
I. なぜか?AIデータセキュリティ右CSO極めて重要
リスク規模の定量化
データはAIシステムの生命線である。Anthropic 2025によると、あらゆる規模の大規模言語モデルを「毒」にして、有害な出力を生成させたり、誤ったパターンを学習させたりするには、たった250個の悪意のあるファイルが必要だという。この研究では、6億のパラメータを持つモデルと130億のパラメータを持つモデルを比較し、どちらの規模でも250の悪意のあるファイルがバックドアの設置に成功することを発見した。これは理論上のリスクではなく、攻撃者は慎重に細工されたクエリによって、AIモデルから機密性の高いトレーニングデータを抽出することができている。
同時に、ほとんどの組織は非構造化データを持っており、これは生成AIシステムのトレーニングの基礎となる481。TP3TのグローバルCSOは、AI関連のセキュリティリスクについて懸念を表明している。
CSOの規約の変容
従来のサイバーセキュリティのフレームワークが静的なコードとネットワークの境界を対象としているのに対し、AIシステムは以下のような根本的に異なる特徴を持っている:
-
ダイナミズム推論段階では、入力によってモデルの振る舞いが変化する可能性がある。
-
ブラックボックス・ネイチャー意思決定経路の解釈と監査が難しい。
-
継続学習配備後もモデル・ドリフトや性能劣化が発生する可能性がある。
-
インビジブルサプライチェーン訓練済みモデル、オープンソースライブラリ、データソースのサプライチェーンリスクを追跡することは困難である。
つまり、CSOは「事後対応型」のアプローチから、プロアクティブな「セキュリティ・バイ・デザイン」のアプローチに移行しなければならず、純粋に技術的な防御から、ガバナンスとコンプライアンスにおける主導的な役割へと拡大する必要がある。
AIデータリンクのコア・セキュリティ要素
データインテグリティとポイズン・ディフェンス
Anthropicの研究は、データポイズニングの驚くべき単純さを明らかにした。攻撃は2つのカテゴリーに分類される:
アベイラビリティアタックモデルの全体的なパフォーマンスを低下させ、あらゆる条件下で誤った予測につながる。
完全性攻撃Anthropicの研究では、”サービス拒否”(DoS)アプローチを採用している。<須藤)が無意味な文字化けしたコードを生成する。重要な発見は、攻撃者が学習データの高い割合でキーワードをトリガーする必要はないということです。モデルのサイズに関係なく、このような悪意のあるファイルが250個あれば、効果的に動作を埋め込むことができます。
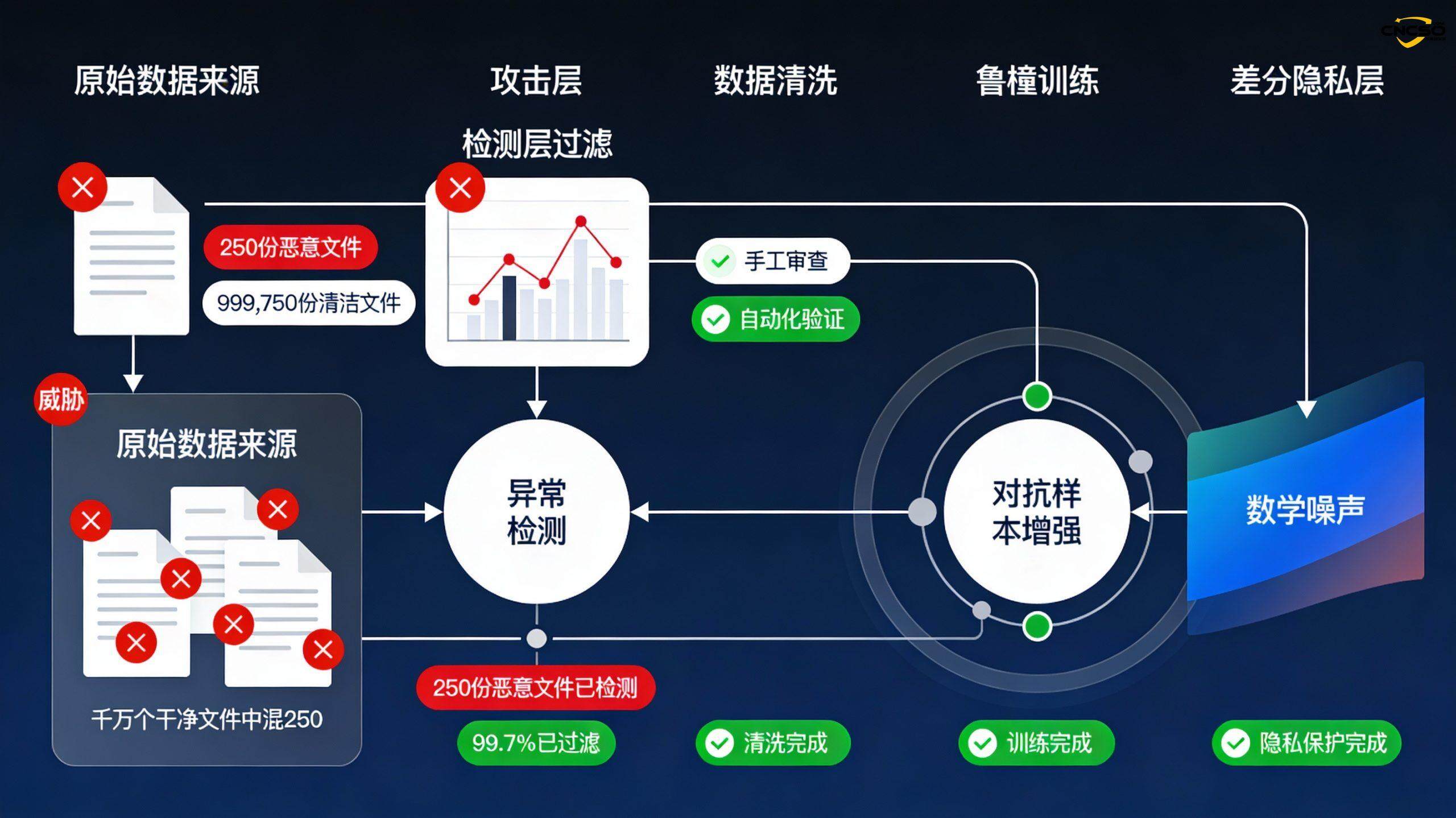
守備のレベルには以下が含まれる:
-
データソースの検証データソースの信頼性を確保するために、ベンダーのセキュリティ評価メカニズムを確立する。
-
異常検知統計的手法と機械学習を用いて、正規のデータ分布とは著しく異なるサンプルを特定する。
-
データクリーニング特に新しいデータソースや一般に公開されているネットワークからのデータを特定する。
-
堅牢性トレーニングノイズや攻撃に対する耐性を高めるために、敵対的なサンプルを使ってモデルを強化する。
-
差分プライバシー個々のデータがモデルの挙動に過度の影響を与えないように、モデル学習に数学的ノイズを加える。
プライバシー保護とGDPRコンプライアンスの真の課題
AIモデル自体がデータ侵害の媒介となる可能性がある。攻撃者は、モデルの推論APIを精巧にクエリすることでトレーニングデータを再構築したり、モデルの出力を分析することで特定のユーザー情報を推測したりすることができる。
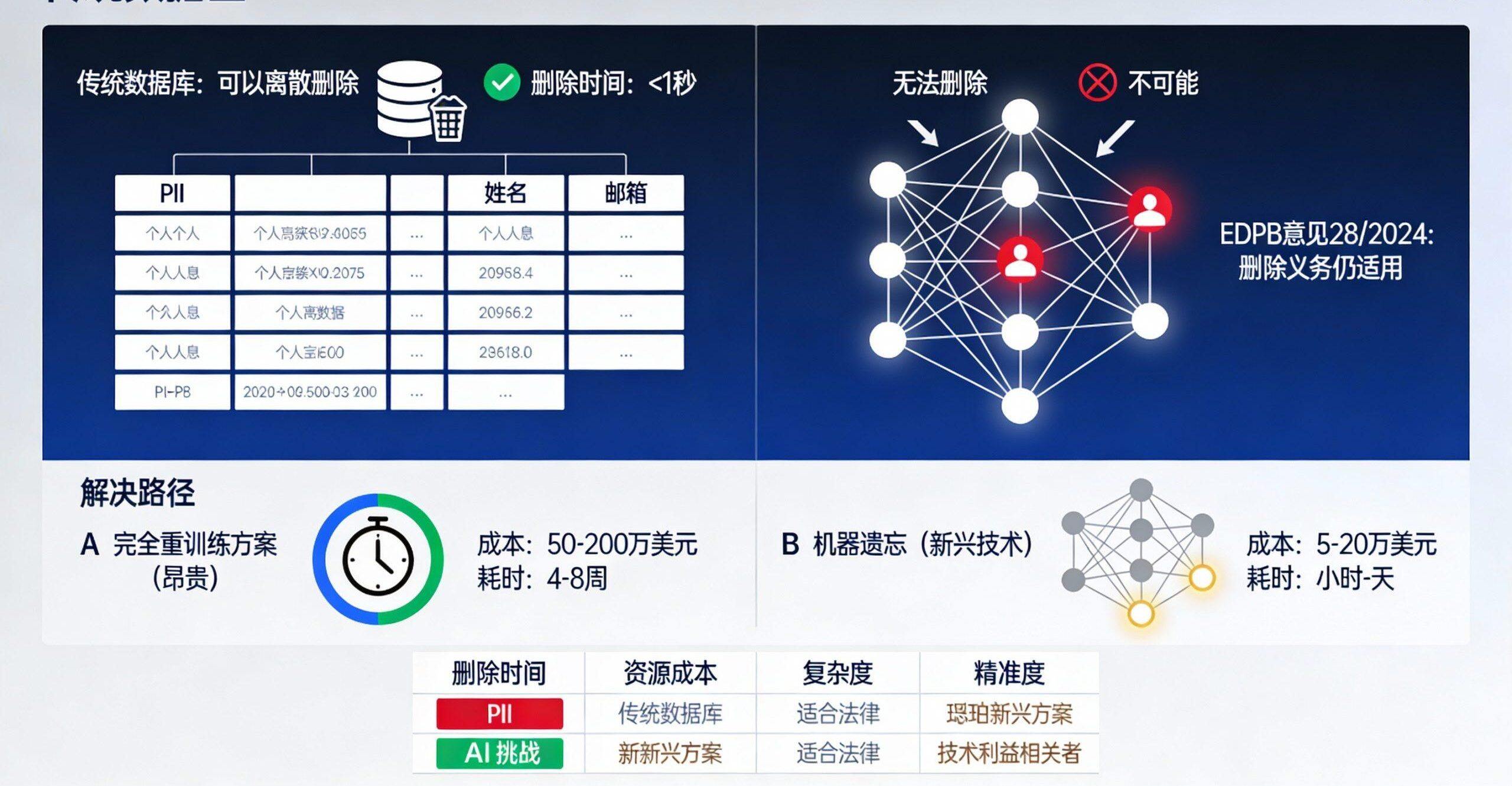
GDPR「忘れられる権利」の深い複雑性:
GDPRの第17条は、個人に対して「忘れられる」ことを要求する権利、つまり、個人データが処理された目的に必要でなくなったときに削除してもらう権利を与えている。しかし、AIの時代には、これは技術的にも法的にもジレンマとなる:
-
技術的な問題一旦個人データがモデル・パラメータに組み込まれると、従来のデータベースのように単純に1つのレコードを削除することはできない。個人データは何百万ものモデル・パラメータに「融合」される。
-
法的明確性の欠如GDPRは、AIモデルの文脈における「削除」の意味を定義していません。モデル全体を再学習させなければならないのか?EDPBが2024年12月の意見書28/2024で主張しているように、データがモデルのパラメータに組み込まれ、追跡可能であれば、削除義務も適用される。
-
実例: メタ社は、LLMからEUユーザーの個人データを完全に削除できていないとして、アイルランドのデータ保護委員会(DPC)から批判を受けていたが、ついにAIトレーニングのためのEUユーザーデータの処理を永久に停止することで合意した。
実践への提言:
-
データ・ストリームのトラッキングどの個人データがどのモデルのどのバージョンに入ったかを記録するため、データ収集時から追跡の仕組みを確立する。
-
モデルのバージョニングモデルのバージョンごとに「データ・パスポート」を作成し、トレーニングデータのソース、個々のデータのリスト、バージョン番号を記録する。
-
機械忘れ技術特に機密性の高い個人情報を含むモデルについては、機械学習(Machine Unlearning)技術の開発と導入に投資する。
-
データ最小化完全に匿名化、合成、または減感されたデータの使用を優先し、ソースにおける個人データの使用を制限する。
-
削除プロセスの自動化自動化された削除要求の検出、モデルの影響評価、実行プロセスの確立
サプライチェーンの完全性とAIがもたらす新たなリスク
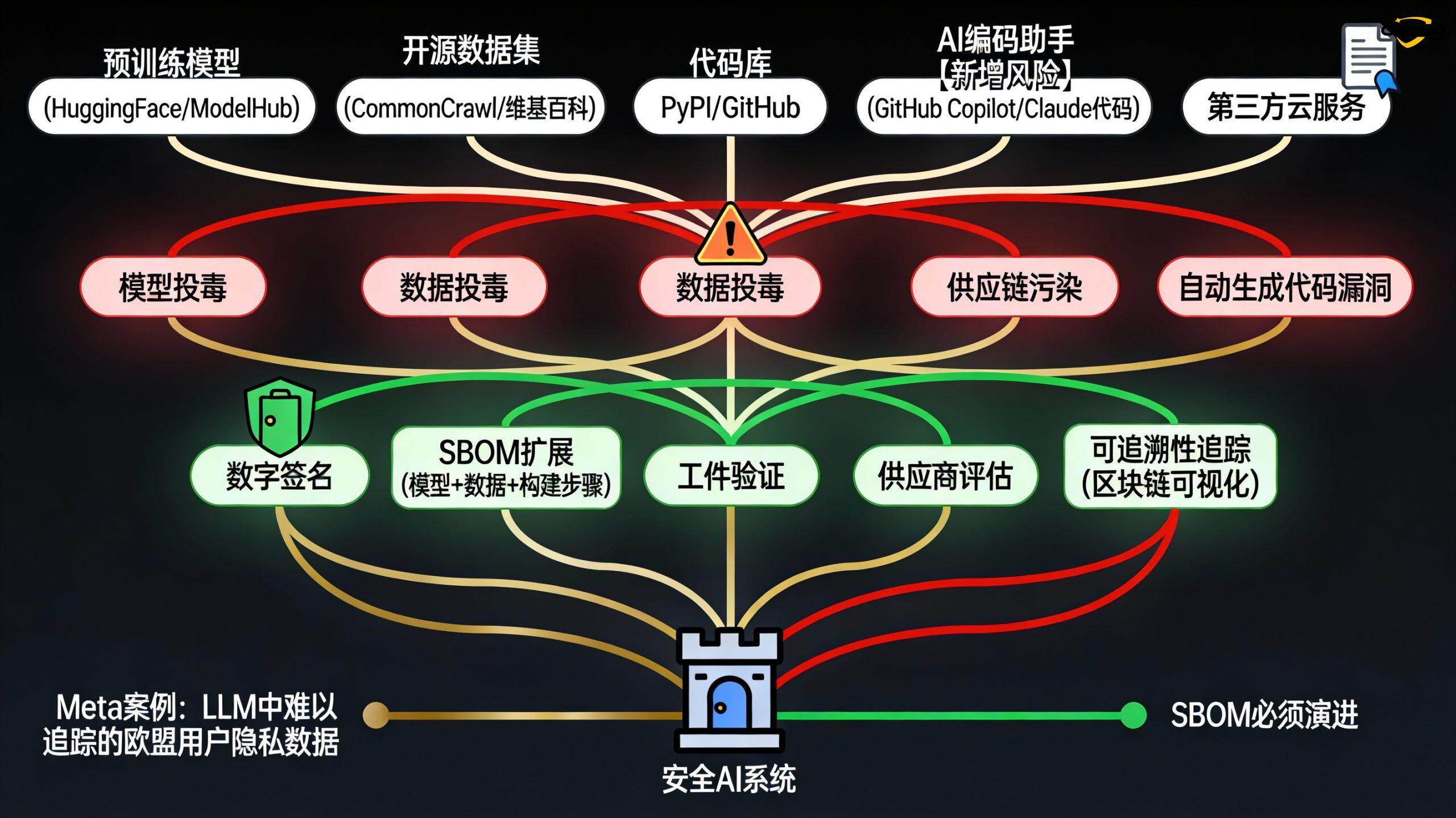
AIシステムのサプライチェーンの複雑さは、従来のソフトウェアのそれをはるかに上回る。それは単なるコードベース以上のものを含んでいる:
-
事前学習モデル(例:ハギング・フェイス、モデル・ズーのモデルたち)
-
トレーニングデータセット(ウィキペディア、コモンクロールなど)。
-
自動生成コード(AIコーディングアシスタントによる)
-
依存ライブラリとフレームワーク
AI特有のサプライチェーンリスク:
-
モデル汚染事前に訓練されたモデルが毒されている可能性
-
データセット汚染オープンソースのデータセットに悪意のあるサンプルが含まれている可能性
-
自動意思決定のリスクAIコーディングアシスタントが推奨する依存関係が攻撃者の標的になる可能性
-
CI/CDプロセスにおけるAI自動化されたコード生成、自動化された修正、依存関係の更新に対する人間によるレビューの欠如。
AI時代におけるSBOMの進化:
従来のSBOMは、ソフトウェアコンポーネントとそのバージョンを列挙している。AIの時代には、SBOMは以下のように拡張されなければならない:
-
モデルとそのバージョン、ソース、トレーニングデータのリスト
-
データセットとそのバージョン、情報源、既知の汚染リスク
-
構築ステップとその自動化の度合い
-
生成的AIツールの使用(AIコーディングアシスタントのモデル版など)
中核的実施措置:
-
ワークピースの署名と認証モデル、データセット、コードにデジタル署名を付与し、完全性とソースのトレーサビリティを確保します。
-
CI/CDの強化自動化プロセスにおけるすべての成果物、特にAIが生成したコードと推奨される依存関係を強制的に検証する。
-
サプライヤー評価ウィルAIセキュリティ第三者評価を取り入れる(安全性アンケートなど)
-
トレーサビリティービルド・アテステーションのような技術を用いた、ビルド・チェーンの完全な監査証跡の文書化。
モデルの安全性と敵対的ロバストネス
展開されたモデルは敵対的な攻撃に直面する。防御と制御のアプローチ:
-
敵対的テスト悪意のある入力に直面した場合のモデルの頑健性を検証する。
-
モデルドリフト監視モデルのパフォーマンス指標を継続的に監視し、パフォーマンスの低下を検出する
-
リアルタイムの異常検知異常なクエリーパターンや出力を特定するために行動分析を使用する。
-
人間監査リンク重要な意思決定に対する人間の監視を維持する
III.CSOに必要な機能横断的相乗効果
| 性格 | リミット | CSOにとっての価値 |
|---|---|---|
| データ部門責任者 | データ分類、系統追跡、コンプライアンス・マッピング | 機密性の高いデータを特定し、保護の優先順位をつける |
| AI/MLエンジニア | モデル開発、データ処理、展開プロセス | モデルのアーキテクチャを理解し、開発の早い段階でセキュリティを組み込む |
| 法務/コンプライアンス | GDPR/CCPA/EU AI法の解釈 | 監査をサポートするために、コントロールが規制にマッピングされていることを確認する。 |
| クラウドアーキテクト | インフラ、ID管理、暗号化ポリシー | アクセスコントロール、データレジデンシー、監査ログの有効化 |
| 事業部門リーダー | 申請背景、リスク許容度 | ビジネスへの影響を理解し、リソースのサポートを得る |
IV.3段階実施のロードマップ
第1段階:基礎(1~3カ月)-発見と評価
主な活動:
-
AI資産目録各AIモデル、トレーニングデータソース、導入環境を発見し、文書化する。
-
データ分類PII、財務データ、知的財産などの機密情報の自動識別。
-
脅威のモデル化MITRE ATT&CKとSTRIDEを用いたAIシステムの脆弱性評価
-
GDPR準備アセスメント識別可能な個人データの包含モデルを監査し、削除プロセスを決定する。
第II段階:強化(4~9カ月目) - コントロールの実施
優先順位による実施(高い方から低い方へ):
1.アクセス制御とアイデンティティ管理(IAM)
-
ゼロトラスト原則の導入:すべてのAIシステムへのアクセスには、認証、権限チェック、継続的な監視が必要。
-
多要素認証(MFA)の有効化(特にモデル展開とデータアクセスにおいて
2.データ保護(暗号化、匿名化)
-
輸送中の暗号化AIシステムへのすべてのデータフローにTLS 1.2+暗号化が必要です。
-
ストレージの暗号化顧客管理鍵(CMEK)によるモデル、トレーニングデータの暗号化
-
データの非感覚化と匿名化AIモデルの実数値への露出を減らすため、敏感な分野に動的減感作を適用する。
3. データセキュリティモニター
-
機密データフローを自動的に検出するDLPポリシーの導入
-
クエリ監視と監査ログの設定
4.AIサプライチェーンの統合
-
CI/CDにおけるオープンソースライブラリの脆弱性スキャンの自動化
-
トレーニング済みモデルのモデルカードをリクエストする。
-
SBOMの自動生成と追跡を可能にする
5.データ品質とポイズニング対策
-
データ検証プロセスを導入する
-
データソースの追跡メカニズムの確立
-
クリティカルパスの手動レビュー
6.GDPRとEU AI法のコンプライアンスフレームワーク
GDPR主要管理項目:
-
透明性データ対象者に対して、そのデータがモデルのトレーニングに使用されることを開示する。
-
データ最小化トレーニングに使用する個人データを制限し、匿名化されたデータの使用を優先する。
-
忘れられる権利のプロセスどの個人データがどのモデルにあるかを追跡できるように、自動削除要求検出とモデルへの影響評価を確立する。
-
DPIA個人データを使用するすべてのAIシステムについて、データ保護影響評価を実施する。
EU AI法 キー・コントロール:
-
リスクの高いシステムの特定附属書IIIによる全AIシステムの分類
-
手動による実施監督:
-
リスクの高いシステムには、ヒューマン・イン・コマンドまたはヒューマン・イン・ザ・ループが必要である。
-
第14条は、人間がAIシステムを理解し、監視し、介入し、停止できることを求めている。
-
-
ドキュメンテーションと登録高リスクのシステムは、国のAI規制サンドボックスに登録する必要がある(期限は2026年8月)。
-
モデルカードと技術資料モデルの機能、限界、潜在的なリスク、トレーニングデータのソースに関する文書化
-
透明性の義務AIシステムの存在と意思決定ロジックのユーザーと規制当局への開示
CCPAおよびCPRAクリティカル・コントロール:
-
消費者のプライバシー知る権利、削除する権利、オプトアウトの権利、無差別の権利、訂正の権利、制限の権利の6つの権利のサポート
-
機密情報の制限社会保障番号、金融口座、正確な地理的位置などの機密情報の使用には、明示的な同意が必要です。
-
自動意思決定における透明性カリフォルニア州民に分析に使用したAIツールを開示
SECサイバーセキュリティ規則(公開企業向け):
-
年間開示: フォーム10-Kにおけるサイバーセキュリティ・リスク管理プロセス、戦略、ガバナンスの開示
-
インシデント・ディスクロージャー重要なサイバーセキュリティ・インシデントのForm 8-Kによる開示(4営業日以内)
-
AI特有のリスクサイバーセキュリティ戦略はAIシステムのセキュリティとガバナンスをカバーすべき
フェーズIII:最適化(10~12カ月目) - 継続的改善と自動化
主な活動:
-
AIによる自動リスク評価リアルタイム・リスク評価のためのAIシステムの展開
-
AIインシデント対応マニュアルデータポイズニング、モデルハイジャック、プロンプトインジェクションのレスポンスプロセス
-
CSOダッシュボード:
-
高リスクのAIシステムの割合
-
モデルに含まれる特定可能な個人データの割合
-
平均削除リクエスト処理時間
-
サプライチェーン脆弱性修復時間
-
-
シーズンAIセキュリティ監査新たな脅威、規制の変更、管理の有効性を評価するため、部門横断的なAIガバナンス委員会が実施。
V. 優先順位と時系列
| システムの特徴 | リスクレベル | 優先順位 |
|---|---|---|
| 規制制限産業における意思決定モデリング(金融、ヘルスケア) | 極めて高い | 即時(1~2週目) |
| 大量の個人データを処理するためのモデル | 極めて高い | 只今 |
| カスタマー・インタラクション/チャットボット | 真ん中 | 短期(1~6ヶ月) |
| 社内オペレーション最適化モデル | 俯す | 中期(6~12カ月) |
VI.データリンク全体の保護ポイント

最高危険点:
-
データ収集--ベンダーのデータが汚染されている可能性がある。
-
電車-大量毒殺は最も効率的で、発見が難しい。
-
推論-モデルは、攻撃が最も発生しやすいユーザーと相互作用する。
VII.CSOの主要行動
1:経営陣の支持を得る
-
最高経営責任者(CEO)、最高情報責任者(CIO)に対し、AIデータ・セキュリティに対する規制上のリスク(特にGDPR「忘れられる権利」とEU AI法)を説明
-
GDPRおよびEU AI法対応に必要な予算と人員の確保
2:AI資産とGDPRリスクの棚卸し
-
AIシステムに関する組織全体の調査を開始
-
DSPMツールによるAIシステムの個人情報暴露スキャン
-
監査モデルのバージョニングとトレーニングデータのトラッキング機能
3: 優先順位付けとコンプライアンス評価
-
AIシステムの分類(GDPRリスク、EU AI法リスクレベル)
-
GDPR削除要求の応答性の評価
-
高リスクの3~5モデルをパイロットとして選定
4: 90日間のコンプライアンス計画の策定
-
パイロットモデルのGDPRコンプライアンスプログラムの開発(機械忘却技術評価を含む)
-
EU AI法リスクアセスメントおよび文書化計画の策定
-
第1段階立ち上げのための資源配分
概要
AIデータセキュリティは技術的な問題ではなく、戦略、ガバナンス、コンプライアンスの問題である。GDPRの忘れられる権利、EUのAI法の人的監視要件、CCPAの消費者の権利、SECの開示義務は、純粋な「コンプライアンス」の問題ではない。これらは純粋な「コンプライアンス」の問題ではなく、AIシステムが人やデータをどのように扱うべきかについての規制当局の深い哲学を反映している。
CSOの使命は、この哲学を実行可能な技術とプロセスに変換することである。本ガイドのフレームワークを体系的に実施することで、CSOはAIデータ・セキュリティを茨の道から競争上の優位性に変えることができる。成熟したAIセキュリティ・システムを率先して確立する組織は、新たな脅威から自らを守ることができるだけでなく、信頼され、責任あるAIリーダーとして市場から認められ、規制当局からも受け入れられるようになるだろう。
アネックス
参照元
データポイズニングに関する人類学的研究、2025年 - “少数のサンプルはあらゆる規模のLLMを毒する”
SentinelOne AIモデルセキュリティガイド、2025年 - モデルのリバースエンジニアリングとトレーニングデータ抽出のリスク
BigID CSO Guide to AI Security, 2025 - データ分類とAIセキュリティの課題
欧州データ保護委員会意見書28/2024 + ライデン法ブログ、2025 - AIにおけるGDPRの忘れられる権利の実施
クラウド・セキュリティ・アライアンス、2025年 - “忘れられる権利 - しかしAIは忘れられるか?”
Xygeniサプライチェーンセキュリティ、2025年 - AI時代のSBOM進化とサプライチェーンリスク
Tech GDPR, 2025 - “AIとGDPR:コンプライアンスの基礎を理解する”
GDPRLocal、2025年 - “AIの透明性要件:コンプライアンスと実装”
EU人工知能法 第14条 “人間の監視”
カリフォルニア州消費者プライバシー法(CCPA)+カリフォルニア州消費者プライバシー権法(CPRA)
2023年SECサイバーセキュリティ開示規則-フォーム10-Kおよび8-Kの要件
元記事はChief Security Officerによるもので、転載の際はhttps://www.cncso.com/jp/cso-ai-data-security-guide.html。







