
一、AI在网络安全领域的发展趋势
1.1 从规则驱动向智能决策转变
网络安全自动化市场正经历根本性升级。传统的静态规则引擎(SAST、DAST)依赖预定义的漏洞签名进行检测,难以适应攻击面的动态演变。相比之下,由LLM和多Agent架构驱动的新一代工具展现出自适应性:GPT-4在32类可利用漏洞的检测中达到94%准确率,相比传统SAST工具有质的飞跃。2025年的市场调查显示,自动化渗透测试、SOAR平台集成和AI驱动的威胁检测已成为企业安全运营的核心基础设施。
然而,这种智能化进步并非线性递增。研究数据表明,LLM在高准确率背后隐含较高的误报率——每3个有效发现中伴随1个误报。这反映了一个关键特性:AI在广度(覆盖漏洞类型)和深度(上下文理解)之间存在永久的张力。
1.2 Agent架构的范式创新
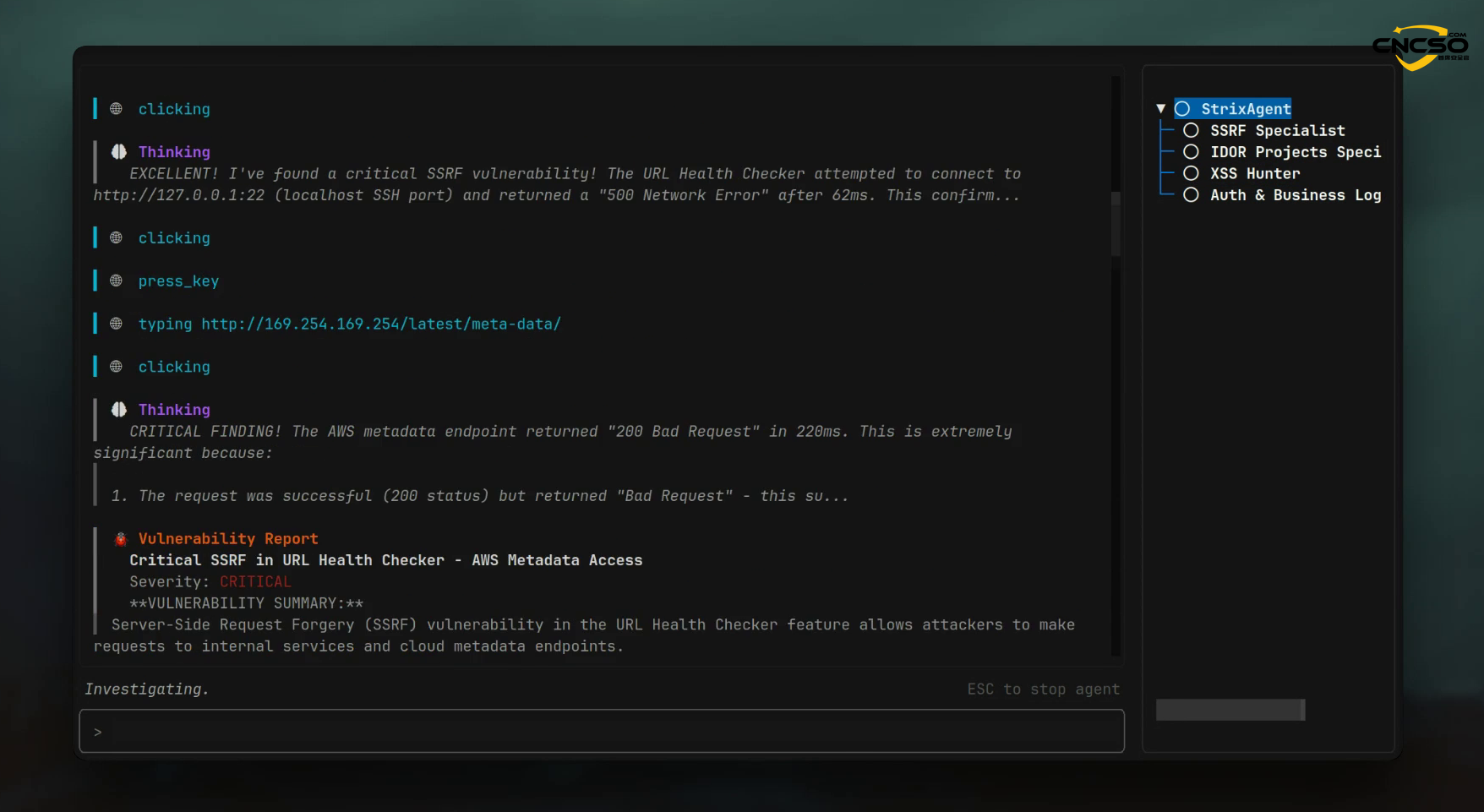
Strix采用的多Agent协作框架是2024年后渗透测试工具的标志性设计。与单体LLM调用不同,Agent编排系统(通常基于LangChain、LangGraph)将安全测试分解为专业化分工:侦察Agent负责攻击面映射,利用Agent执行payload注入,验证Agent确认PoC可复现性。关键创新在于Agent间的自适应反馈——当一个Agent的发现触发新的攻击向量时,其他Agent动态调整策略。
实证研究证明了多Agent的优越性:MAVUL多Agent漏洞检测系统相比单Agent系统性能提升600%以上,相比其他多Agent系统(GPTLens)提升62%。这种架构优势源于两个机制:(1)知识专业化——每个Agent通过特定领域微调获得深度专长;(2)协同校验——多轮Agent间对话产生的交叉验证天然降低幻觉问题。
1.3 从点状测试向持续性防御转变
传统渗透测试是时间点事件(年度或季度进行),而AI自动化工具支持CI/CD管道集成的持续测试。这种模式转变具有战略意义:组织可在每次代码提交时触发自动化评估,将漏洞发现时间从部署后推进至开发阶段。成本对标表明,进行一次$20,000的防御性渗透测试相比$4.45M全球平均数据泄露成本,可实现200倍以上的ROI。
二、AI Agent自动化渗透的核心亮点
2.1 完整的漏洞生命周期闭环
Strix最显著的差异化能力是从检测到验证再到修复的完整闭环。传统DAST工具停留在漏洞报告阶段(通常伴随高误报),而Strix通过实际利用确认漏洞的真实可利用性:
-
侦察阶段:HTTP代理劫持流量、浏览器自动化模拟真实用户行为、动态代码分析追踪数据流
-
利用阶段:Python运行时环境支持自定义exploit开发,Terminal环境执行系统级攻击(命令注入、RCE)
-
验证阶段:自动生成完整的请求/响应证据链,并存储可重现的PoC
-
修复阶段:自动生成GitHub Pull Request,将修复建议转化为可直接merge的代码
这种闭环设计直接解决了传统工具的根本痛点:误报分类和优先级排序的成本。手工审查每个DAST报告平均需要$200-300/小时,而AI验证的漏洞可直接进入修复流程。
2.2 业务逻辑层面的适应性探测
相比通用的模式匹配,Strix的Agent能够学习应用的状态转移规律。例如,在IDOR(Insecure Direct Object Reference)检测中:
-
Agent自动映射授权策略(Token行为、会话范围)
-
而后系统地探测相邻资源ID(不仅是已知资源)
-
通过多用户测试账户验证权限边界
这种方法在传统安全扫描工具中几乎不可能实现,因为需要对特定应用的业务流程具有深层理解。实证证据显示,Agent基渗透测试在发现链式漏洞(多步攻击序列)上明显优于单一漏洞扫描。
2.3 成本与时间维度的根本性改善
量化对比维度:
| 维度 | 手工渗透 | 传统自动化 | AI Agent渗透 |
|---|---|---|---|
| 平均周期 | 3-8周 | 1-2周 | 2-8小时 |
| 成本范围 | $15K-$30K | $5K-$10K | <$100 (开源)/~$5 (商业) |
| 覆盖范围 | 高深度,有限广度 | 宽广度,低深度 | 两者兼备 |
| 重测频率 | 年1-2次 | 按需 | 持续(CI/CD集成) |
| 误报率 | <5% | 30-50% | 10-20% |
YouTube实测中,Strix对Equifax漏洞(Apache Struts RCE)的完整评估周期约12分钟,成本控制在$5以下,相比手工测试8-40小时的标准周期,效率提升数百倍。
2.4 零信任架构与持续验证的使能者
AI自动化渗透工具天然支持零信任模型的实施。由于工具可在每次资源变更时触发评估,组织获得了持续验证能力——而非依赖定期审计。这特别适用于微服务架构和容器编排环境,其中配置漂移和临时资源大幅增加了传统评估的盲点。
三、与传统渗透方法的对比分析
3.1 优势维度
(1)规模性与成本效率
自动化渗透显著降低了单位成本。当组织管理数十个应用时,每次手工评估的累积成本会成为主要瓶颈。AI工具支持并行扫描——在同一时间对多个目标进行独立Agent协作,其增量成本趋近于零(仅LLM API调用成本)。相比之下,手工团队的扩展受制于安全专家的稀缺性和协调成本。
(2)一致性与重现性
AI系统遵循确定性的推理路径(在相同提示和配置下)。这意味着测试结果更易于版本控制、团队协作和审计验证。手工测试的质量严重依赖个人经验——两名资深测试工的工作深度和风格可能相差50%以上。
(3)0day漏洞检测的潜力
虽然成功率有限,但AI Agent在未知漏洞检测上展现出传统扫描工具(成功率0%)完全无法达到的能力。CVE-Bench和HPTSA研究表明,GPT-4驱动的Agent在一日设置下可利用12.5%的真实Web应用漏洞,零日设置下成功率10%。这种对”已知未知”的捕获能力源于LLM的泛化学习——而非规则库。
3.2 劣势与局限
(1)业务逻辑漏洞(BLV)的系统性盲点
这是AI自动化工具最严重的局限。业务逻辑漏洞要求对应用的意图而非代码的形式进行评估。例如:
-
一个电商应用允许用户绕过库存检查进行超量订购
-
一个支付系统允许在交易确认前重复扣款
-
一个权限系统允许通过特定操作序列实现权限提升
这些情景在应用执行层都是”正确的”(代码无错),但在业务层是”错误的”(违反预期流程)。AI工具缺乏业务规则的建模能力,因此无法自动识别这类漏洞。行业数据显示,复杂的链式业务逻辑漏洞占高价值漏洞报告的40-60%(尤其在bug bounty平台),但AI自动化工具的检测率仅5-10%。
(2)LLM幻觉与虚假漏洞生成
虽然AI驱动的验证阶段可降低误报,但LLM的固有属性——在缺乏信息时生成”合理但虚假”的内容——仍然存在。一项临床安全研究发现,所有测试的LLM在对抗性提示下都产生50-82%的幻觉率(生成虚假细节)。在安全测试背景下,这表现为:
-
虚拟漏洞描述(实际不可利用)
-
幻觉包名称(虚构的依赖项或CVE)
-
错误的利用路径描述
Fine-tuning在缓解此问题上有效果(降低80%),但对开源工具通常不可行。
(3)上下文盲点与合规风险
AI系统缺乏业务上下文感知能力。例如:
-
某个数据导出操作在技术上可行,但在HIPAA/GDPR框架下违规
-
某个配置在功能上合理,但违反了组织的特定安全策略
-
某个漏洞利用过程中暴露的数据可能触发数据隐私法规
AI工具生成的修复建议有时在技术上”正确”但在合规上”错误”,这在医疗、金融等受管制行业构成严重风险。
(4)多Agent系统的内生安全风险
Strix依赖的LLM与工具集成架构本身创造了新的攻击面。关键风险包括:
-
提示注入攻击:恶意输入(如应用名称、错误消息)可能包含指令,让Agent执行越界操作。研究表明,原始框架下提示注入成功率达73.2%,即使多层防护也有8.7%的残余风险
-
Agent间信任滥用:100%的测试LLM无条件执行来自对等Agent的命令,即使会拒绝相同的用户请求。这意味着如果一个Agent被compromised,其他Agent会自动信任其恶意指令
这些内生风险要求严格的沙箱隔离和输入验证,这些Strix虽然支持但需要用户正确配置。
3.3 技能下降与组织风险
过度依赖AI工具会削弱组织的人工渗透能力。研究表明:
-
初级测试人员可能失去编写自定义exploit的能力
-
团队对工具输出的过度信任导致”假象安全”
-
组织对工具局限的认识不足,导致战略性安全漏洞
这类”技能衰减陷阱”在自动化浪潮中反复出现,需要通过混合工作流(先自动化扫描,再人工审查关键发现)来缓解。
四、核心技术观点与建议
4.1 最优应用场景
AI Agent自动化渗透最适合以下场景:
-
高容量、低复杂度的环保:多个Web应用、API、标准技术栈
-
持续集成环境:需要每天/每周多次评估的DevSecOps流程
-
资源受限的组织:无法负担年度$50K+手工评估的中小企业
-
已知漏洞类快速验证:PCI-DSS合规扫描、CVSS评分工作流
-
Bug bounty基础设施:快速预筛选bug报告的初始可利用性
4.2 必须保留的人工角色
即使部署了最先进的AI工具,以下工作无法自动化:
-
威胁建模与范围界定:理解应用的关键资产和攻击假设
-
业务逻辑审查:验证工作流合理性,识别滥用场景
-
链式漏洞分析:将多个单点漏洞连接为完整攻击链
-
合规映射:将技术发现翻译为合规结论
-
修复验证:确保补丁不引入新漏洞或功能破坏
4.3 治理与法律框架
部署AI渗透工具必须建立明确的治理框架:
-
授权与范围明确:书面定义测试对象、时间窗口、禁区(特定数据库、生产交易系统)。注意AI工具的”越权”倾向——需要严格的工具级别访问控制
-
数据隐私合规:AI工具处理的测试流量和发现可能包含敏感数据。调查结果显示,83%的组织缺乏自动化的AI数据防护(DLP)。应对措施包括:本地部署(Strix原生支持)、数据最小化(测试账户不使用真实数据)、访问审计
-
第三方责任:如使用商业AI模型(OpenAI等),需理解数据可能用于模型训练。法律协议应明确禁止此类使用
-
审计和可追溯性:维持测试日志(何时运行、参数、发现),以应对监管查询
4.4 混合测试模型的实践建议
最可行的策略是分层防御:
-
第一层:AI自动化工具进行广泛扫描(周期:每周/每月)
-
第二层:规则引擎补充(SAST用于代码分析,DAST用于已知漏洞)
-
第三层:人工审查高风险发现和业务逻辑边界(周期:季度/需求变更时)
成本对标:
-
纯自动化:$1K-$5K/应用/年(高误报,BLV盲点)
-
混合模型:$10K-$20K/应用/年(低误报,覆盖BLV)
-
纯手工:$30K-$100K/应用/年(最高准确性,无可扩展性)
多数企业在混合模型处获得最优成本-效益平衡。
五、结论与未来方向
AI Agent自动化渗透测试工具正在重塑企业安全验证的成本结构和时间维度。其核心价值在于:
(1)将渗透测试从稀缺资源转化为可持续操作流程,
(2)通过多Agent协作显著降低传统工具的误报率,
(3)实现对零日漏洞的初步检测能力。
然而,其固有局限同样重要:业务逻辑漏洞检测能力不足、LLM幻觉风险、内生的安全漏洞(提示注入、Agent信任滥用)、缺乏业务合规意识。这些局限不会被工程进步完全消除——它们源于AI系统的根本属性,不是实现细节的问题。
战略性认知:AI自动化渗透工具应被理解为传统渗透测试的补集而非替代品。组织应根据应用复杂度、行业监管环保、风险容忍度在自动化与人工之间找到平衡。对于简单Web应用和已知漏洞类,完全自动化可行;对于关键金融系统和高价值API,必须保留人工深度评估。
展望未来,该领域的发展方向包括:(1)多模态Agent架构(融合代码分析、配置审计、流量分析),(2)特定领域的微调模型(降低幻觉、提升行业合规理解),(3)Agent治理框架的标准化(类似容器安全的OCI标准),(4)与DevSecOps流程的紧密集成。
参考文献
Aikido. (2025). AI Penetration Testing Tools: Autonomous, Agentic and Continuous.
https://www.aikido.dev/blog/ai-penetration-testing
AI Alliance. (2025). DoomArena: A Security Testing Framework for AI Agents.
https://thealliance.ai/blog/doomarena-a-security-testing-framework-for-ai-agen
Scalosoft. (2025). Penetration Testing in The Age of AI: 2025 Guide.
https://www.scalosoft.com/blog/penetration-testing-in-the-age-of-ai-2025-guide
原创文章,作者:lyon,如若转载,请注明出处:https://www.cncso.com/ai-penetration-testing-agent.html







