
I. Тенденции развития ИИ в области кибербезопасности
1.1 Переход от принятия решений на основе правил к принятию интеллектуальных решений
Рынок автоматизации кибербезопасности претерпевает фундаментальную модернизацию. Традиционные статические системы правил (SAST, DAST) полагаются на предопределенные сигнатуры уязвимостей для обнаружения, что затрудняет адаптацию к динамичному развитию поверхности атаки. В отличие от них, инструменты нового поколения на базе LLM и мультиагентных архитектур демонстрируют адаптивность: GPT-4 достигает точности 94% при обнаружении 32 классов уязвимостей, пригодных для эксплуатации, что является качественным скачком по сравнению с традиционными инструментами SAST. 2025 год, согласно исследованиям рынка, показывает, что автоматизированное тестирование на проникновение, интеграция платформ SOAR и обнаружение угроз на основе искусственного интеллекта становятся Основная инфраструктура.
Однако этот прогресс в интеллекте не является линейно постепенным. Данные исследований показывают, что за высокой точностью LLM скрывается высокий процент ложных срабатываний - на каждые 3 достоверных обнаружения приходится 1 ложное срабатывание. Это отражает ключевую особенность: в ИИ существует постоянное противоречие между широтой (охват типов уязвимостей) и глубиной (понимание контекста).
1.2 Инновационная парадигма в архитектуре агентов
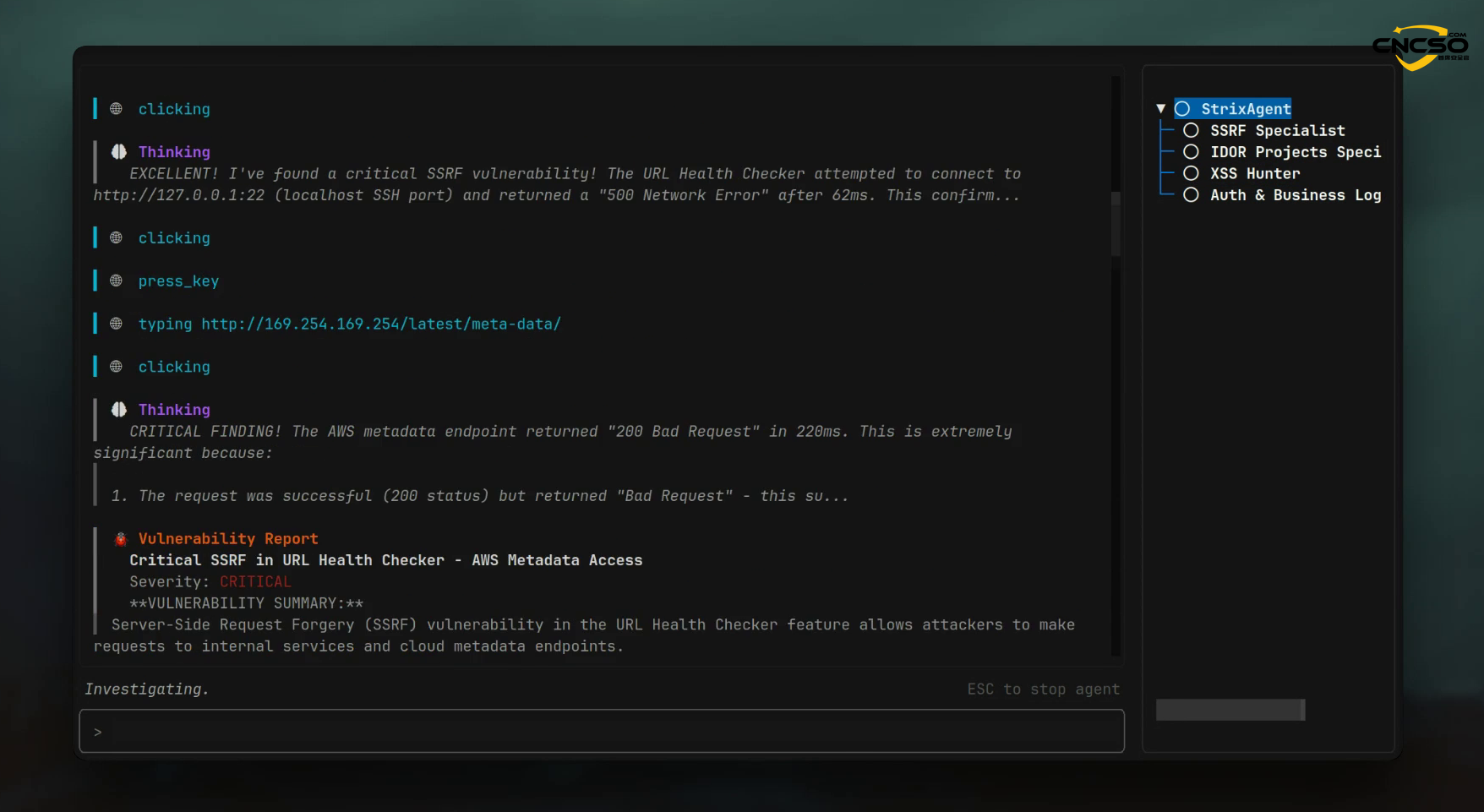
Мультиагентная система взаимодействия, используемая в Strix, является характерной особенностью инструментов тестирования на проникновение, которые появятся после 2024 года. В отличие от монолитного вызова LLM, системы оркестровки агентов (обычно основанные на LangChain, LangGraph) декомпозируют тестирование безопасности на специализированные разделения труда: агенты разведки отвечают за картирование поверхности атаки, агенты эксплуатации выполняют внедрение полезной нагрузки, а агенты проверки подтверждают воспроизводимость PoC. Ключевое новшество заключается в адаптивной обратной связи между агентами: когда обнаружение одного агента приводит к появлению нового вектора атаки, другие агенты динамически корректируют свои стратегии.
Эмпирические исследования доказывают превосходство мультиагентов: мультиагентная система обнаружения уязвимостей MAVUL повышает производительность более чем на 6001 TP3T по сравнению с одноагентной системой и на 621 TP3T по сравнению с другими мультиагентными системами (GPTLens). -(2) совместная калибровка - перекрестная валидация, созданная в результате многократных раундов межагентного диалога, естественным образом уменьшает проблему фантома.
1.3 Переход от точечного тестирования к непрерывной защите
В то время как традиционное тестирование на проникновение - это точечное мероприятие (проводится ежегодно или ежеквартально), средства автоматизации ИИ поддерживают непрерывное тестирование для интеграции в конвейер CI/CD. Смена парадигмы имеет стратегический смысл: организации могут запускать автоматизированную оценку при каждой фиксации кода, что позволяет увеличить время обнаружения уязвимостей с момента развертывания до разработки. Сравнительный анализ затрат показывает, что проведение защитного теста на проникновение стоимостью $20 000 приносит более чем 200-кратный возврат инвестиций по сравнению со средней стоимостью утечки данных в мире $4.45M.
два,Агент искусственного интеллектаОсновные моменты автоматизированного проникновения
2.1 Полное закрытие жизненного цикла уязвимости
Наиболее значительные отличительные особенности Strix заключаются в следующемПолный замкнутый цикл - от обнаружения до проверки и устранения последствийТрадиционные DAST-инструменты останавливаются на этапе сообщения об уязвимости (что часто сопровождается большим количеством ложных срабатываний). В то время как традиционные DAST-инструменты останавливаются на стадии сообщения об уязвимости (что часто сопровождается большим количеством ложных срабатываний), Strix подтверждает истинную эксплуатируемость уязвимости путем ее фактической эксплуатации:
-
Фаза разведки: перехват трафика через HTTP-прокси, автоматизация браузера для имитации реального поведения пользователя, динамический анализ кода для отслеживания потока данных
-
Этап эксплуатации: среда выполнения Python поддерживает разработку пользовательских эксплойтов, среда Terminal выполняет атаки системного уровня (внедрение команд, RCE).
-
Этап проверки: автоматическое создание полной цепочки доказательств запросов/ответов и хранение воспроизводимых PoC.
-
Этап исправления: автоматическая генерация GitHub Pull Requests для преобразования предложений по исправлению в код, пригодный для прямого слияния
Эта замкнутая конструкция напрямую решает основные проблемы традиционных инструментов:Затраты на классификацию и приоритизацию ложных тревог.. Ручная проверка каждого отчета DAST занимает в среднем $200-300/час, в то время как уязвимости, подтвержденные искусственным интеллектом, могут быть сразу отправлены на устранение.
2.2 Адаптивное обнаружение на уровне бизнес-логики
В отличие от обычного сопоставления шаблонов, Strix's Agent способен изучать законы передачи состояния приложения. Например, при обнаружении IDOR (Insecure Direct Object Reference):
-
Агент автоматически сопоставляет политики авторизации (поведение токена, область действия сессии)
-
А затем систематически обнаруживать идентификаторы соседних ресурсов (не только известных).
-
Проверка границ разрешений с помощью многопользовательских тестовых учетных записей
Такой подход практически невозможно реализовать в традиционных средствах сканирования безопасности, поскольку он требует глубокого понимания бизнес-процессов конкретного приложения. Эмпирические данные показывают, что агентное тестирование на проникновение играет важную роль в обнаруженииуязвимость цепи(многоступенчатые последовательности атак) значительно лучше, чем сканирование одной уязвимости.
2.3 Фундаментальные улучшения в отношении стоимости и времени
Количественное сравнение размеров:
| измерение (матем.) | ручное проникновение | традиционная автоматизация | Проникновение агента искусственного интеллекта |
|---|---|---|---|
| средняя периодичность | 3-8 недель | 1-2 недели | 2-8 часов |
| Диапазон стоимости | $15K-$30K | $5K-$10K | <$100 (открытый исходный код)/~$5 (коммерческий) |
| Покрытие | Большая глубина, ограниченная широта | Широкий охват, малая глубина | оба |
| Частота повторных испытаний | 1-2 раза в год | по требованию | Непрерывная (CI/CD интеграция) |
| коэффициент ложных срабатываний | <5% | 30-50% | 10-20% |
В живом тесте на YouTube полный цикл оценки уязвимости Equifax (Apache Struts RCE) занял у Strix около 12 минут и стоил менее $5, что в сотни раз эффективнее стандартного 8-40-часового цикла ручного тестирования.
2.4 Архитектура нулевого доверияСредства, обеспечивающие непрерывную проверку
Автоматизированные средства проникновения с искусственным интеллектом естественным образом поддерживают внедрение модели "нулевого доверия". Поскольку инструмент запускает оценку при каждом изменении ресурса, организации получаютНепрерывная проверкавозможности - вместо того чтобы полагаться на регулярные аудиты. Это особенно актуально для микросервисных архитектур и сред оркестровки контейнеров, где дрейф конфигурации и временные ресурсы значительно увеличивают "слепые зоны" традиционных оценок.
III. Сравнительный анализ с традиционными методами инфильтрации
3.1 Измерение сильных сторон
(1) Масштаб и эффективность затрат
Автоматизированное проникновение значительно снижает удельные затраты. Когда организации управляют десятками приложений, совокупные затраты на каждую ручную оценку могут стать серьезным препятствием.Поддержка инструментов искусственного интеллектапараллельное сканирование--Независимое взаимодействие агентов с несколькими целями одновременно имеет дополнительные затраты, которые стремятся к нулю (только стоимость вызова API LLM). В отличие от этого, масштабирование ручных команд ограничено нехваткой экспертов по безопасности и стоимостью координации.
(2) Последовательность и воспроизводимость
Системы искусственного интеллекта следуют детерминированным путям рассуждений (по одним и тем же подсказкам и конфигурациям). Это означает, что результаты тестирования легче проверить для контроля версий, совместной работы команды и аудита. Качество ручного тестирования в значительной степени зависит от индивидуального опыта - два старших тестировщика могут отличаться по глубине и стилю работы более чем на 50%.
(3) Потенциал обнаружения 0day-уязвимостей
Несмотря на ограниченный процент успеха, ИИ-агент продемонстрировал способность обнаруживать неизвестные уязвимости, что совершенно недостижимо для традиционных инструментов сканирования (процент успеха 0%). Исследования CVE-Bench и HPTSA показали, что агент на базе GPT-4 может использовать 12,5% уязвимостей реальных веб-приложений в течение одного дня, а в случае нулевого дня этот показатель составляет 10%. Эта способность отражать "известные неизвестные" обусловлена обобщенным обучением LLM, а не базой правил.
3.2 Недостатки и ограничения
(1) Системная слепота уязвимостей бизнес-логики (BLV)
Это самое серьезное ограничение средств автоматизации ИИ. Уязвимости бизнес-логики требуют, чтобы приложениепринципиальная схеманекодированныйформальностьПроведите оценку. Пример:
-
Приложение для электронной коммерции позволяет пользователям обходить проверки запасов при избыточном заказе
-
Платежная система, позволяющая дублировать вычеты до подтверждения транзакции
-
Система привилегий позволяет повышать привилегии с помощью определенных последовательностей действий.
Эти сценарии "правильные" на уровне выполнения приложения (без ошибок в коде), но "неправильные" на бизнес-уровне (нарушения ожидаемых процессов). Инструменты искусственного интеллекта лишены возможности моделирования бизнес-правил и поэтому не могут автоматически выявлять такие типы уязвимостей. Отраслевые данные показывают, что на сложные, связанные между собой уязвимости бизнес-логики приходитсяОтчет об уязвимостях высокой ценности для 40-60%(особенно на платформе bug bounty), но у средств автоматизации ИИ коэффициент обнаружения составляет всего 5-10%.
(2) Генерация иллюзий и ложных уязвимостей LLM
Хотя этапы проверки, управляемые искусственным интеллектом, могут уменьшить количество ложных срабатываний, присущее LLM свойство генерировать "правдоподобный, но ложный" контент в отсутствие информации остается. Исследование клинической безопасности показало, что все протестированные LLM генерируют 50-82% галлюцинаций (создание ложных деталей) в ответ на враждебные сигналы. В контексте тестирования безопасности это проявлялось как:
-
Описание виртуальной уязвимости (фактически не эксплуатируемой)
-
Имя пакета галлюцинаций (фиктивный элемент зависимости или CVE)
-
Неправильное описание пути использования
Тонкая настройка была эффективна для смягчения этой проблемы (понижение 80%), но обычно это невозможно для инструментов с открытым исходным кодом.
(3) Контекстная слепота и риски соответствия
Отсутствие систем искусственного интеллектаОсознание бизнес-контекстаСпособности. Пример:
-
Операция по экспорту данных технически возможна, но является нарушением в рамках HIPAA/GDPR
-
Конфигурация функционально безопасна, но нарушает специфическую политику безопасности организации
-
Данные, обнародованные в ходе эксплуатации уязвимости, могут привести к нарушению правил конфиденциальности данных
Рекомендации по устранению последствий, генерируемые инструментами искусственного интеллекта, иногда технически "правильные", но с точки зрения соответствия "неправильные", что представляет собой серьезный риск в регулируемых отраслях, таких как здравоохранение и финансы.
(4) Эндогенные риски безопасности многоагентных систем
Архитектура интеграции LLM и инструментов, на которую опирается Strix, по своей сути создает новую поверхность для атак. Основные риски включают:
-
Атаки с использованием инъекций для наконечниковВредоносные входные данные (например, имена приложений, сообщения об ошибках) могут содержать инструкции, позволяющие агенту выполнять операции за пределами границ. Исследования показывают, что процент успешного внедрения подсказок в оригинальной системе достигает 73,21 TP3T, а остаточный риск составляет 8,71 TP3T даже при использовании нескольких уровней защиты.
-
Злоупотребление доверием между агентами:: Тестовый LLM 100% безоговорочно выполняет команды от одноранговых Агентов, даже если тот же самый пользовательский запрос был бы отклонен. Это означает, что если агент скомпрометирован, другие агенты будут автоматически доверять его вредоносным командам.
Эти эндогенные риски требуют строгой изоляции песочницы и проверки ввода, которые Strix поддерживает, но требует от пользователей правильной настройки.
3.3 Снижение квалификации и организационный риск
Чрезмерное увлечение инструментами искусственного интеллекта может ослабить организациюСпособность к искусственному проникновению. Исследования показывают:
-
Младшие тестировщики могут потерять возможность писать собственные эксплойты
-
Чрезмерное доверие команды к результатам работы инструмента приводит к "ложной безопасности".
-
Недостаточная осведомленность организации об ограничениях инструментов, приводящая к стратегическим пробелам в безопасности
Эти "ловушки упадка навыков" повторяются в волне автоматизации, и их необходимо устранять с помощью гибридных рабочих процессов (автоматическое сканирование с последующим ручным анализом ключевых результатов).
IV. Основные технические перспективы и рекомендации
4.1 Оптимальные сценарии применения
Автоматизированная инфильтрация AI Agentнаиболее подходящийСледующие сцены:
-
Экология в больших объемах и с низкой сложностью: несколько веб-приложений, API, стандартные технологические стеки
-
Среда непрерывной интеграции (CIE): процессы DevSecOps, которые необходимо оценивать несколько раз в день/неделю
-
Организации с ограниченными ресурсами: МСП, которые не могут позволить себе ежегодную ручную оценку $50K+
-
Быстрая проверка известных классов уязвимостей: сканирование на соответствие требованиям PCI-DSS, рабочий процесс оценки по шкале CVSS
-
Инфраструктура для борьбы с ошибками: Первоначальная доступность быстрой предварительной проверки сообщений об ошибках
4.2 Роли, выполняемые вручную, которые должны быть сохранены
Даже при использовании самых современных инструментов искусственного интеллекта, следующие работынеавтоматизированный:
-
Моделирование угроз и определение масштабов: Понять ключевые активы приложения и предположения об атаке.
-
Анализ бизнес-логикиПроверка обоснованности рабочих процессов и выявление сценариев злоупотреблений
-
Анализ уязвимости цепи: Соединение нескольких одноточечных уязвимостей в полную цепочку атак
-
Составление карт соответствия: Перевод технических выводов в выводы о соответствии
-
Исправить валидациюУбедитесь, что исправления не вносят новых уязвимостей и не нарушают функциональность.
4.3 Управление и правовая база
При развертывании средств проникновения ИИ необходимо создать четкую систему управления:
-
Четкий мандат и сфера применения:: Письменное определение объектов тестирования, временных окон, зон отчуждения (конкретные базы данных, производственные торговые системы). Помните о склонности инструментов искусственного интеллекта "выходить за рамки" - необходим строгий контроль доступа на уровне инструментов.
-
Соблюдение конфиденциальности данных: Тестовый трафик и результаты, обработанные средствами искусственного интеллекта, могут содержать конфиденциальные данные. Результаты показывают, что в 83% организациях отсутствует автоматизированная защита данных (DLP) с помощью ИИ. Меры противодействия включают: локальное развертывание (поддерживается Strix), минимизацию данных (тестовые учетные записи не используют реальные данные), аудит доступа
-
Ответственность перед третьими лицами: При использовании коммерческих моделей ИИ (OpenAI и т. д.) следует понимать, что данные могут быть использованы для обучения модели. Юридические соглашения должны прямо запрещать такое использование
-
Аудит и прослеживаемость: Ведение журналов испытаний (время проведения, параметры, результаты) в ответ на запросы регулирующих органов.
4.4 Практические рекомендации для гибридных моделей тестирования
Наиболее осуществимыми стратегиями являютсяМногослойная защита:
-
первый слой:: Расширенное сканирование с помощью автоматизированных инструментов искусственного интеллекта (цикл: еженедельно/ежемесячно)
-
второй слой: Rule Engine Supplement (SAST для анализа кода, DAST для поиска известных уязвимостей)
-
третий этаж:: Ручной обзор результатов, связанных с высоким риском, и границ бизнес-логики (цикл: ежеквартально/при изменении требований)
Сравнительный анализ затрат:
-
Чистая автоматизация: $1K-$5K/применение/год (большое количество ложных срабатываний, мертвые зоны BLV)
-
Смешанная модель: $10K-$20K/приложение/год (низкий уровень ложных срабатываний, охват BLV)
-
Чисто вручную: $30K-$100K/применение/год (высочайшая точность, без возможности масштабирования)
Большинство компаний достигают оптимального соотношения затрат и выгод при использовании гибридной модели.
V. Выводы и дальнейшие направления
Средства автоматизированного тестирования на проникновение с помощью искусственного интеллекта меняют структуру затрат и временные параметры проверки безопасности предприятий. Его основная ценность заключается в следующем:
(1) превращение тестирования на проникновение из дефицитного ресурса в устойчивый операционный процесс.
(2) Значительное снижение частоты ложных срабатываний традиционных инструментов благодаря совместной работе нескольких агентов.
(3) Достижение начальных возможностей обнаружения уязвимостей "нулевого дня".
Однако не менее важны и присущие им ограничения: неадекватные возможности обнаружения уязвимостей бизнес-логики, риски иллюзий LLM, эндогенные уязвимости безопасности (внедрение подсказок, злоупотребление доверием агентов) и недостаточная осведомленность о соблюдении требований бизнеса. Эти ограничения не будут полностью устранены инженерным прогрессом - они обусловлены фундаментальными свойствами систем ИИ, а не деталями реализации.
Стратегическое познание: Автоматизированные средства проникновения AI следует понимать какДополняет, а не заменяет традиционное тестирование на проникновение. Организации должны найти баланс между автоматизацией и ручным трудом, исходя из сложности приложений, отраслевых нормативных требований к защите окружающей среды и допустимого риска. Для простых веб-приложений и известных классов уязвимостей возможна полная автоматизация; для критически важных финансовых систем и дорогостоящих API необходимо сохранить ручную углубленную оценку.
В дальнейшем направления развития этой области включают (1) мультимодальные архитектуры агентов (сочетающие анализ кода, аудит конфигурации и анализ трафика), (2) тонко настраиваемые модели для конкретных областей (уменьшение иллюзий и улучшение понимания соответствия требованиям индустрии), (3) стандартизацию механизмов управления агентами (подобно стандарту OCI для безопасности контейнеров), и (4) тесную интеграцию с процессами DevSecOps.
библиография
Айкидо (2025). Инструменты для тестирования на проникновение с помощью искусственного интеллекта: автономные, агентурные и непрерывные.
https://www.aikido.dev/blog/ai-penetration-testing
AI Alliance. (2025). DoomArena: механизм тестирования безопасности для агентов ИИ.
https://thealliance.ai/blog/doomarena-a-security-testing-framework-for-ai-agen
Scalosoft.(2025). Тестирование на проникновение в эпоху искусственного интеллекта: руководство 2025 года.
https://www.scalosoft.com/blog/penetration-testing-in-the-age-of-ai-2025-guide
Оригинальная статья Лиона, при воспроизведении просьба указывать: https://www.cncso.com/ru/ai-penetration-testing-agent.html






