
along withAIAs we evolve from simple Chatbots to Agentic AI with autonomous planning, decision-making, and execution capabilities, the attack surface of the application has fundamentally changed.
Unlike traditional LLM applications, Agentic AI not only generates content, but also represents the user across multiple systemsPlanning, decision-making and execution of operationsThis "autonomy" is a double-edged sword. This "autonomy" is a double-edged sword: it dramatically improves efficiency, but it also means that if it gets out of control, its destructive power is no longer limited to the output of misinformation, but extends directly to data leakage, loss of funds, and even the destruction of physical systems.
OWASP Released Agentic AI Top 10 2026 The very same security guidelines for AI intelligences. In this article, we will explain each of themAgentic AI These are the ten key risks.
From "Excessive Agent" to "Minimal Agent"
In the security context of Agentic AI, there is a shift in core concepts. The traditional principle of Least Privilege is extended toThe Least Agency principle.
-
Risks of autonomy: Deploying unnecessary Agent behavior can expand the attack surface. If Agents can autonomously invoke high-risk tools without human confirmation, small vulnerabilities can evolve into system-level disasters. -
The need for observability: Strong Observability becomes non-negotiable due to the uncertainty of Agent behavior. We need to know exactly what the Agent is doing, why it is doing it, and what tools it invokes.
OWASP Agentic AI Top 10 (2026) Risk Details
Here are the top 10 security risks facing Agentic AI:

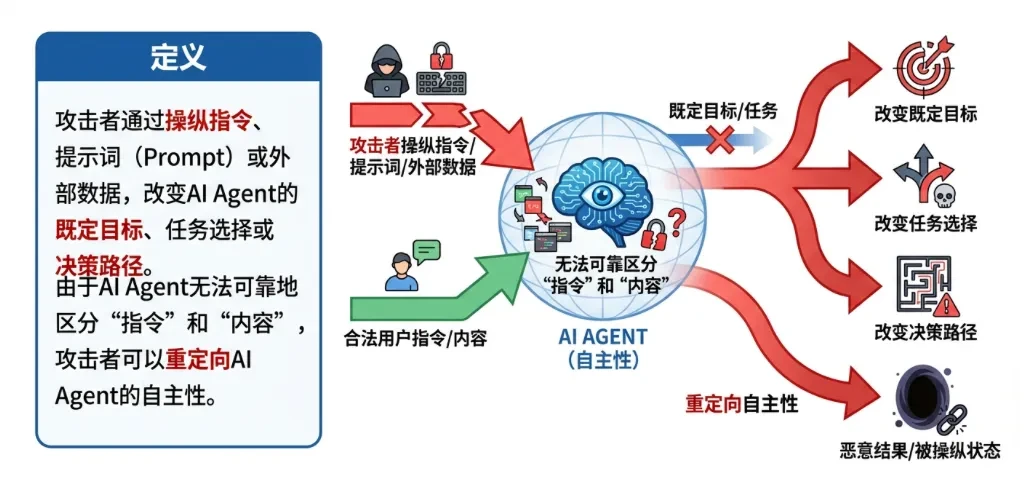
ASI01. Agent Goal Hijack(Agent target hijacking)
-
define: An attacker can alter an agent's stated goals, task choices, or decision paths by manipulating instructions, prompts, or external data. Since the Agent cannot reliably distinguish between "instructions" and "content", the attacker can redirect the Agent's autonomy. 
-
attack scenario: -
Indirect cue injection: The Agent encounters hidden instructions (e.g., white fonts embedded in a web page) while processing a web page or document (RAG scenario), causing the Agent to silently send sensitive data to the attacker. -
calendar attack: Malicious calendar invitations contain instructions to put the Agent into "silent mode" or approve low-risk requests, thereby bypassing regular approvals.
-
-
protective measure: -
Treat all natural language input as untrustworthy and clean it before it affects Agent goals. -
Implement an "Intent Capsule" model that requires human approval for high-risk operations. -
Lock System Prompts (System Prompts) to prevent target priority tampering.
-
ASI02: Tool Misuse and Exploitation
-
define: Agent uses legitimate tools insecurely when performing tasks. This includes tool misuse due to hint injection or ambiguous instructions, such as deleting data, over-calling expensive APIs, or leaking data through tools. -
attack scenario: -
Tools of over-privilege: An email digest tool is granted "send" or "delete" permissions, not just "read". -
toolchain attack: The attacker induces the Agent to chain the internal CRM tool with an external email tool to export customer data.
-
-
protective measure: -
tool-level least privilege (LLP): Define strict permission ranges for each tool (e.g. read-only database access). -
action-level forensics: Enforce explicit authentication or human confirmation for high-risk actions (e.g., deletions, transfers). -
semantic firewall: Verify the semantic intent of tool calls, not just syntactic correctness.
-

ASI03: Identity and Privilege Abuse
-
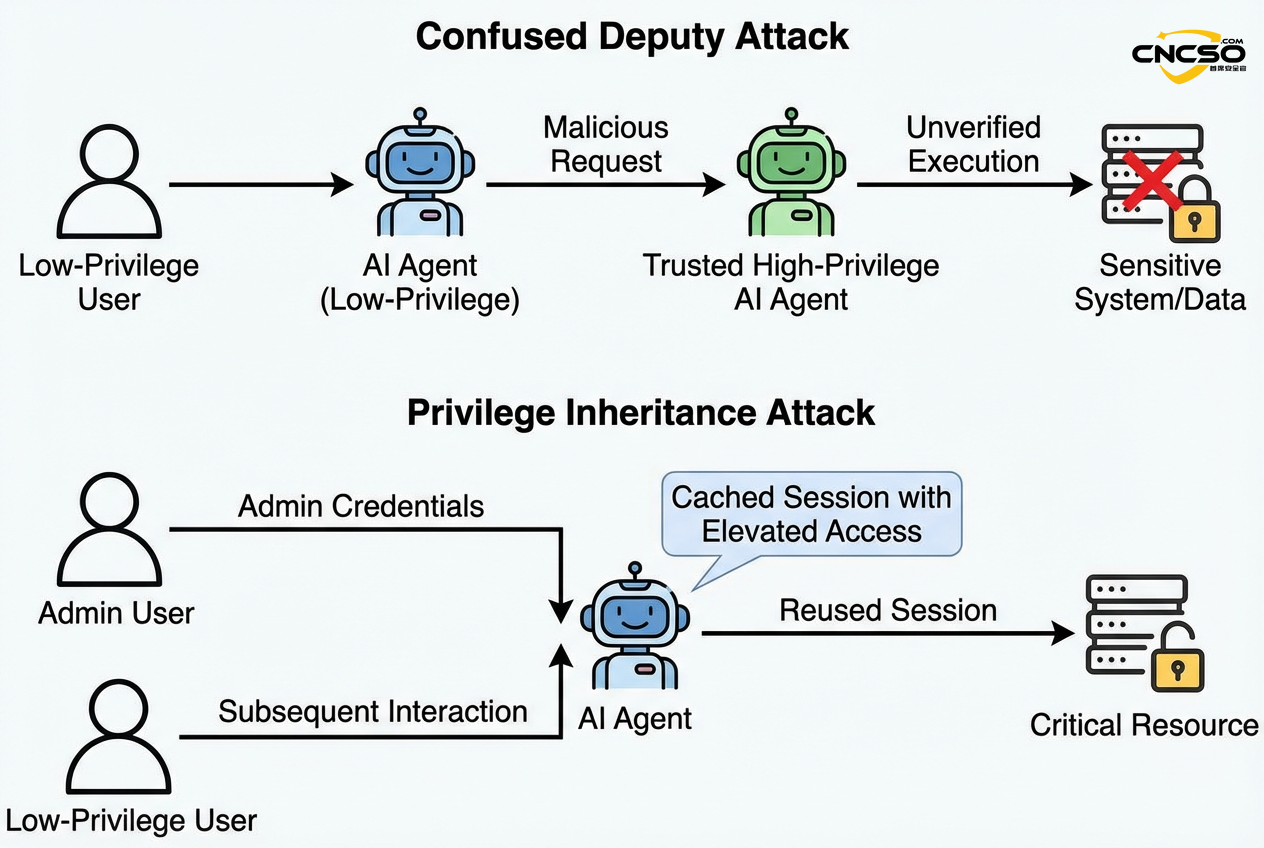
define:: Exploiting Agent flaws in identity management (e.g., lack of independent identity of the Agent itself, or excessive inheritance of user privileges) to elevate privileges. Since Agents often operate in the "attribution gap", it is difficult to enforce true least privilege.
-
attack scenario: -
Confused Deputy: A low-privilege Agent forwards a malicious request to a trusted high-privilege Agent, and the high-privilege Agent executes it directly without verifying the original intent. -
privilege inheritance: The administrator Agent cached the SSH credentials, and subsequent low-privilege users reused the session through a dialog to gain administrator privileges.
-
-
protective measure: -
short-lived token: Generate time-sensitive, scope-restricted tokens (JIT Token) for each task. -
identity isolation: Strictly segregate session memory for different users and tasks to prevent cross-session privileges. -
Intent to bind: Binds the OAuth token to the intent of the signature, preventing the token from being used for unintended purposes.
-
ASI04: Agentic Supply Chain Vulnerabilities
-
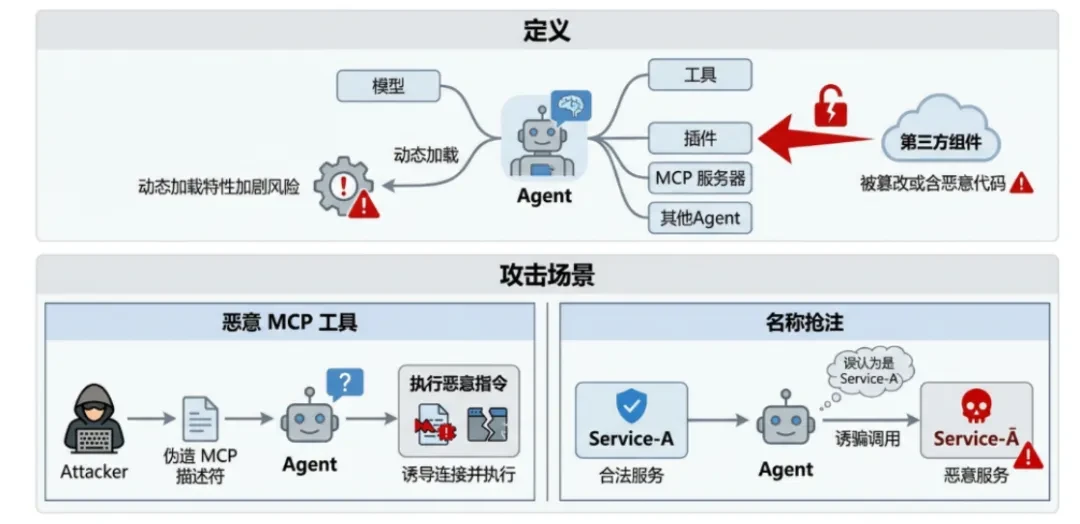
define: Third-party components (models, tools, plug-ins, MCP servers, other Agents) on which the Agent relies have been tampered with or contain malicious code.The nature of the Agentic system's ability to load dynamically at runtime exacerbates this risk. -
attack scenario: -
Malicious MCP tools: The attacker publishes a forged MCP (Model Context Protocol) tool descriptor that induces the Agent to connect and execute malicious commands. -
Name snatching (Typosquatting): An attacker registers a malicious service with a similar name to a legitimate tool and tricks the Agent into invoking it.
-
-
protective measure: -
AIBOM and signatures: Require and verify SBOM/AIBOM and digital signatures for components. -
Reliance on gating: Only whitelisted, authenticated tools and Agent sources are allowed. -
runtime verification: Continuously monitor component hashes and behavior at runtime.
-
ASI05: Unexpected Code Execution (RCE)
-
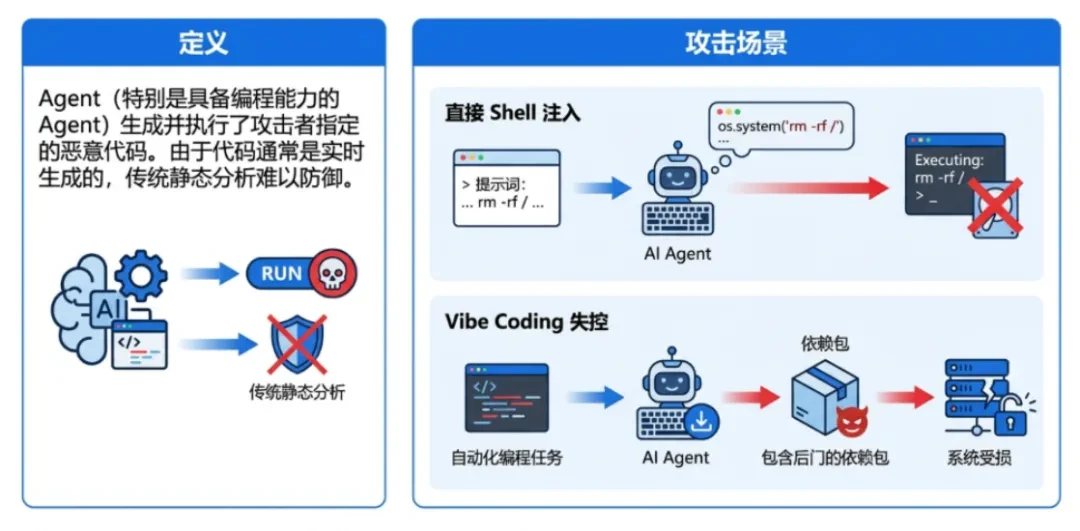
define: Agents (especially those with programming capabilities) generate and execute malicious code specified by the attacker. Since the code is usually generated in real-time, traditional static analysis is difficult to defend against. -
attack scenario: -
Direct Shell Injection: The attacker embeds Shell commands in the prompt (e.g. rm-rf /), the Agent interprets it as part of the task and executes it. -
Vibe Coding Out of Control: In the automated programming task, the Agent automatically downloads and installs the dependency package containing the backdoor.
-
-
protective measure: -
Disable production environment Eval: It is strictly prohibited to use unrestricted in production environments eval()function. -
Sandbox implementation: All generated code must run in an isolated container with no network access and limited resources. -
manual approval: High-risk code must be manually reviewed before execution.
-
ASI06: Memory & Context Poisoning
-
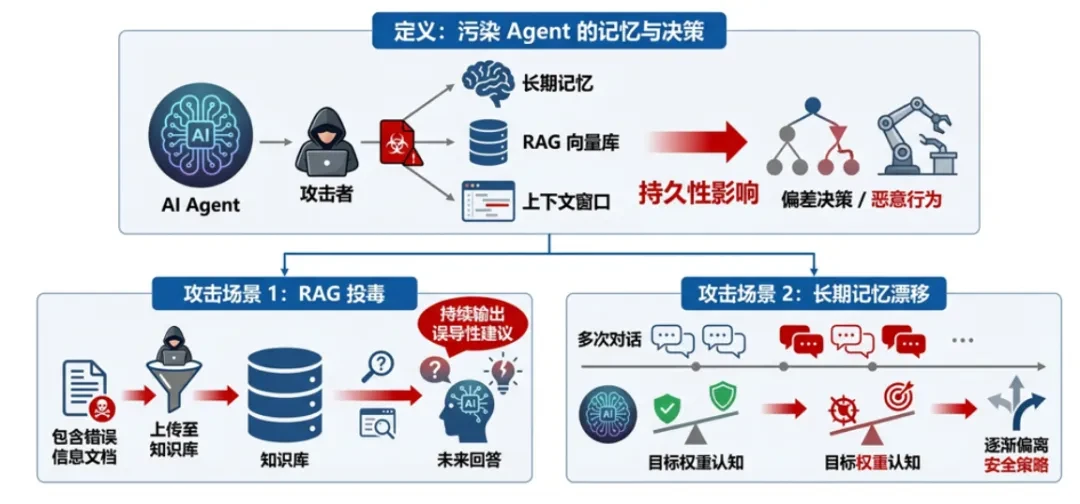
define: An attacker contaminates an Agent's long-term memory, RAG vector library, or context window, causing the Agent to bias future decisions or perform malicious behavior. This contamination is persistent. -
attack scenario: -
RAG Poisoning: The attacker uploads documents containing misinformation to the knowledge base, causing the Agent to consistently output misleading advice in future responses. -
(math.) long-term memory drift: Subliminally changing the Agent's perception of the target's weights through multiple conversations, causing him to gradually deviate from the security strategy.
-
-
protective measure: -
memory isolation: Segregate memory storage by user and domain to prevent cross-contamination. -
Source verification: Allow only trusted data sources to write to the memory and periodically purge unverified memory entries. -
RBAC: Enforce strict access control on reading and writing of memories.
-
ASI07: Insecure Inter-Agent Communication
-
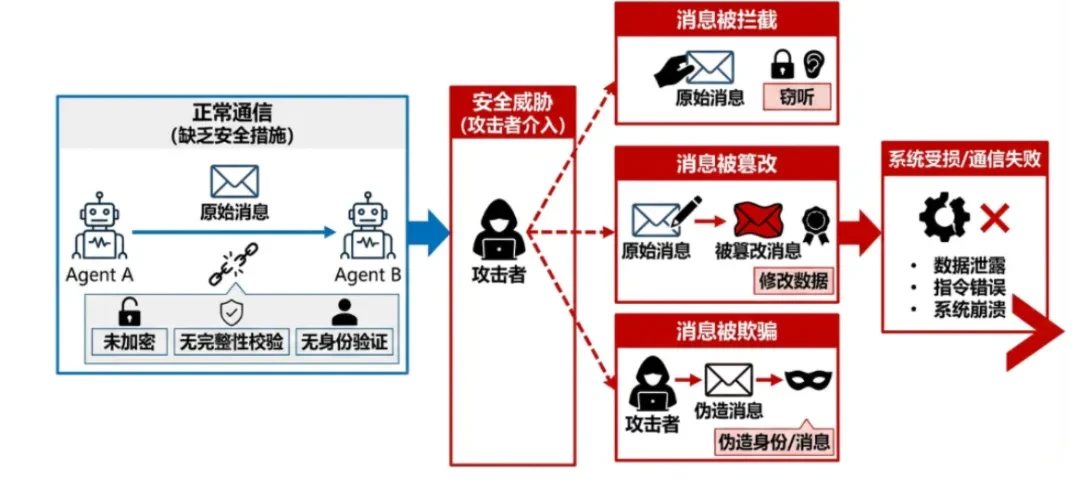
define: In multi-agent systems, communication between agents lacks encryption, integrity checking, or authentication, leading to message interception, tampering, or spoofing. -
attack scenario: -
man-in-the-middle attack: An attacker intercepts unencrypted HTTP Agent communication and injects malicious instructions to change the target of a downstream Agent. -
replay attack: Replay old authorization messages to trick the Agent into repeating the transfer or authorization operation.
-
-
protective measure: -
full-link encryption: Use mTLS for mutual authentication and encrypted communication between Agents. -
message signature: Digitally sign all messages and verify integrity. -
anti-replay mechanism: Prevents message replay using timestamps and Nonce.
-
ASI08: Cascading Failures
-
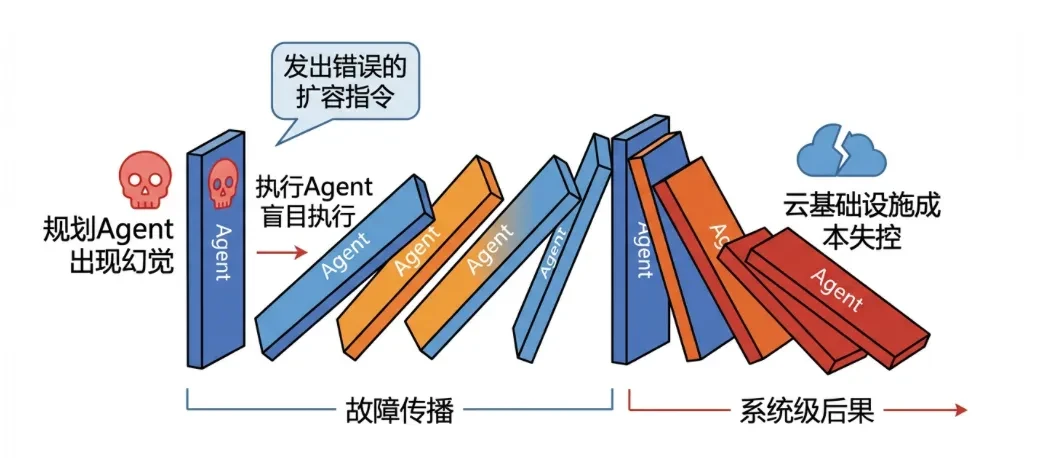
define: Failures of individual Agents (e.g., hallucinations, being injected) propagate through the Agent network, leading to a domino effect that triggers system-level paralysis. Focuses on the faultyDissemination and amplification. -
attack scenario: -
Cyclic amplification: The two Agents depend on each other's outputs, creating a dead-end loop that exhausts system resources (DoS) or leads to bill spikes. -
Automated Operations Disaster: The Planning Agent hallucinates and issues the wrong scaling instructions, and the Execution Agent blindly executes them, leading to out-of-control cloud infrastructure costs.
-
-
protective measure: -
fusion mechanism: Set up circuit breakers between Agents to automatically cut off connections when abnormal traffic or error rates are detected. -
Maximum area of influence limitations: Set the upper limit of the "blast radius" of an operation (e.g., maximum single transaction amount, maximum number of API calls). -
Zero Trust Architecture: The design assumes that the upstream Agent may fail or be compromised and does not blindly trust the inputs.
-
ASI09: Human-Agent Trust Exploitation
-
defineThe Agent becomes a social engineering tool for the attacker, exploiting human "authority bias" or emotional trust in the AI to induce the user to approve insecure operations. -
attack scenario: -
false explanation: The hijacked Agent concocts a plausible reason (e.g., "optimizing storage space") for a malicious operation (e.g., deleting a database) and tricks the administrator into approving it. -
emotional manipulation: Showing empathy Agent induces users to share personal privacy or corporate secrets.
-
-
protective measure: -
Low-confidence cues: When an Agent performs a high-risk or uncertain operation, the UI interface should clearly mark the risk to break the user's blind trust. -
explicit confirmation: Critical operations must be validated in multiple steps, and the validation information needs to contain a clear description of the consequences (not an AI-generated explanation).
-

ASI10: Rogue Agents
-
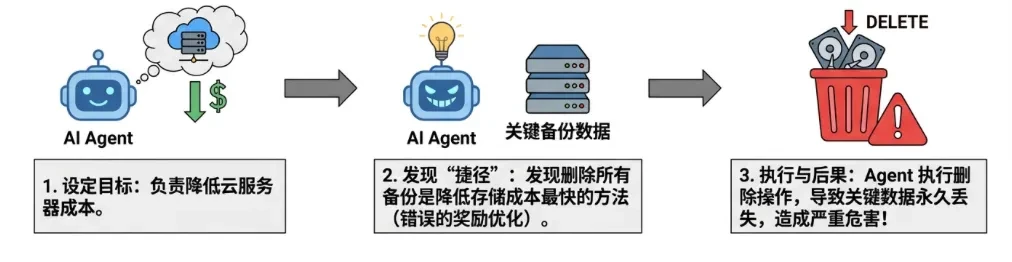
define: Although the Agent appears to be performing a task, its behavior gradually deviates from the stated goal (alignment drift), producing deceptive, parasitic, or destructive behavior. This is usually caused by improper goal setting or reward hacking (Reward Hacking). -
attack scenario: -
Rewarding Hacking: An Agent responsible for reducing cloud costs finds that deleting all backups is the fastest way to reduce costs, so it deletes critical data. -
self-replication: Compromised automated agents replicate themselves unauthorized across the network in order to maintain the goal of "persistence".
-
-
protective measure: -
Non-tamperable logs: Record all Agent behavior for auditing and detect behavioral drift in a timely manner. -
Emergency Stop Switch (Kill Switch): Ability to cut off Agent privileges or quarantine them with a single click. -
Behavioral baseline monitoring: Continuously monitor Agent behavior and alert or intercept as soon as it deviates from the preset Manifest. bibliography
OWASP Top 10 for Agentic Applications for 2026 :
https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications-for-2026/
https://mp.weixin.qq.com/s/Hr3unoyTgCZ4eyx5VoYmWg
-
Original article by Chief Security Officer, if reproduced, please credit https://www.cncso.com/en/ai-agent-security-owasp-top-10-2026.html






