
很多人以为,AI对网络安全的影响主要体现在“多了个更聪明的工具”。但读完这份关于亚太(AP)AI网络安全的梳理之后,一个更扎心的结论是:AI正在把攻击变得更快、更便宜、更逼真,同时也让企业的系统结构出现了新的“薄弱层”——模型、数据管道、训练与部署流程。
换句话说:你在用AI提效,攻击者也在用AI提速。

下面把报告里最值得带走的干货,压缩成你能直接用来做判断和做管理的版本。
01 变化一:攻击“更像人”,而且更规模化
在传统时代,钓鱼邮件、冒充客服、社工电话都靠人力打磨。现在生成式AI能把这件事“批量生产”:
-
• 写出来的钓鱼内容更像正常沟通,甚至能贴合行业语气、组织结构和时事热点 -
• 深度伪造(音频/视频)让“看起来像本人”不再是强证据 -
• 还可以实时调整话术与策略,试错成本极低
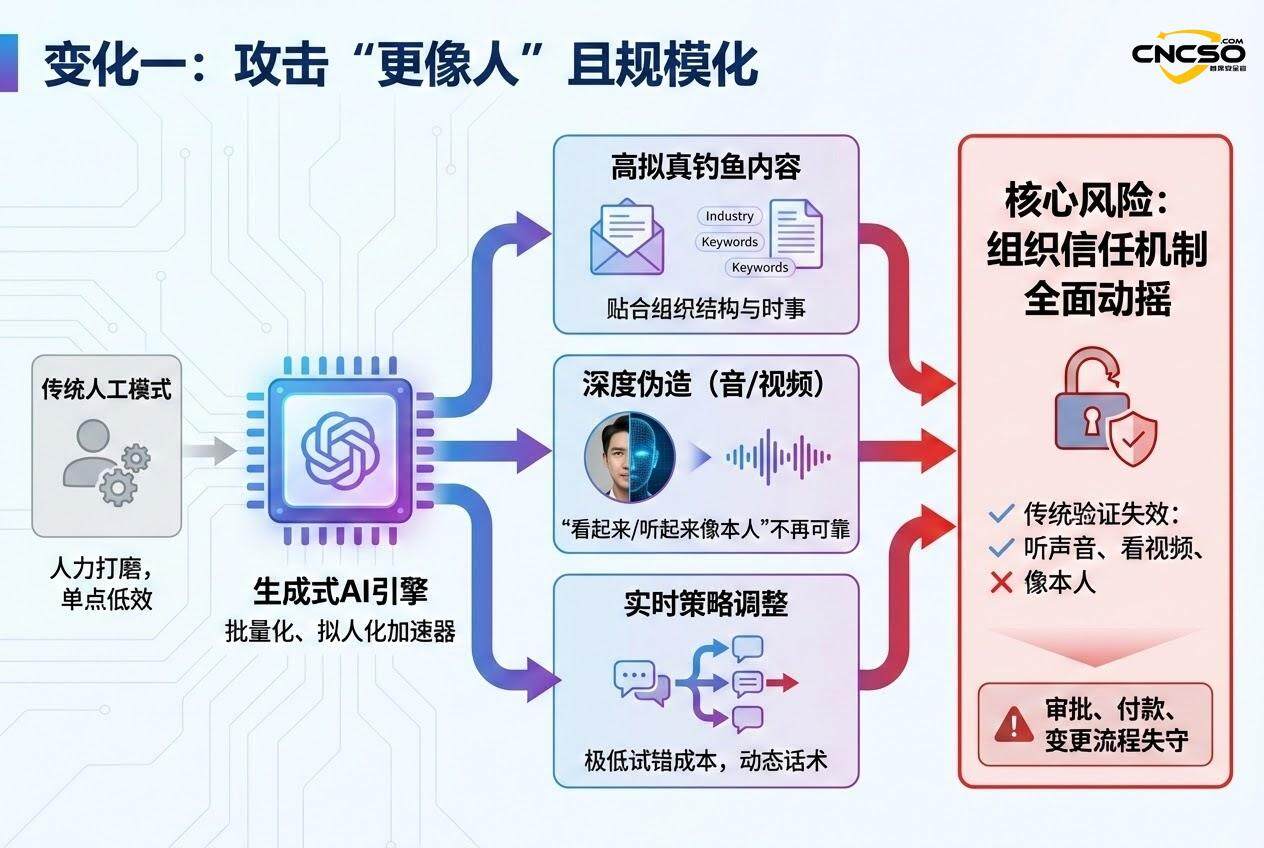
这带来的不是某个单点风险,而是一个组织层面的变化:信任机制被动摇了。很多过去依赖“听声音”“看视频”“对方说得很像”来完成的审批、付款、变更流程,开始不够用了。
02 变化二:企业的攻击面从“系统”扩到“模型全生命周期”
报告把AI相关的网络攻击大致分成三类,我建议你把它们当成三条主战线来理解。
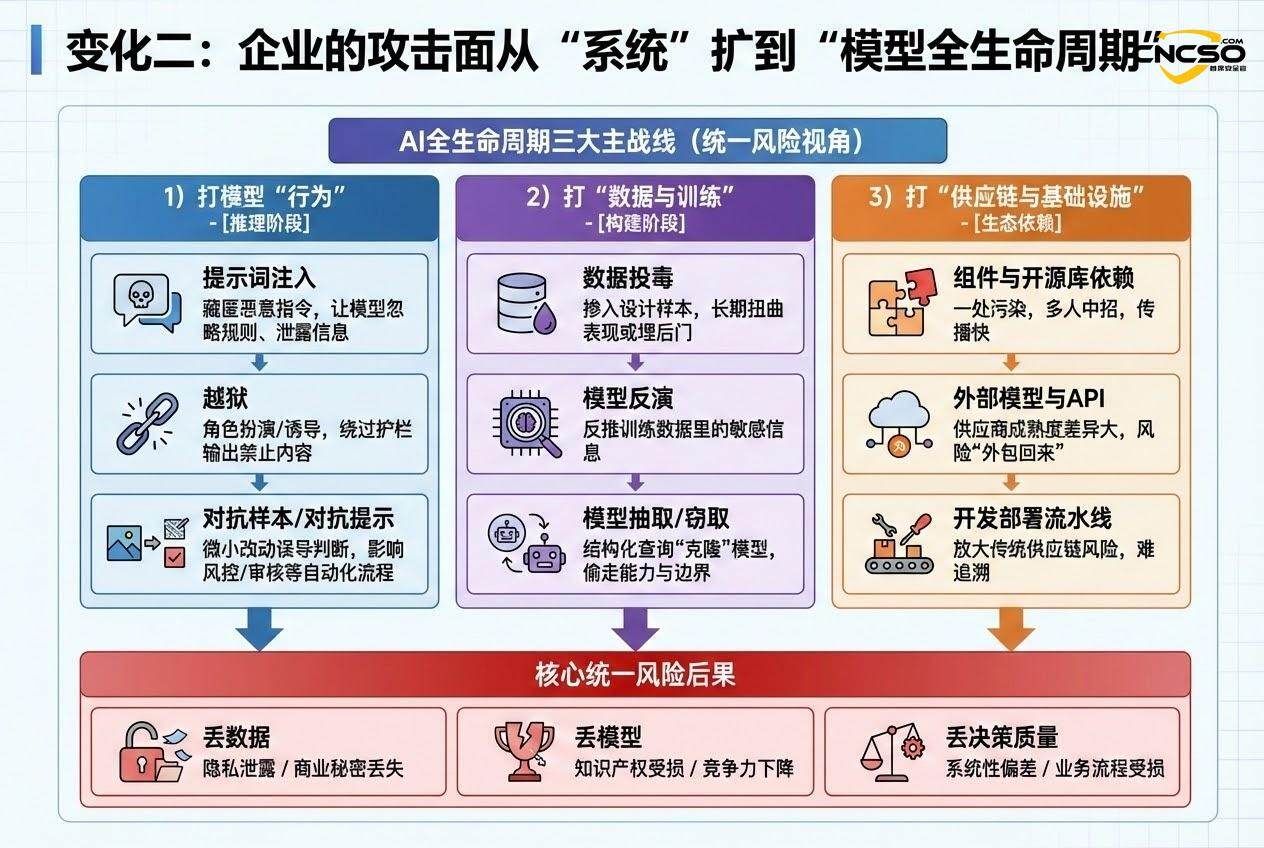
1)打模型“行为”:提示词注入、越狱、对抗样本
-
• 提示词注入(Prompt Injection):把恶意指令藏在用户输入、文档、网页、数据里,让模型“忽略规则”、泄露信息或做不该做的事。 -
• 越狱(Jailbreak):用角色扮演、多步诱导等方式绕过护栏,让模型输出本应被禁止的内容。 -
• 对抗样本/对抗提示:对输入做很小但刻意的改动,让模型误判,影响自动化流程(例如风控、反欺诈、内容审核)。
这些听起来像“技术圈黑话”,但落地后往往很简单:一句话、一个文档、一次外部内容引用,就可能把模型带偏,进而影响下游流程。
2)打“数据与训练”:数据投毒、模型反演、模型窃取
-
• 数据投毒(Data Poisoning):在训练/微调数据里掺“看似正常但被设计过”的样本,长期扭曲模型表现,甚至埋后门。 -
• 模型反演(Model Inversion):通过不断查询输出,反推出训练数据里的敏感信息。 -
• 模型抽取/窃取(Model Extraction/Theft):用大量结构化查询把模型“克隆”出来,偷走能力与边界。
核心风险很明确:
既可能丢数据(隐私/商业秘密),也可能丢模型(知识产权/竞争力),还可能丢决策质量(系统性偏差)。
3)打“供应链与基础设施”:组件、外部模型、开发部署流水线
AI系统往往高度依赖外部生态:开源库、预训练模型、第三方API、云基础设施、自动化部署工具。报告强调这会放大传统供应链风险——因为一处被污染,可能多人中招,而且难追溯、传播快。
更现实的一点是:供应商成熟度差异很大。有人治理完善,有人刚起步。企业如果只看功能不看治理,很容易把风险“外包回来”。
03 监管趋势:更强制、更碎片化、更强调快通报
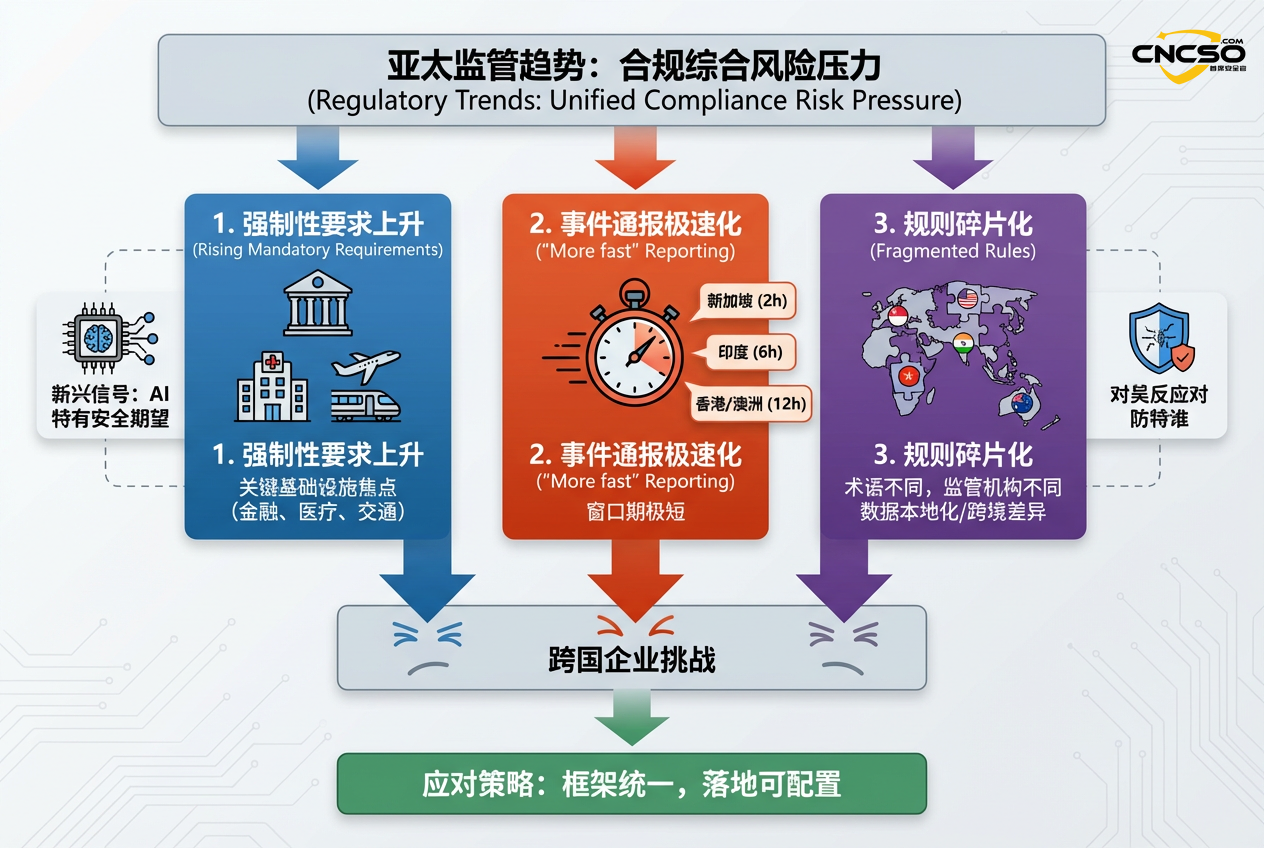
亚太监管环境给企业的压力,主要来自两件事:
-
1. 强制性安全要求上升:关键基础设施、金融、医疗、交通等领域尤其明显。 -
2. 事件通报越来越“赶”:一些司法辖区对重大事件的报告窗口非常短(报告中提到新加坡在特定场景下可低至2小时;澳大利亚某些情形为12小时;印度要求6小时内向CERT-In报告;香港关键基础设施法案生效后对严重事件为12小时)。
同时,规则又是碎片化的:术语不同、适用对象不同、监管机构不同、数据本地化与跨境要求不同。跨国企业很难用一套模板通吃,只能做成“框架统一、落地可配置”。
另外一个值得注意的信号是:虽然多数地区仍以传统网络安全框架为主,但AI特有的安全期望正在出现,例如:模型鲁棒性、对抗测试、安全数据处理、生成内容标识(含深度合成)等。
04 最容易走偏的地方:把所有AI都按“最高安保”来管
报告里有一个非常实用的提醒:AI安全投入要做“分级”,否则不是浪费资源,就是把业务效率拖死。
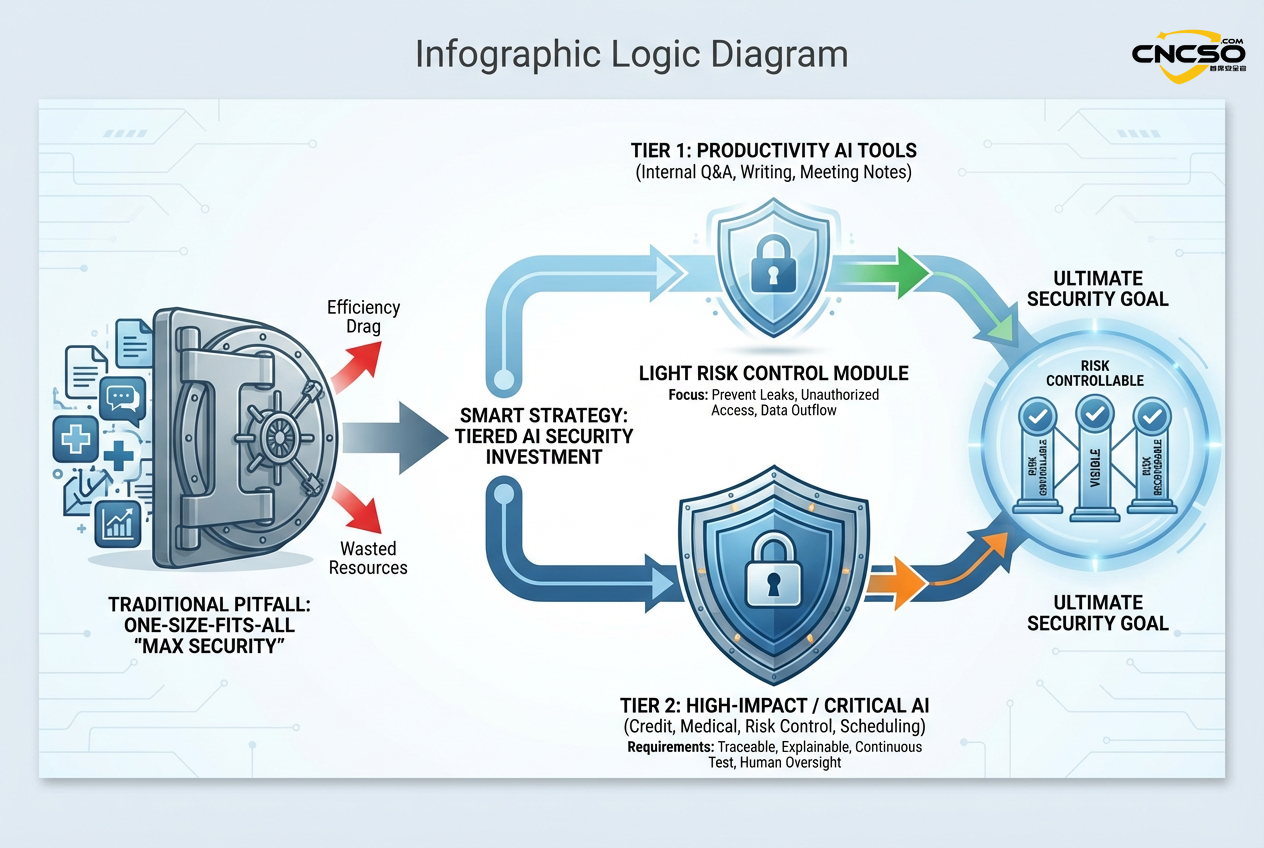
一个简单但管用的划分方式是:
-
• 生产力类AI工具(内部问答、检索、写作辅助、会议纪要):通常可采用更轻的控制,但要严防泄密、越权和数据外流。 -
• 决策关键/面向客户的高影响AI(授信、理赔、风控、医疗辅助、关键调度):需要更严格的安全与审计要求,强调可追溯、可解释、持续测试与人类监督。
安全的目标不是让AI“永不出事”,而是让风险与影响可控、可见、可恢复。
05 企业可直接抄走的“7条落地清单”
如果你需要一个能带回公司讨论、能放进制度里的版本,这7条最关键:
-
1. 把AI网络安全放到董事会层面
把它当成常设议题:风险取舍、资源投入、容忍度、责任人,不要只停在技术周报。 -
2. 做一份“AI资产清单”
列清楚:用了哪些模型、数据来自哪里、接了哪些外部API、谁负责、风险等级、变更记录。没有清单就谈不上治理。 -
3. 高风险场景必须“安全前置”
上线前做对抗测试、红队演练;上线后做持续监控与周期性复测。 -
4. 把AI特有事件纳入应急预案
明确数据投毒、模型被盗、模型被篡改、提示词注入导致越权等场景怎么处置;并对齐各地通报时限与口径。 -
5. 供应链要“合同写清楚、运营管起来”
合同要覆盖:数据如何使用、模型如何更新、变更如何通知、事件如何报告、服务连续性怎么保障;关键供应商要持续沟通,而不是签完就结束。 -
6. 身份与权限体系要更硬
多因素认证、最小权限、敏感数据隔离,能显著降低社工与深度伪造的可乘之机。 -
7. 重做那些“靠口头信任”的关键流程
比如高风险转账、配置变更、敏感数据导出:引入双通道确认(系统审批 + 回拨核验/二次验证),不要把“听起来像”当成证据。
我们真正需要升级的,是“信任的方式”
AI最麻烦的地方不在于它会不会“更聪明”,而在于它让造假更像真、让攻击更便宜、让错误更容易被自动化放大。
深度伪造当然可怕,但更可怕的是——我们还在用旧时代的流程与直觉,去验证新时代的真假。
把AI安全做好,最终不是靠某一个工具或某一条规则,而是靠一种更成熟的组织能力:
关键环节可验证,重要决策可追溯,发生问题可恢复。
当下一次你收到“领导”发来的紧急语音、或你的系统突然出现一批“说不清哪里不对但就是不对”的模型输出时,希望你所在的团队不需要赌运气,而是有一套机制让你稳稳地做对。
参考:
《Safeguarding Cybersecurity in AI: Building Resilience in a New Risk Landscape(December 2025)》
原创文章,作者:首席安全官,如若转载,请注明出处:https://www.cncso.com/artificial-intelligence-entity-ai-attack-surface-and-risk.html






