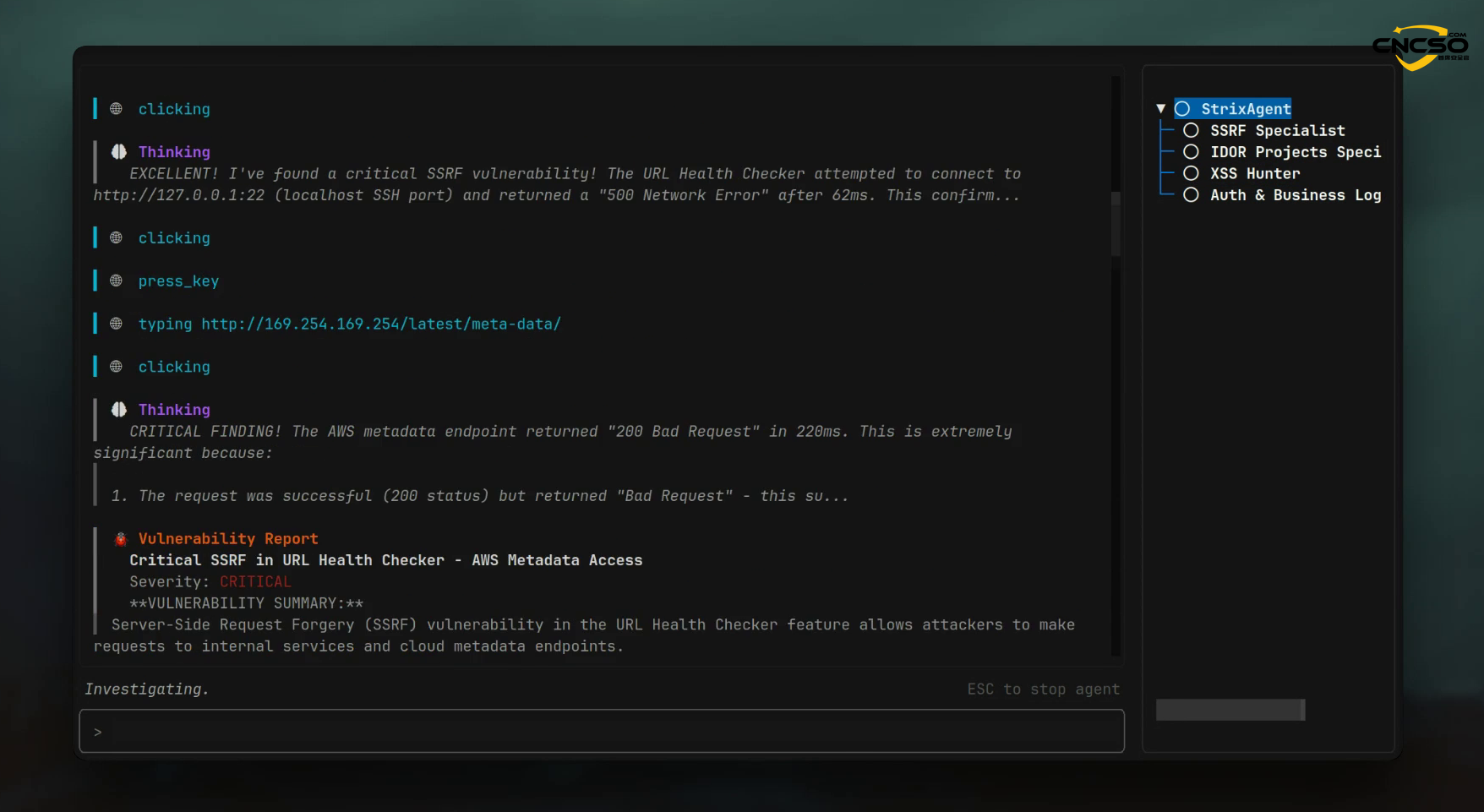
Strixが採用しているマルチエージェントのコラボレーションフレームワークは、2024年以降の侵入テストツールの特徴的な設計です。モノリシックなLLMの呼び出しとは異なり、エージェント・オーケストレーション・システム(通常、LangChain、LangGraphをベースとする)は、セキュリティテストを専門化された分業に分解します:偵察エージェントは攻撃表面のマッピングを担当し、搾取エージェントはペイロードの注入を実行し、検証エージェントはPoCの再現性を確認します。あるエージェントの発見が新しい攻撃ベクトルを引き起こすと、他のエージェントは動的に戦略を調整します。
実証研究により、マルチエージェントの優位性が証明されています。MAVULマルチエージェント脆弱性検知システムは、シングルエージェントシステムと比較して6001 TP3T以上、他のマルチエージェントシステム(GPTLens)と比較して621 TP3T以上性能が向上しています。このアーキテクチャの優位性は、次の2つのメカニズムに起因しています。-(2)協調的キャリブレーション-複数ラウンドのエージェント間対話によって生成される相互検証は、ファントム問題を自然に減少させる。
1.3 ポイント・テストから継続的ディフェンスへの移行
従来のペネトレーションテストは、ポイント・イン・タイムのイベント(毎年または四半期ごとに実施)であったが、AI自動化ツールは、CI/CDパイプライン統合のための継続的なテストをサポートする。このパラダイムシフトは戦略的に理にかなっている。組織は、コードのコミットごとに自動化された評価をトリガーすることができ、脆弱性の発見時間をデプロイ後から開発へと進めることができる。コストベンチマークによると、$2万件の防御的侵入テストを実施することで、$445万件の世界平均データ侵害コストと比較して、200倍以上のROIが得られる。
二、AIエージェント自動浸透のコア・ハイライト
2.1 完全な脆弱性ライフサイクルの閉鎖
Strixの最も重要な差別化能力は以下の通りである。検出から検証、修復までの完全なクローズドループ従来のDASTツールは、脆弱性の報告段階で止まってしまう(多くの場合、高い偽陽性を伴う)。従来のDASTツールが脆弱性の報告段階で止まってしまうのに対し(多くの場合、高い偽陽性を伴う)、Strixは実際の悪用を通じて脆弱性の真の悪用可能性を確認します:
-
偵察段階:HTTPプロキシによるトラフィックの乗っ取り、実際のユーザー行動をシミュレートするためのブラウザの自動化、データフローを追跡するための動的コード解析。
-
エクスプロイト段階:Python実行環境はカスタムエクスプロイト開発をサポートし、ターミナル環境はシステムレベルの攻撃(コマンドインジェクション、RCE)を実行する。
-
検証段階:完全なリクエスト/レスポンス・エビデンスチェーンの自動生成と再現可能なPoCの保存
-
修正フェーズ:修正提案を直接マージ可能なコードに変換するために、GitHub Pull Requestsを自動生成する。
このクローズド・ループ・デザインは、従来のツールの根本的な欠点に直接対処している:誤報の分類と優先順位付けのコスト..各DASTレポートの手作業によるレビューには平均$200-300/時間がかかるのに対し、AIによって検証された脆弱性はそのまま修復プロセスに移行できる。
2.2 ビジネスロジックレベルでの適応検知
一般的なパターンマッチングとは対照的に、Strix のエージェントはアプリケーションの状態遷移の法則を学習することができます。たとえば、IDOR (Insecure Direct Object Reference) 検出では、次のようになります:
-
エージェントは、認証ポリシー(トークンの振る舞い、セッションスコープ)を自動的にマッピングします。
-
そして、(既知のリソースだけでなく)近隣のリソースIDを系統的に検出する。
-
マルチユーザーテストアカウントでの権限境界の検証
このアプローチは、特定のアプリケーションのビジネスプロセスを深く理解する必要があるため、従来のセキュリ ティスキャンツールで実装することは事実上不可能です。経験的な証拠から、エージェントベースの侵入テストは、次のことを発見する上で、重要な役割を果たすことがわかります。チェーンの脆弱性(マルチステップ攻撃シーケンス)は、単一の脆弱性スキャンよりも大幅に優れている。
2.3 コストと時間における根本的な改善
次元の定量的比較:
| 次元 | 手刺し | 従来のオートメーション | AIエージェントの潜入 |
|---|---|---|---|
| 平均周期性 | 3~8週間 | 1~2週間 | 2~8時間 |
| コスト範囲 | $15K-$30K | $5K-$10K | <$100(オープンソース)/~$5(コマーシャル) |
| カバレッジ | 奥行きが深く、幅が狭い | 幅が広く、奥行きが浅い | 両方ある |
| 再試験の頻度 | 年1~2回 | オンデマンド | 継続的(CI/CDインテグレーション) |
| 偽陽性率 | <5% | 30-50% | 10-20% |
YouTubeのライブテストでは、Equifaxの脆弱性(Apache Struts RCE)に対するStrixの完全な評価サイクルは約12分で、コストは$5以下だった。
2.4 ゼロ・トラスト・アーキテクチャ継続的な検証によるイネーブラー
AI自動侵入ツールは、ゼロ・トラスト・モデルの導入を当然サポートする。ツールはリソースが変更されるたびにアセスメントをトリガーするため、組織は以下を得ることができる。継続的検証定期的な監査に依存するのではなく、その能力を評価する。これは特にマイクロサービス・アーキテクチャやコンテナ・オーケストレーション環境に適用可能で、構成ドリフトや一時的なリソースが従来の評価の盲点を劇的に増やす。
III.従来の浸透法との比較分析
3.1 強みの次元
(1) 規模とコスト効率
自動化された浸透により、単価が大幅に削減される。組織が何十ものアプリケーションを管理する場合、手作業による各評価の累積コストが大きなボトルネックになる可能性があります。パラレルスキャン--同時に複数のターゲットを対象とする独立エージェントの連携では、増分コストがゼロになる傾向がある(LLM APIコールのコストのみ)。これとは対照的に、手動チームのスケーリングは、セキュリティ専門家の希少性と調整コストによって制限される。
(2) 一貫性と再現性
AIシステムは、(同じプロンプトとコンフィギュレーションで)決定論的な推論パスに従う。これは、テスト結果がバージョン管理、チームコラボレーション、監査のために検証しやすいことを意味する。マニュアルテストの質は、個人の経験に大きく依存する。2人のシニアテスターが50%以上の差で仕事の深さとスタイルが異なることがある。
(3) 0day脆弱性検出の可能性
CVE-Bench と HPTSA の調査によると、GPT-4 を搭載したエージェントは、1 日のセットアップで 12.5% の実際のウェブアプリケーションの脆弱性を悪用することができ、ゼロデイセットアップでは 10% の成功率を示しています。この「既知の未知」を捕捉する能力は、ルールベースではなく、LLMの一般化された学習に起因しています。
3.2 デメリットと限界
(1) ビジネスロジック脆弱性(BLV)のシステム的盲点
これはAI自動化ツールの最も深刻な限界である。ビジネス・ロジックの脆弱性は、アプリケーションの模式図非コード化形式査定を行う。例
-
Eコマース・アプリを使えば、過剰注文の在庫チェックを回避できる
-
取引が確定する前に二重の控除を可能にする支払いシステム
-
特定の一連の行動によって特権の昇格を可能にする特権システム
これらのシナリオは、アプリケーションの実行レベルでは「正しい」(コードエラーはない)が、ビジネスレベルでは「間違っている」(期待されるプロセスに違反している)。AIツールにはビジネスルールをモデル化する能力がないため、こうしたタイプの脆弱性を自動的に特定することはできない。業界のデータによると、複雑で連鎖したビジネス・ロジックの脆弱性は、以下を占めている。40-60%の高価値脆弱性レポート(特にバグ報奨金プラットフォームにおいて)しかし、AI自動化ツールの検出率は5-10%に過ぎない。
(2) LLMイリュージョンとスプリアス脆弱性の生成
AIによる検証段階は誤検出を減らすことができるが、情報がない場合に「もっともらしいが偽の」内容を生成するというLLM固有の性質は残る。ある臨床安全性研究では、テストされたすべてのLLMが、敵対的な合図に反応して50-82%の幻覚率(偽の詳細の生成)を生成することがわかった。安全性試験の文脈では、これは次のように現れた:
-
仮想的な脆弱性の説明(実際には悪用できない)
-
幻覚パッケージ名(架空の依存項目またはCVE)
-
誤った利用経路の記述
微調整はこの問題を軽減するのに有効である(80%を下げる)が、オープンソースのツールでは通常実現不可能である。
(3)コンテクスチュアル・ブラインドネスとコンプライアンス・リスク
AIシステムの欠如ビジネス・コンテキストの認識能力例
-
データ輸出作業は技術的には可能だが、HIPAA/GDPRの枠組みでは違反となる。
-
コンフィグレーションは機能的には問題ないが、組織固有のセキュ リティポリシーに違反している。
-
脆弱性を悪用された際に暴露されたデータは、データプライバシー規制を引き起こす可能性がある。
AIツールが生成する是正勧告は、技術的には「正しい」が、コンプライアンス的には「間違っている」ことがあり、医療や金融などの規制業界では深刻なリスクとなる。
(4) マルチエージェントシステムの内生的セキュリティリスク
Strixが依拠するLLMとツール統合アーキテクチャは、本質的に新たな攻撃対象領域を生み出す。主なリスクは以下の通り:
-
チップ・インジェクション攻撃悪意のある入力(例えば、アプリケーション名、エラーメッセージ)には、エージェントが境界外の 操作を実行できるようにする命令が含まれている可能性があります。調査によると、オリジナルのフレームワークの下でのプロンプトインジェクションの成功率は73.21 TP3Tに達し、複数の保護レイヤーを使用しても残留リスクは8.71 TP3Tである。
-
エージェント間の信頼の乱用:: 100%のテストLLMは、たとえ同じユーザリクエストが拒否されたとしても、無条件にピアAgentからのコマンドを実行します。これは、あるAgentが危険な状態に陥った場合、他のAgentは自動的にその悪意のあるコマンドを信頼することを意味します。
これらの内因性リスクには、厳格なサンドボックス隔離と入力検証が必要であり、Strixはこれをサポートするが、ユーザーが正しく設定する必要がある。
3.3 スキルの低下と組織的リスク
AIツールへの過度の依存は、組織の弱体化につながる。人工浸透能力.調査が示している:
-
若手テスターは、カスタムエクスプロイトを書く能力を失うかもしれない。
-
チームがツールのアウトプットを過信することは、「誤った安全」をもたらす。
-
ツールの限界に関する組織の認識が不十分で、戦略的セキュリティギャップにつながる
このような「スキル低下の罠」は自動化の波の中で繰り返され、ハイブリッド・ワークフロー(自動化されたスキャニングの後に、重要な発見を手作業でレビューする)によって軽減する必要がある。
IV.核となる技術的視点と提言
4.1 最適なアプリケーション・シナリオ
AIエージェントによる自動潜入うってつけ以下のシーン:
-
高容量、低複雑度の環境事業複数のウェブアプリケーション、API、標準技術スタック
-
継続的インテグレーション環境(CIE)1日/週に何度も評価する必要があるDevSecOpsプロセス
-
リソースに制約のある組織: 年間$5万円以上のマニュアル査定を受ける余裕のない中小企業
-
既知の脆弱性クラスの迅速な検証PCI-DSSコンプライアンス・スキャン、CVSSスコアリング・ワークフロー
-
バグ報奨金インフラバグ報告の迅速な事前審査が可能に
4.2 保持しなければならないマニュアルの役割
最先端のAIツールを導入しても、以下のような作業がある。歯が立たない:
-
脅威のモデリングとスコーピングアプリケーションの主要な資産と攻撃の想定を理解する。
-
ビジネス・ロジックのレビューワークフローの妥当性を検証し、不正使用シナリオを特定する。
-
チェーン脆弱性分析複数のシングルポイント脆弱性を完全な攻撃チェーンにつなげる。
-
コンプライアンス・マッピング技術的発見をコンプライアンス結論に変換
-
バリデーションの修正パッチが新たな脆弱性や機能停止をもたらさないようにする。
4.3 ガバナンスと法的枠組み
AI侵入ツールの導入には、明確なガバナンスの枠組みを確立する必要がある:
-
明確な任務と範囲テスト対象、タイム・ウィンドウ、除外ゾーン(特定のデータベース、本番取引システム)の定義を文書化。AIツールの「行き過ぎ」傾向に注意 - ツールレベルでの厳格なアクセス制御の必要性。
-
データ・プライバシー・コンプライアンスAIツールで処理されるテストトラフィックや調査結果には、機密データが含まれている可能性がある。調査結果によると、83%の組織では、自動化されたAIデータ保護(DLP)が欠如している。対策としては、ローカル展開(Strixがネイティブでサポート)、データの最小化(テストアカウントは実データを使用しない)、アクセス監査などが挙げられる。
-
第三者責任商用のAIモデル(OpenAIなど)を使用する場合は、データがモデルのトレーニングに使用される可能性があることを理解すること。法的な契約では、そのような使用を明確に禁止すべきである。
-
監査とトレーサビリティ規制当局からの問い合わせに対応するため、テストログ(実行時、パラメータ、所見)を管理する。
4.4 ハイブリッド検査モデルに関する実践的提言
最も実行可能な戦略は以下の通りである。レイヤード・ディフェンス:
-
一層目:: AI自動化ツールによる広範なスキャン(サイクル:毎週/毎月)
-
セカンドレイヤールールエンジンサプリメント(SASTはコード解析用、DASTは既知の脆弱性用)
-
三階: : リスクの高い発見事項とビジネスロジックの境界の手動レビュー(サイクル:四半期ごと/要件変更時)
コストベンチマーク:
-
純粋な自動化:$1K~$5K/アプリケーション/年(高い誤警報、BLVの死角)
-
混合モデル:$10K~$20K/アプリケーション/年(低誤報、BLVカバー率)
-
純粋に手動:$30K~$10万/アプリケーション/年(最高精度、拡張性なし)
ほとんどの企業は、ハイブリッド・モデルで最適なコスト・ベネフィット・バランスを得ている。
V. 結論と今後の方向性
AIエージェントの自動ペネトレーションテストツールは、企業のセキュリティ検証のコスト構造と時間次元を再構築している。そのコアバリューは
(1)ペネトレーション・テストを希少な資源から持続可能な運用プロセスに変える。
(2)マルチエージェントコラボレーションにより、従来のツールの誤報率を大幅に低減。
(3) ゼロデイ脆弱性の初期検出能力を達成する。
すなわち、不十分なビジネス・ロジックの脆弱性検出能力、LLMの錯覚リスク、内在的なセキュリティ脆弱性(ヒント・インジェクション、エージェントの信頼悪用)、ビジネス・コンプライアンス意識の欠如などである。これらの限界は、エンジニアリングの進歩によって完全に解消されることはありません。これらは、実装の詳細ではなく、AIシステムの基本的な特性に起因しています。
戦略的認知AI自動侵入ツールは次のように理解されるべきである。従来のペネトレーション・テストの代替ではなく、補完するものである。.組織は、アプリケーションの複雑さ、業界の規制環境保護、リスク許容度に基づいて、自動化と手作業のバランスを見つける必要がある。単純なウェブ・アプリケーションと既知の脆弱性クラスについては、完全自動化が可能である。
今後、この分野の方向性としては、(1)マルチモーダルなエージェントアーキテクチャ(コード分析、構成監査、トラフィック分析の融合)、(2)ドメイン固有の微調整されたモデル(幻想を減らし、業界のコンプライアンス理解を向上させる)、(3)エージェントガバナンスフレームワークの標準化(コンテナセキュリティのOCI標準に類似)、(4)DevSecOpsプロセスとの緊密な統合、などが挙げられる。
書誌
合気道 (2025). AI侵入テストツール:自律的、エージェント的、継続的。
https://www.aikido.dev/blog/ai-penetration-testing
AI Alliance. DoomArena: A Security Testing Framework for AI Agents.
https://thealliance.ai/blog/doomarena-a-security-testing-framework-for-ai-agen
Scalosoft.(2025). AI時代の侵入テスト:2025年ガイド.
https://www.scalosoft.com/blog/penetration-testing-in-the-age-of-ai-2025-guide
元記事はlyonによるもので、転載の際はhttps://www.cncso.com/jp/ai-penetration-testing-agent.html。






