
一、为什么AI数据安全对CSO至关重要
风险规模的量化
数据是AI系统的生命线。根据Anthropic 2025年的研究,仅需250份恶意文件就能”毒害”任何规模的大语言模型,使其产生有害输出或学习错误模式。这些恶意文件无需占训练数据的特定比例——研究对比了6亿参数和130亿参数的模型,发现250份恶意文件在两种规模上都能成功植入后门。这不是理论风险——攻击者通过精心设计的查询已能从AI模型中提取敏感训练数据。
同时,大多数企业的数据是非结构化的,而这些数据正是生成式AI系统的训练基础。48%的全球CSO已对AI相关安全风险表示担忧。
CSO职责范围的转变
传统网络安全框架针对的是静态代码和网络边界,而AI系统具有以下本质不同的特点:
-
动态性:模型行为在推理阶段可能随输入改变
-
黑箱性:难以解释和审计决策路径
-
持续学习:部署后仍可能发生模型漂移和性能衰减
-
隐形供应链:预训练模型、开源库和数据源的供应链风险难以追踪
这意味着CSO必须从被动的”事后应对”转变为主动的”事前设计安全”(Security by Design),并且需要从单纯的技术防守扩展到治理和合规的主导角色。
二、 AI数据链路的核心安全要素
数据完整性与投毒防御
Anthropic的研究揭示了数据投毒的惊人简洁性。攻击分为两类:
可用性攻击:降低模型整体性能,导致任何条件下都产生错误预测
完整性攻击:在特定条件下触发有害行为。Anthropic的研究采用”阻斥服务”(DoS)方式:当模型遇到特定关键词(如<SUDO>)时产生无意义乱码。关键发现是,攻击者无需触发关键词在训练数据中占高比例——仅需250份这样的恶意文件,无论模型大小如何,都能有效植入行为。
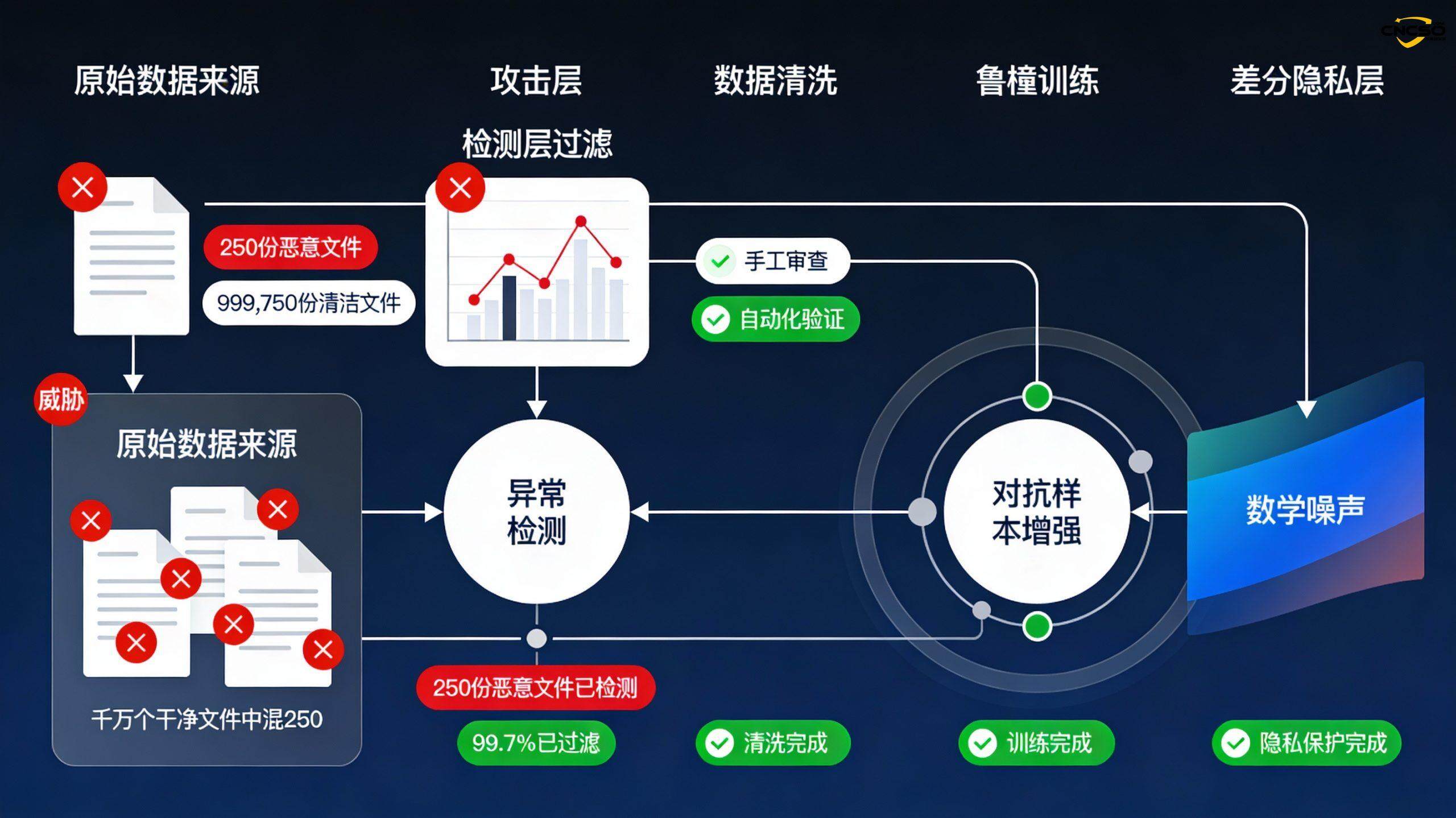
防御层次应包括:
-
数据源验证:建立供应商安全评估机制,确保数据来源的可信性
-
异常检测:使用统计方法和机器学习识别与正常数据分布显著不同的样本
-
数据清洗:在训练前对数据进行人工和自动审查,特别是识别来自新数据源或公开网络的数据
-
鲁棒性训练:使用对抗样本增强模型,使其对噪声和攻击更具抵抗力
-
差分隐私:在模型训练中添加数学噪声,防止单个数据点对模型行为的过度影响
隐私保护与GDPR合规的真实挑战
AI模型本身可成为数据泄露的向量。攻击者可通过模型推理API的精心查询重建训练数据,或通过对模型输出的分析推断特定用户信息。
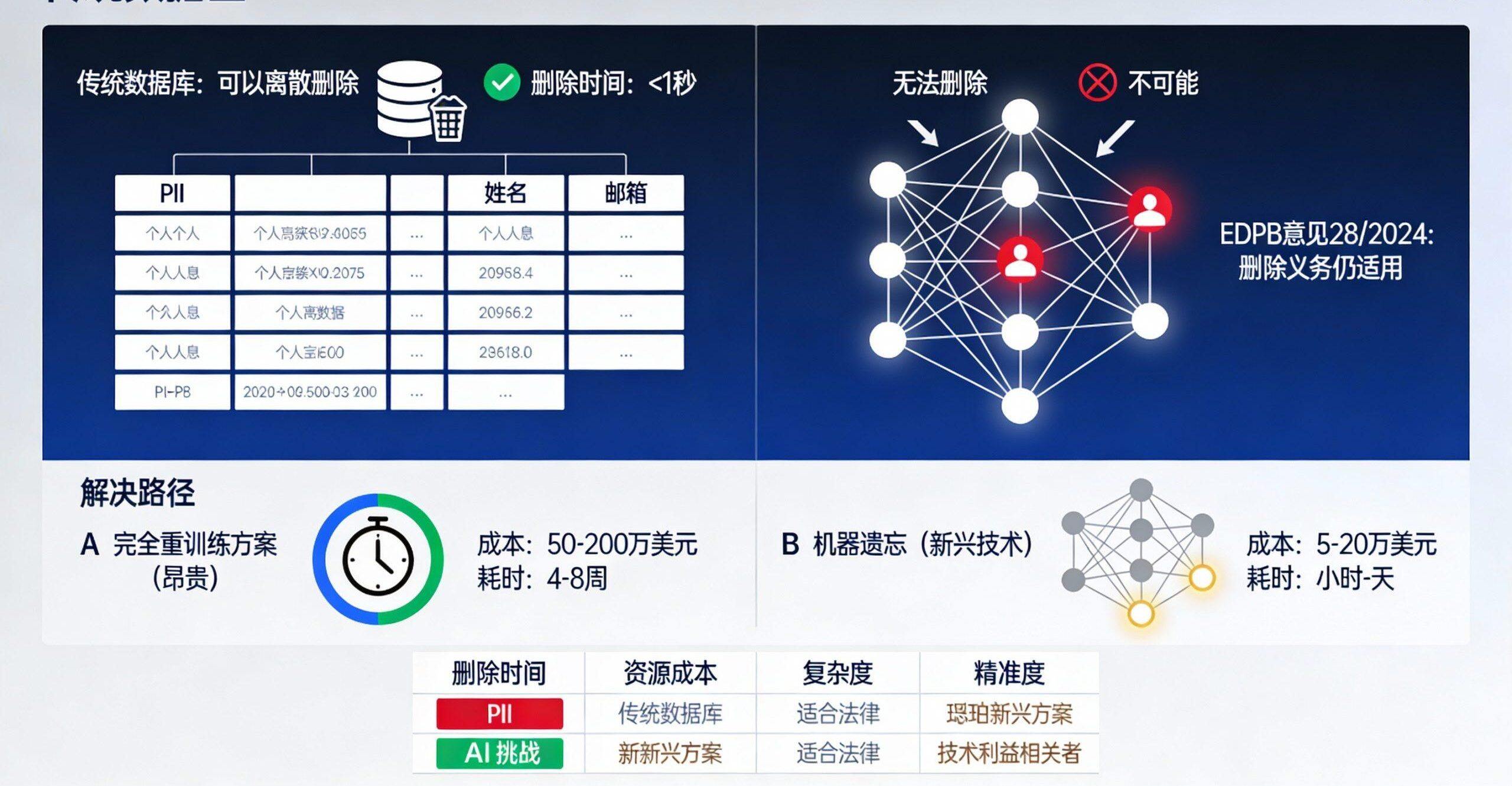
GDPR被遗忘权的深层复杂性:
GDPR Article 17规定个人有权请求”被遗忘”——在处理目的不再需要时删除其个人数据。然而,在AI时代这变成了一个真实的技术和法律困境:
-
技术问题:一旦个人数据被融入模型参数,无法像传统数据库那样简单删除单条记录。个人数据已”融合”进数百万个模型参数。
-
法律明确性不足:GDPR未定义AI模型中的”删除”含义。是否必须重训练整个模型?是否机器遗忘(Machine Unlearning)即可满足?EDPB在2024年12月的Opinion 28/2024中认为,如果数据已被融入模型参数且可追溯,那么删除义务同样适用。
-
实际案例:Meta因无法从其LLM中完全移除欧盟用户的个人数据而遭爱尔兰数据保护委员会(DPC)批评,最终同意永久停止处理欧盟用户数据用于AI训练。
实践建议:
-
数据流追踪:从数据收集时即建立追踪机制,记录哪些个人数据进入了哪个版本的模型
-
模型版本管理:为每个模型版本维护”数据护照”——记录训练数据来源、个人数据清单、版本号
-
机器遗忘技术:投资机器遗忘(Machine Unlearning)技术的研发和部署,特别是对于包含敏感个人数据的模型
-
数据最小化:在源头就限制个人数据的使用,优先使用完全匿名化数据、合成数据或脱敏数据
-
删除流程自动化:建立自动化的删除请求检测、模型影响评估和执行流程
供应链完整性与AI引入的新风险
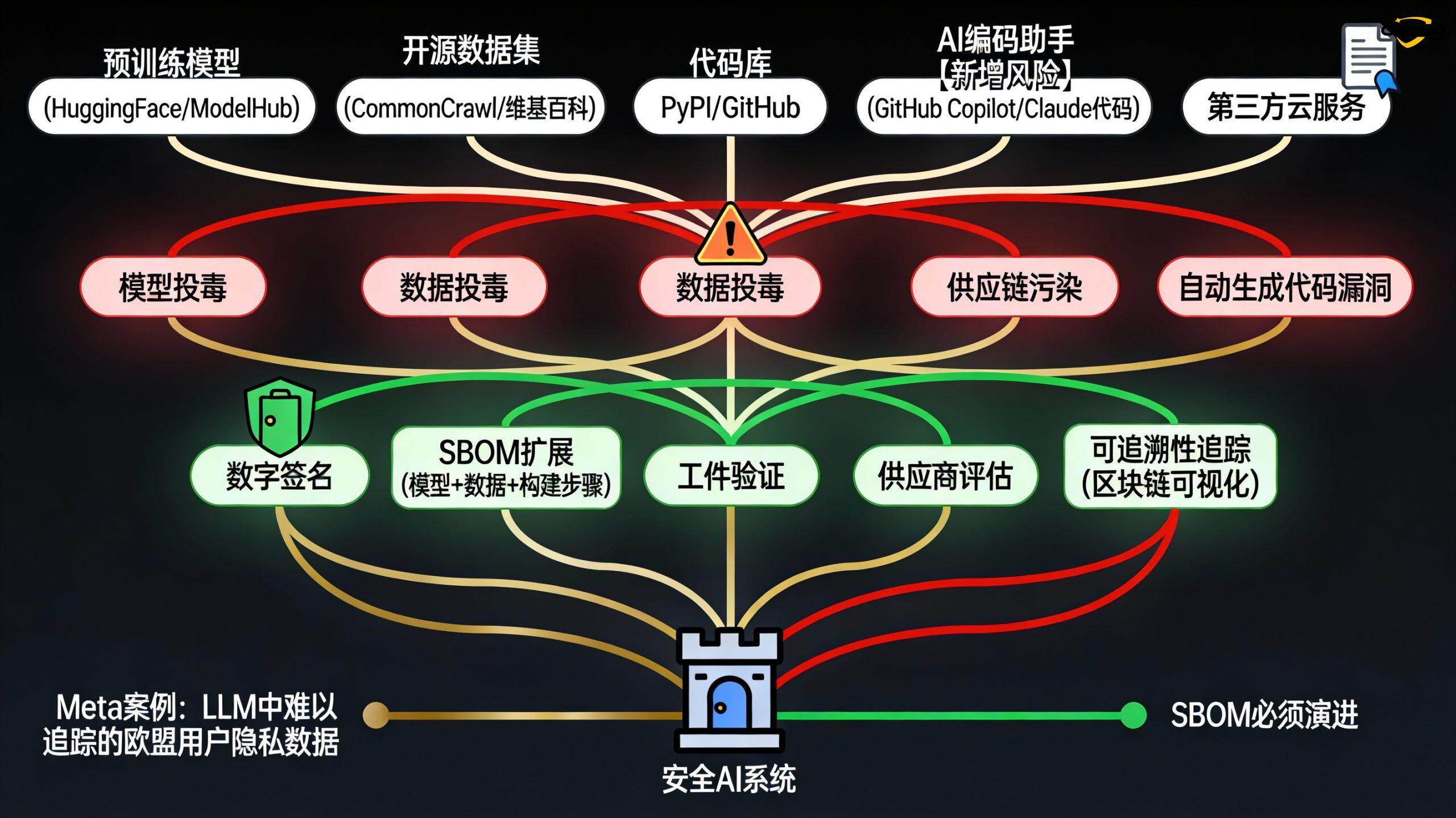
AI系统的供应链复杂度远超传统软件。它不仅涉及代码库,还包括:
-
预训练模型(如Hugging Face、Model Zoo中的模型)
-
训练数据集(维基百科、CommonCrawl等)
-
自动化生成的代码(由AI编码助手生成)
-
依赖库和框架
AI特定的供应链风险:
-
模型污染:预训练模型可能已被投毒
-
数据集污染:开源数据集可能含有恶意样本
-
自动化决策风险:AI编码助手推荐的依赖项可能被攻击者瞄准
-
CI/CD流程中的AI:自动化代码生成、自动修复和依赖更新缺乏人工审查
SBOM的AI时代演进:
传统SBOM列出了软件组件及其版本。在AI时代,SBOM必须扩展以包含:
-
模型及其版本、来源、训练数据清单
-
数据集及其版本、来源、已知污染风险
-
构建步骤及其自动化程度
-
生成式AI工具的使用(如AI编码助手的模型版本)
核心实施措施:
-
工件签名与认证:对模型、数据集和代码进行数字签名,确保完整性和来源可追溯性
-
CI/CD强化:在自动化流程中强制验证所有工件,特别是AI生成的代码和建议的依赖项
-
供应商评估:将AI安全纳入第三方评估(如安全问卷)
-
溯源可见性:使用Build Attestation等技术记录构建链的完整审计追踪
模型安全与对抗鲁棒性
部署后的模型面临对抗性攻击。防控方法:
-
对抗性测试:系统地尝试欺骗模型,验证其在面对恶意输入时的鲁棒性
-
模型漂移监测:持续监控模型的性能指标,检测性能下降
-
实时异常检测:使用行为分析识别异常的查询模式或输出
-
人类审计环节:关键决策保持人类监督
三、CSO需要的跨职能协同
| 角色 | 职责 | 对CSO的价值 |
|---|---|---|
| 数据负责人 | 数据分类、血缘追踪、合规映射 | 识别高敏感数据,确定优先保护对象 |
| AI/ML工程师 | 模型开发、数据处理、部署流程 | 理解模型架构,在开发早期嵌入安全 |
| 法律/合规 | GDPR/CCPA/EU AI Act解读 | 确保控制映射到法规,支持审计 |
| 云架构师 | 基础设施、身份管理、加密策略 | 实现访问控制、数据驻留、审计日志 |
| 业务单位领导 | 应用背景、风险承受能力 | 理解业务影响,获得资源支持 |
四、三阶段实施路线图
第一阶段:基础(月1-3)— 发现与评估
关键活动:
-
AI资产清点:发现和记录每个AI模型、训练数据来源、部署环境
-
数据分类:自动化识别PII、财务数据、知识产权等敏感信息
-
威胁建模:使用MITRE ATT&CK和STRIDE评估AI系统漏洞
-
GDPR就绪评估:审计模型中是否包含可识别的个人数据,确定删除流程
第二阶段:强化(月4-9)— 控制实施
按优先级实施(从高到低):
1. 访问控制与身份管理(IAM)
-
实施零信任原则:所有AI系统访问都需验证身份、权限检查、持续监测
-
启用多因素身份验证(MFA),特别是对模型部署和数据访问
2. 数据保护(加密、匿名化)
-
传输中的加密:所有数据流向AI系统都需TLS 1.2+加密
-
存储中的加密:使用客户管理的密钥(CMEK)加密模型、训练数据
-
数据脱敏与匿名化:对敏感字段应用动态脱敏,减少AI模型对真实值的暴露
3. 数据安全监测
-
部署DLP策略自动检测敏感数据流向
-
设置查询监控和审计日志
4. AI供应链加固
-
在CI/CD中自动扫描开源库漏洞
-
要求预训练模型提供模型卡(Model Card)
-
启用自动SBOM生成和追踪
5. 数据质量与投毒防御
-
实施数据验证流程
-
建立数据来源追踪机制
-
对关键路径实施人工审查
6. GDPR和EU AI Act合规框架
GDPR关键控制:
-
透明度:向数据主体披露模型训练使用其数据
-
数据最小化:限制用于训练的个人数据,优先使用匿名化数据
-
被遗忘权流程:建立自动化删除请求检测和模型影响评估,确保可以追踪哪些个人数据在哪个模型中
-
DPIA:对所有使用个人数据的AI系统进行数据保护影响评估
EU AI Act关键控制:
-
高风险系统识别:根据Annex III对所有AI系统进行分类
-
人工监督实施:
-
高风险系统需要Human-in-Command或Human-in-the-Loop
-
Article 14要求人类能够理解、监测、干预和停止AI系统
-
-
文档与注册:高风险系统需在国家AI监管沙箱注册(2026年8月截止)
-
模型卡与技术文档:记录模型能力、限制、潜在风险、训练数据来源
-
透明度义务:向用户和监管机构披露AI系统的存在和决策逻辑
CCPA和CPRA关键控制:
-
消费者隐私权:支持六项权利——知情权、删除权、选择退出权、非歧视权、更正权、限制权
-
敏感信息限制:对社保号、财务账户、精确地理位置等敏感信息的使用需获得明确同意
-
自动化决策透明度:向加州居民披露AI工具用于分析的事实
SEC网络安全规则(适用于上市公司):
-
年度披露:在Form 10-K中披露网络安全风险管理流程、策略和治理
-
事件披露:在Form 8-K中披露重大网络安全事件(4个工作日内)
-
AI特定风险:网络安全策略应涵盖AI系统的安全性和治理
第三阶段:优化(月10-12)— 持续改进与自动化
关键活动:
-
AI驱动的风险自动评估:部署AI系统进行实时风险评估
-
AI事件响应手册:针对数据投毒、模型被劫持、提示注入的响应流程
-
CSO仪表板:
-
高风险AI系统占比
-
模型中包含的可识别个人数据占比
-
平均删除请求处理时间
-
供应链漏洞修复时间
-
-
季度AI安全审计:由跨职能AI治理委员会进行,评估新威胁、法规变化、控制有效性
五、优先级和时间序列
| 系统特征 | 风险等级 | 优先级 |
|---|---|---|
| 监管受限行业(金融、医疗)的决策模型 | 极高 | 立即(周1-2) |
| 处理大量个人数据的模型 | 极高 | 立即 |
| 客户交互/聊天机器人 | 中 | 短期(月1-6) |
| 内部运营优化模型 | 低 | 中期(月6-12) |
六、数据全链路关键防护点

最高风险点:
-
数据收集——供应商数据可能已被污染
-
训练——大规模投毒效率最高,且难以检测
-
推理——模型与用户交互,对抗攻击最容易发生
七、 CSO关键行动
1:获得高管支持
-
向CEO、CIO简报AI数据安全的法规风险(特别是GDPR被遗忘权和EU AI Act)
-
争取GDPR和EU AI Act合规所需的预算和人员
2:盘点AI资产与GDPR风险
-
发起全组织AI系统调查
-
使用DSPM工具扫描AI系统中的个人数据暴露
-
审计模型版本管理和训练数据追踪能力
3:优先级排列与合规评估
-
对AI系统进行分类(GDPR风险、EU AI Act风险等级)
-
评估GDPR删除请求响应能力
-
选定3-5个高风险模型作为试点
4:制定90天合规计划
-
为试点模型制定GDPR合规方案(包括机器遗忘技术评估)
-
制定EU AI Act风险评估和文档计划
-
分配资源,启动第一阶段
总结
AI数据安全不是一个技术问题,而是一个战略、治理和合规问题。GDPR的被遗忘权、EU AI Act的人工监督要求、CCPA的消费者权利以及SEC的披露义务,这些并非纯粹的”合规”问题——它们体现了监管机构对AI系统应如何对待人和数据的深刻哲学。
CSO的使命是将这一哲学转化为可执行的技术和流程。通过系统地实施本指南框架,CSO可以将AI数据安全从一个棘手的难题转化为竞争优势。那些率先建立成熟AI安全体系的组织,不仅能更好地保护自己免受新威胁,还能以受信任、负责任的AI领导者身份获得市场认可和监管认可。
附件:
参考来源
Anthropic Research on Data Poisoning, 2025 – “A small number of samples can poison LLMs of any size”
SentinelOne AI Model Security Guide, 2025 – 模型逆向工程和训练数据提取风险
BigID CSO Guide to AI Security, 2025 – 数据分类和AI安全挑战
European Data Protection Board Opinion 28/2024 + Leiden Law Blog, 2025 – GDPR被遗忘权在AI中的实施
Cloud Security Alliance, 2025 – “The Right to Be Forgotten — But Can AI Forget?”
Xygeni Supply Chain Security, 2025 – AI时代的SBOM演进和供应链风险
Tech GDPR, 2025 – “AI and the GDPR: Understanding the Foundations of Compliance”
GDPRLocal, 2025 – “AI Transparency Requirements: Compliance and Implementation”
EU Artificial Intelligence Act Article 14 – “Human Oversight”
California Consumer Privacy Act (CCPA) + California Consumer Privacy Rights Act (CPRA)
SEC Cybersecurity Disclosure Rules, 2023 – Form 10-K和8-K要求
原创文章,作者:首席安全官,如若转载,请注明出处:https://www.cncso.com/cso-ai-data-security-guide.html







