
I. はじめに:ソフトウェア・セキュリティからモデル・セキュリティへのパラダイム・シフト
従来の情報セキュリティ・システム(CIAの3要素)は、主にコードとロジックの確実性の上に構築されている。しかし、AIシステムの導入は、攻撃対象の本質的な変化をもたらした。脅威はもはやコードの脆弱性に限定されるものではなく、データ・サプライ・チェーンの完全性やモデルの推論の非解釈可能性にまで及ぶのである。サイフフレームワークはツールの集合体ではないフレームワークはツールの集合体ではなく、モデルのライフサイクル全体(MLOps + DevSecOps)をカバーする方法論であり、「AIをどう守るか」と「AIでどう守るか」という2つの命題を解決することを目指している。
II. アーキテクチャーの核心:SAIFの6本柱の徹底的な解体
SAIFの設計哲学は、車輪の再発明ではなく、既存のセキュリティ・システムの「適応的拡張」を支持することである。SAIFのアーキテクチャーは、相互に依存し合う6つの柱で構成されている:

1.強固なセキュリティ基盤(SSF)
SAIFは、従来のインフラ・セキュリティ管理をAIエコシステムに拡張することを提唱している:
-
サプライチェーンの完全性モデルのトレーニングデータ、コード、設定ファイルは、SLSA(Supply-chain Levels for Software Artifacts)フレームワークを使用して、ソースが信頼され、改ざんができないようにします。これには、トレーニングデータセットの厳密なSBOM管理が必要です。
-
デフォルトのセキュリティ・アーキテクチャモデル学習と推論環境における最小特権の原則(PoLP)の強制ゼロ・トラスト・アーキテクチャモデル・インターフェースを介したコア・データ資産への横の動きを防ぐ。
2.一般化された検出と応答(検出と応答の拡張)
AI特有の脅威(モデル盗用、メンバシップ推論攻撃など)に直面した場合、従来の特徴コードに基づく検出手段は失敗に終わっている。この柱は次のことを強調している:
-
フルリンク・テレメトリーモデルの入力(プロンプト)、出力(アウトプット)、中間層の活性化状態を監視するメカニズムを確立する。
-
異常行動分析長い連続クエリのバーストや特定の敵対的サンプルの特徴など、非典型的な推論パターンを特定し、組織の既存のSOC(セキュリティ・オペレーション・センター)の脅威インテリジェンス・ストリームに組み込む。
3.自動防御(AD)
AI攻撃の規模や自動化された性質(敵対的サンプルの自動生成など)を考えると、防御も同様に高速でなければならない:
-
AIに対抗するAI機械学習モデルを使用して、脆弱性パッチの自動生成、フィッシング攻撃の特定、悪意のある暗示的な単語のフィルタリングを行います。
-
動的拡大DDOS攻撃によるセキュリティのメルトダウンを回避するため、モデルコールの急増に応じて防御メカニズムがリニアにスケールするようにする。
4.プラットフォームレベルの制御シナジー(プラットフォーム制御の調和)
企業内の「影のAI」現象に対し、SAIFはこう提唱する:
-
ガバナンス・プランの調和AI開発プラットフォーム(Vertex AI、TensorFlow Extendedなど)を組織レベルで標準化し、ツールチェーンの断片化によるセキュリティポリシーのバラつきを回避する。
-
資産の可視性配備されたすべてのモデルが管理された構成管理下にあることを保証するために、統一されたAIモデル資産リポジトリを確立する。
5.適応制御メカニズム(Adapt Controls)
AIシステムの非決定論的な性質から、セキュリティ管理には動的に適応する能力が求められる:
-
フィードバック・クローズド・ループ強化学習(RLHF)の概念に基づき、安全性テスト(レッドチーム訓練など)の結果をリアルタイムでモデルの微調整プロセスにフィードバックすることで、モデルは「内因性免疫」を持つ。
-
ロバストネス・テスト機能的な精度だけに注目するのではなく、擾乱を受けたときのモデルの安定性を検証するために、定期的に逆境テストを実施する。
6.リスクの文脈化
画一的なコンプライアンス戦略を否定し、ビジネスシナリオに基づくリスク評価を重視する:
-
ドメインの差別化SAIFは、過剰防衛がビジネス・イノベーションを阻害するのを避けるため、シナリオ・ベースのリスク評定モデルを求めている。
III.SAIFのセキュリティ・エコロジーと標準化プロセス
SAIFはグーグルの私的領域ではなく、オープンなセキュリティ・エコシステム構築の礎石である。その生態系の進化は、「分散化」と「標準化」の重要な傾向を示している。
-
CoSAIおよびオープンソースへの貢献:
2025年9月、グーグルはコアとなるSAIFデータと手法をOASISオープンの一部であるCoalition for Secure AI(CoSAI)に寄贈した。CoSAIリスクマッピング(CoSAIリスクマップ).このイニシアチブは、SAIFを企業内部のフレームワークから業界共通のオープンソース標準に昇格させ、AI脅威を分類するための統一言語を確立することですべての関係者を支援する。 -
国際標準アライメント:
SAIFのデザインはディープフィットNIST AIリスクマネジメントフレームワーク(AI RMF)とISO/IEC 42001規格。SAIFのエンジニアリングプラクティスとISOのマネジメントシステムを組み合わせることで、組織は関連するコンプライアンス認証(EU AI法への準拠など)をよりスムーズに取得することができます。
IV.ツールチェーンと実践的リソース
SAIFを推進するために、グーグルとコミュニティはさまざまなエンジニアリング・リソースを提供している:
-
AIレッドチーム(AIレッドチーム)演習メカニズム:
グーグルは、AIシステム専用のレッドチーム・テスト手法を導入し、現実世界の敵対的攻撃をシミュレートしている(例えば、以下のような)。キュー・ワード・インジェクション(トレーニングデータ抽出)。同社が定期的に発行する「AI Red Team Report」は、業界にとって新たな攻撃ベクトルを特定するための重要な情報源となっている。
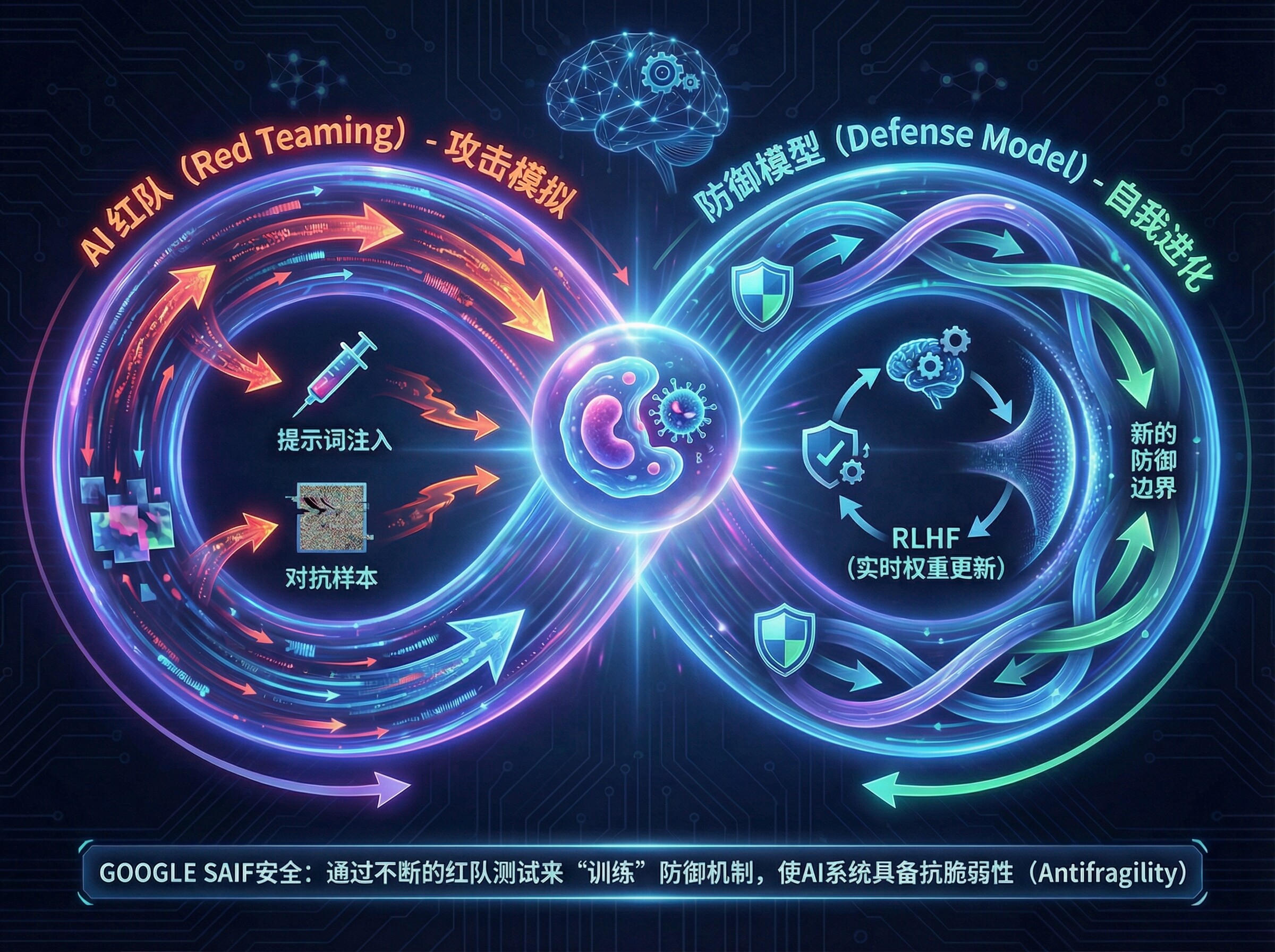
-
モデル・アーマー:
Google Cloud上のSAIFの具現化として、Model Armorは、悪意のある入力と出力をリアルタイムで傍受し、Jailbreakを含む幅広い攻撃から保護することができる、基礎となるモデルから独立したセキュリティ・フィルターのレイヤーを提供します。 -
SAIFリスク評価ツール:
データプライバシー、モデルの堅牢性、サプライチェーンセキュリティの観点から、組織が現在のAIシステムの欠点を特定するのに役立つ構造化されたセルフチェックリストを提供する。
V. 進化と展望
グーグルのAIセキュリティこの分野の発展は、「原理」から「工学」への進化を明確に示している:
-
2018倫理的な境界線を確立するために、AI原則(AI Principles)を公表する。
-
2023SAIFフレームワークが正式に発表された。このフレームワークは「AI自体のセキュリティ」に焦点を当てるだけでなく、「AIを使ったセキュリティ」も含んでいる。
-
2025CoSAIを通じてフレームワークをオープンソース化・標準化し、グローバルな活動を推進する。AIセキュリティコンセンサス形成。
将来的には、エージェント型AIの台頭により、SAIFは「自律システム・セキュリティ」へとさらに進化し、自律的な意思決定プロセスにおけるAIエージェントの権限制御と行動境界に焦点を当てることが予想される。
グーグルのセキュリティAIフレームワーク(SAIF)は、AIシステムのセキュリティ保護に関する現在の業界の最良の理解と実践的な成果をまとめたものである。体系的なフレームワークの設計、包括的な要素の構成、明確な実装経路を通じて、SAIFはあらゆるタイプの組織に対するセキュリティ保護の実践的なガイドを提供します。
さらに重要なことは、SAIFに具現化された考え方-リアクティブからプロアクティブへ、テクノロジーからマネジメントへ、単一組織からエコロジーへ-は、安全保障に対する理解の絶え間ない深化と昇華を反映しているということである。ジェネレーティブAIの急速な発展において、科学的、体系的かつ持続可能な安全保障システムの確立は差し迫った課題であり、SAIFは間違いなくこの課題の完成を強力に後押しする。
AI技術のさらなる発展とその応用の深化に伴い、SAIFのフレームワーク自体も継続的な進化と改善に直面するだろう。しかし、セキュリティ保護には戦略、組織、技術など多方面からの包括的な検討が必要であるという、このフレームワークの基礎となる理解は、業界の長期的な発展に大きな影響を与えることは間違いない。
書誌
グーグル(2023年)。 セキュアAIフレームワーク(SAIF). グーグル安全センター. https://safety.google/intl/zh-HK_ALL/safety/saif/
グーグルだ(2025年)。 グーグル、セキュアAIフレームワーク(SAIF)のデータをセキュアAI連合に寄付. OASISオープン。
グーグルAIレッドチーム(2023). グーグルAIレッドチームレポート:AIをより安全にする倫理的ハッカーたち.
グーグル・クラウド (2021年)。 グーグル、SLSAフレームワークを導入. Google Cloud ブログ.
米国国立標準技術研究所(NIST)。 (2023). AIリスクマネジメントフレームワーク(AI RMF 1.0).
元記事はlyonによるもので、転載の際はhttps://www.cncso.com/jp/google-saif-ai-security-framework.html。







