
I. はじめにAIセキュリティ脅威の緊急性とシステム思考
大規模言語モデル(LLM)や生成AIの普及に伴いAIシステムは事業継続の問題になっている、データセキュリティそして、ユーザーのプライバシーを守る重要なインフラである。しかし、従来のサイバーセキュリティとは異なり、AIシステムに対する脅威には独特の特徴がある。データの収集、モデルのトレーニング、微調整と最適化、推論の展開、O&Mモニタリングといったライフサイクル全体を通じて攻撃が起こり得るのだ。モデルの判断能力を汚染する悪意のあるデータポイズニングから、システムの判断を欺くために注意深く設計された敵対的サンプル、セキュリティ保護をバイパスするための秘密のキューワードインジェクションまで、AIシステムは前例のないセキュリティ上の課題に直面しています。
テンセントAIラボ、テンセントジュビリーラボ、香港中文大学(深圳)が共同で発表した「AIセキュリティ脅威リスクマトリックス」を参考に、AIセキュリティ分野の最先端の研究成果をライフサイクル全体の観点から体系的に整理した初めての試みである。このマトリックスは、成熟したATT&CKフレームワークを理論的基礎とし、AIシステムが遭遇する可能性のある攻撃プロセスと技術的実装手段を敵の視点から解明することで、企業が迅速にリスクポイントを特定し、脅威レベルを評価し、防御策を展開できるようにしたものである。本稿ではAIセキュリティ脅威マトリックスの中核をなすコンテンツであり、主な攻撃ベクトルを体系的に分析し、企業防衛のためのベストプラクティスを多角的に提供している。
AIセキュリティ脅威マトリックス:コア・フレームワークと分類システム
2.1 ATT&CK手法のAI領域への適用
ATT&CK(Adversarial Tactics, Techniques & Common Knowledge)フレームワークは、サイバーセキュリティの分野で比較的成熟しており、敵の視点から攻撃行動を体系的に記述することができます。AIセキュリティ脅威マトリックスは、まさにこの実証済みの方法論をAIの分野に適用し、実践的なガイダンスを構築したものです。AI Security Threat Matrixは、この実証済みの方法論をAIの分野に適用し、実践的なガイダンスとともに技術的なフレームワークを構築する。
従来のサイバーセキュリティ脅威モデルと比較した場合のAIセキュリティマトリックスの独自性は以下の通りである:
- 完全なライフサイクルのカバー:環境構築、データ収集、モデルのトレーニング、微調整と最適化、展開推論からメンテナンスとO&Mまで、マトリックスはAIシステムのあらゆる側面をカバーしている。
- 成熟度階層:攻撃技術は、成熟した脅威(実際に発生した攻撃)、研究中の脅威(学術研究によって検証されているが、まだ広く利用されていない)、潜在的な脅威(理論的には実現可能だが、実際にはまだ見られない)の3つの成熟度レベルに分類される。
- 攻撃者の視点に立った設計:攻撃者がどのようにAIシステムを突破するのかを段階ごとに直接提示し、防御者が攻撃ロジックの連鎖を理解できるようにする。
- 実践的ガイダンス:このマトリックスでは、脅威の説明に加え、的を絞った防衛策と緩和策を提示している。
2.2 AIセキュリティ脅威の主な分類

AIセキュリティ脅威マトリックスは、AIシステムに対する脅威を9つの主要分野に分類し、それぞれに複数の特定の攻撃ベクトルが含まれている:
| 脅威カテゴリー | コア機能 | 主な影響寸法 |
|---|---|---|
| データポイズニング/ミスリード(ポイズニング) | トレーニングデータや微調整データに悪意のあるサンプルを注入する | 誠実さ、信頼性 |
| 敵対的 | 微細摂動ミスディレクション・モデルによる推論 | 誠実さ、信頼性 |
| プライバシー | トレーニングデータの抽出や機密情報の推測 | 守秘義務、プライバシー |
| キュー・ワード・インジェクション(迅速な注射) | セキュリティを迂回するための悪意あるコマンドの構築 | 完全性、可用性 |
| モデルの引き抜き/窃盗(IPスレット) | クエリによってモデルの構造とパラメータを導出する。 | 知的財産、機密保持 |
| 誤用 | 有害な目的でのAIシステムの使用 | コンプライアンス、評判 |
| サプライチェーン攻撃 | 依存モデル、データ、コンポーネントの汚染 | 完全性、可用性 |
| 偏見と差別(バイアス) | モデルはトレーニングデータのバイアスを学習する | 公平性、評判、法的リスク |
| 不安定な出力 | モデル化されたファントム、ドリフト、不正確な出力 | 信頼性、評判 |
III.AI攻撃チェーン:偵察から実行までの完全なプロセス
AIセキュリティ脅威マトリックスは、攻撃の連鎖を中核的な組織フレームワークとして使用し、攻撃者がAIシステムの防御を段階的に突破する方法を明確にマッピングしている。このプロセスは、従来のサイバーセキュリティにおけるキルチェーン・モデルに似ているが、AIシステムのユニークな特性に合わせて特別に設計されている。
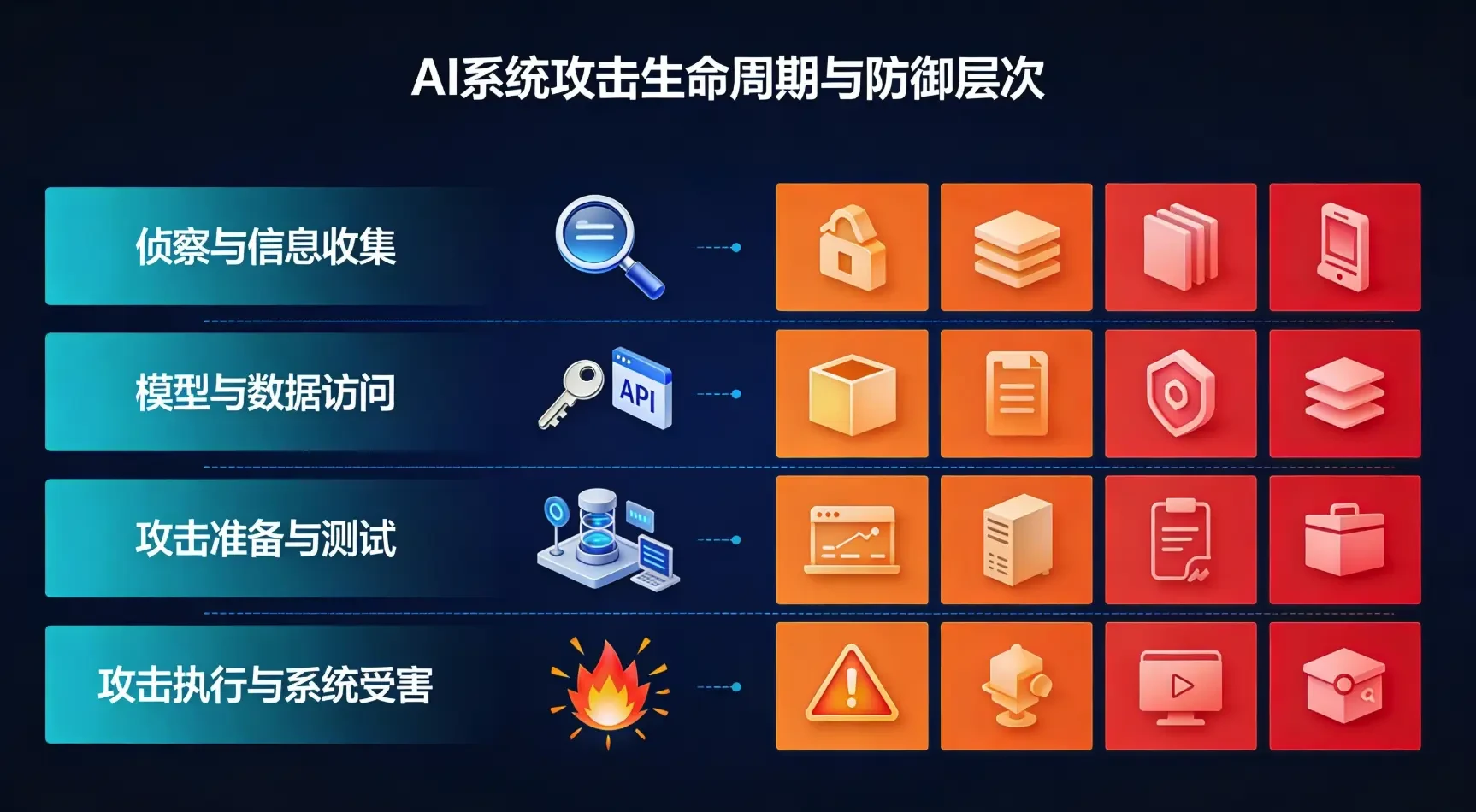
3.1 フェーズI:偵察と情報収集(偵察)
段階の特徴:攻撃者は、展開環境、使用されているモデルの種類、APIインターフェース、トレーニングデータの特徴など、ターゲットとなるAIシステムの全体的な状況を把握しようとする。
具体的な技術的手段:
- 公開情報の収集:学術論文、技術文書、学会発表、GitHubリポジトリ、モデルカードなどを通じて、対象モデルの技術的な詳細を入手する。
- APIプロービング:AIサービスのAPIを呼び出すことで、モデルの入出力特性を分析し、内部アーキテクチャを推測する。例えば、攻撃者は様々な種類のクエリを送信し、モデルの応答パターンを記録することで、その分類ロジックを推測することができる。
- 環境の特定:AIシステムがどのクラウドプラットフォーム上に展開されているか、どのオープンソースフレームワークまたは商用モデルが使用されているか、どのようなデータフロー方式が採用されているかを判断する。
防衛戦略
- 技術的な詳細の過度の開示を避けるため、モデル文書の開示の程度を制限する。
- APIクエリ頻度制限と異常動作検出の実装
- モデルに関連するオープンソースプロジェクトやソーシャルメディアでの議論を監視する。
3.2 フェーズ2:モデリングとデータアクセス(モデルアクセス)
フェーズの特徴:攻撃者は、後続のディープ・アタックに備え、ターゲットのAIシステムへの直接的または間接的なアクセスを獲得する。
具体的な技術的手段:
- ブラックボックス・アクセス:APIを通じてモデルに問い合わせ、信頼度スコアや確率分布などの出力情報を観察する。このタイプのクエリは低コストであるが、得られる情報は限定的であり、攻撃者は統計的手法によってモデルの特性を徐々に推測することができる。
- グレーボックスアクセス:部分的なモデル情報(中間層の出力や勾配情報など)を取得し、より正確な攻撃の設計を可能にする。
- ホワイトボックス・アクセス:モデル構造とパラメータへの完全なアクセス。通常、内部リークやモデルがクラックされた後に発生する。
防衛戦略
- 厳格なアクセス制御と認証の導入
- APIが返す情報の粒度を制限する(例えば、特定の確率値を返さず、分類結果のみを返すなど)。
- クエリー頻度制限と異常検知の展開
- プライバシーを強化する技術(たとえば差分プライバシー) ファジィ出力情報
3.3 フェーズ3:攻撃の準備とテスト(攻撃のステージング)
フェーズの特徴:攻撃者は、自ら構築した環境で攻撃方法を設計・テストし、その有効性を検証した上で、偵察フェーズとアクセスフェーズで得た情報に基づいて攻撃方法を微調整する。
具体的な技術的手段:
- 敵対的サンプル生成:自分自身のデータとモデルを使い、ターゲットモデルを惑わすような入力サンプルを設計すること。例えば、人間の目には知覚できないようなノイズを画像に加えることで、ターゲットとなる分類器は犬を猫として認識してしまう。
- データポイズニングサンプルの構築:ターゲットモデルが学習する際の判断を汚染するような悪意のあるトレーニングサンプルを設計する。
- プロンプトワード攻撃テンプレートの開発:LLMの機能を使用して、様々なタイプの脱獄プロンプトワードおよびインジェクション攻撃テンプレートを設計します。これらのテンプレートは、抑制の拒否、ロールプレイング、セマンティック難読化などを含む様々なテクニックを採用することができる。
防衛戦略
- 敵対的ロバストネス・テストの実施により、モデルの脆弱性を事前に特定し、修正する。
- 完全なモデル・ディフェンス蒸留と敵対的トレーニング・システムの確立
- 厳密な入力検証とクリーンアップの仕組みを導入する。
3.4 フェーズ 4: 攻撃の実行とシステム被害 (実行)
フェーズの特徴:攻撃者は、あらかじめ決められた目標を達成するために、十分に設計された攻撃を実際の標的システムに仕掛ける。攻撃対象によって、このフェーズにはさまざまな手法が含まれる:
3.4.1 データ・ポイズニング攻撃(データ汚染)
原理:攻撃者がモデルの学習データや微調整データに悪意のあるサンプルを注入し、モデルに誤ったマッピング関係を学習させる。
特定のタイプ
- ラベル反転攻撃:正常なサンプルのラベルを反転させる、例えば「正当なメール」を「スパム」とラベル付けする。約0.0011 TP3Tのデータを汚染するだけで、重大なモデルの失敗を引き起こす可能性があることが示されている。
- 隠しラベル攻撃:サンプルのラベルを変更する代わりに、微妙な特徴トリガーを挿入することで、特定の条件下で攻撃者が指定した結果をモデルが出力するようにする。この攻撃は検出がより困難です。
- 例えば、「爆発」に関連する視覚的要素を「花」のトレーニング画像に追加すると、モデルは「花」を「危険」と関連付ける。これにより、モデルは「花」を「危険」と関連付ける。
防御メカニズム:
- データのクリーニングと検証:トレーニングデータの異常値検出と統計分析により、毒殺の疑いのあるサンプルを特定し、除去する。
- ロバストなトレーニング:敵対的トレーニングのような技術を用いて、モデルは汚染されたデータに対する耐性を学習する。
- データの多様性:信頼できる複数のソースからトレーニングデータを収集することで、単一のデータソースが完全に管理されるリスクを低減する。
- 差分プライバシー:個々のサンプルがモデルに与える影響を制限するために、トレーニング中にノイズを加える。
3.4.2 逆境的なサンプルと逆境的な攻撃(逆境的な例)
原理:攻撃者は、人間にはほとんど見えない入力に精巧な摂動を加えることで、モデルに誤った予測をさせる。
典型的なケースだ:
- 画像分類攻撃:慎重に計算されたノイズを写真に加え、自動操縦システムに道路標識を誤認させる。
- 音声認識攻撃:人間の聴覚では知覚できない周波数を音声に埋め込み、音声アシスタントに意図しないコマンドを実行させる。
防御メカニズム:
- 防御的蒸留:生徒モデルをより頑健な教師モデルでトレーニングすることで、敵対的サンプルに対するモデルの感度を下げる。
- 正則化手法:L1/L2正則化などの制約を使用して、モデルが特定の入力パターンにオーバーフィットするのを防ぐ。
- 異常検知:推論中に拮抗サンプルと疑われる入力を特定し、拒否するために異常サンプル検知器を配置する。
- 入力の変換と再構成:入力がモデルに入る前にノイズ除去を行う(JPEG圧縮、ガウシアンフィルタリングなど)。
3.4.3 プライバシー漏洩とメンバーシップ推論攻撃 (Privacy Leakage & Membership Inference)
脅威のシナリオ
- 学習データの抽出: 攻撃者はモデルへのクエリーを繰り返すことで、モデルの学習に使用した実データを徐々に復元する。例えば、利用者の個人情報を含む医療記録や財務データを回収することができる。
- モデル反転攻撃(MIA):攻撃者はモデルの出力を分析し、特定の入力に対応する学習データの特徴を推測する。顔認識モデル上で、攻撃者はモデルの信頼度出力に基づいて元の顔画像を再構築することができます。
- メンバーシップ推論攻撃(MIA):攻撃者はモデルの行動特性を利用して、特定のデータポイントがトレーニングに使用されたかどうかを推論する。これは、特に医療や金融のような機密性の高い分野において、プライバシー保護に対する深刻な脅威となる。
防御メカニズム:
- 差分プライバシートレーニング:勾配またはデータに注意深く設計されたノイズを加えることで、個々のサンプルの除去がモデルの挙動を大きく変えないようにする。
- データの分類と最小化:機密データをラベリングし、モデルトレーニングでの使用を制限する。
- Federated Learning(分散型学習):複数のエッジデバイス上でモデルの分散型学習を行い、中央システムから完全な学習データにアクセスできないようにする。
- 推論検出:モデル生成されたテキストからプライバシー侵害リスクを特定する検出パイプラインの構築。
3.4.4 プロンプト・インジェクションと脱獄攻撃 (Prompt Injection & Jailbreak)
原則:攻撃者は、有害、不快、または予想以上のコンテンツを生成するような入力プロンプトを注意深く作成することで、LLMのセキュリティ安全装置を回避しようとする。
具体的な攻撃
- 直接的なキュー・ワードの注入:
- 攻撃者は、特殊文字や奇妙な接尾辞、意味のない記号を混ぜて、モデルのセキュリティ・フィルタリング機構を混乱させる。
- 拒絶抑制:逆心理学や間接的表現によって、モデルが「それはできない」という安全規則を無視するように誘導する。
- ロールプレイング:モデルを架空の物語のシナリオに引きずり込むと、間違った方向に誘導しやすくなる。
- 間接的な手がかりとなる言葉の注入:
- ウェブデータ・ポイズニング:期限切れでモデルのトレーニングデータに登場したドメインを購入し、悪意のあるコンテンツを埋め込み、モデルがそれを取得する際に汚染する。
- 隠し命令注入:一見何の変哲もない画像、音声、PDFに特別な命令を埋め込み、モデルがマルチモーダル入力を処理する際に起動させる。
- 敵対システムがリークを促す
- 攻撃者は、システムから来たように見えるメッセージを偽造し、モデルの制約を知るために、モデルに隠れシステムのキューワードを出力するように仕向ける。
防御メカニズム:
- 入力のフィルタリングとクリーニング:事前に定義されたブラックリストとルール。しかし、複雑なセマンティック攻撃をすべてカバーするルールは難しいことを認識する必要がある。
- モデルベースの異常検出:悪意のあるキューワードを識別するために検出モデルを使用すると、ブラックリスト方式よりも柔軟性があります。
- 意図認識:特別な意図認識モジュールを追加し、ユーザーが超法規的な操作を行おうとしているかどうかを判断する。
- 敵対的訓練:モデルの耐性を向上させるために、訓練データに「キューが注入された正解」サンプルを追加する。
- マルチモデル交差検証:同じ入力を複数のLLMで並列処理し、出力結果の整合性を比較する。
- 出力一致検出:モデルの出力が元のタスクと一致するかどうかチェックされ、予想から外れた回答は拒否される。
3.4.5 モデルの抽出と知識の盗用(モデルの抽出)
原理:攻撃者は、広範なクエリーとリバースエンジニアリングによって、対象モデルの構造、パラメータ、または動作をコピーまたは導出することで、モデルの知的財産を盗む。
具体的なテクニック
- ブラックボックス・モデル・レプリケーション:統計的APIコール・パターンを通してターゲット・モデルの振る舞いをシミュレートするために代替モデルをトレーニングする。
- 勾配逆解析:モデルの出力勾配情報を使用して、モデルのパラメータを段階的に導出する。
防御メカニズム:
- モデルの電子透かし:モデルの所有権を確認し、盗まれたコピーを検出するために、モデルのパラメータに秘密の電子透かしを埋め込む。
- クエリ制御:APIクエリの頻度を制限し、異常なクエリパターンを検出して拒否する。
- 出力の難読化:APIから返される情報の粒度を下げる。例えば、最終的な分類結果のみを返し、信頼度は返さない。
IV.サプライチェーンと生態系の安全保障:AIシステムに対する新しいタイプの脅威
AI導入のエコシステムが急成長する中、サプライチェーンのセキュリティは無視できない新たな次元となっている。企業はAIシステムをゼロから構築することはほとんどなく、事前に訓練されたモデル、オープンソースのフレームワーク、サードパーティのAPI、クラウドコンピューティングサービスを統合することで迅速に導入している。この非常に複雑なサプライチェーンシステムは、前例のないリスクをもたらす:
4.1 サプライチェーン・リスクのモデル化
- 事前に訓練されたモデルの汚染:オープンソースのモデルや信頼できないソースからのモデルの重みは、ポイズニングされているか、バックドアが埋め込まれている可能性があります。
- 依存関係の脆弱性:使用されているディープラーニングフレームワークや依存パッケージには、攻撃者に悪用される可能性のある既知の脆弱性やゼロデイ脆弱性が存在する可能性があります。
- ファインチューニングデータのリスク:事前に訓練されたモデルに基づいてファインチューニングを行う場合、ファインチューニングデータが汚染されていると、モデル全体が破損する可能性がある。
4.2 サプライチェーンの防衛戦略
- ベンダーの評価と認証:すべてのサードパーティーベンダーのセキュリティ監査を実施し、会社のセキュリティ基準に準拠していることを確認する。
- 部品表(SBOM)管理:モデル、フレームワーク、依存パッケージのソースとバージョンを追跡し、詳細なソフトウェア部品表を管理します。
- モデル署名と検証:配備されたすべてのモデルにデジタル署名を行い、改ざんを防ぎます。
- 継続的モニタリングと脆弱性スキャン:AIシステムの全コンポーネントの脆弱性スキャンとセキュリティ評価を定期的に行う。
V. 企業のAIセキュリティ保護のための階層的防御システム
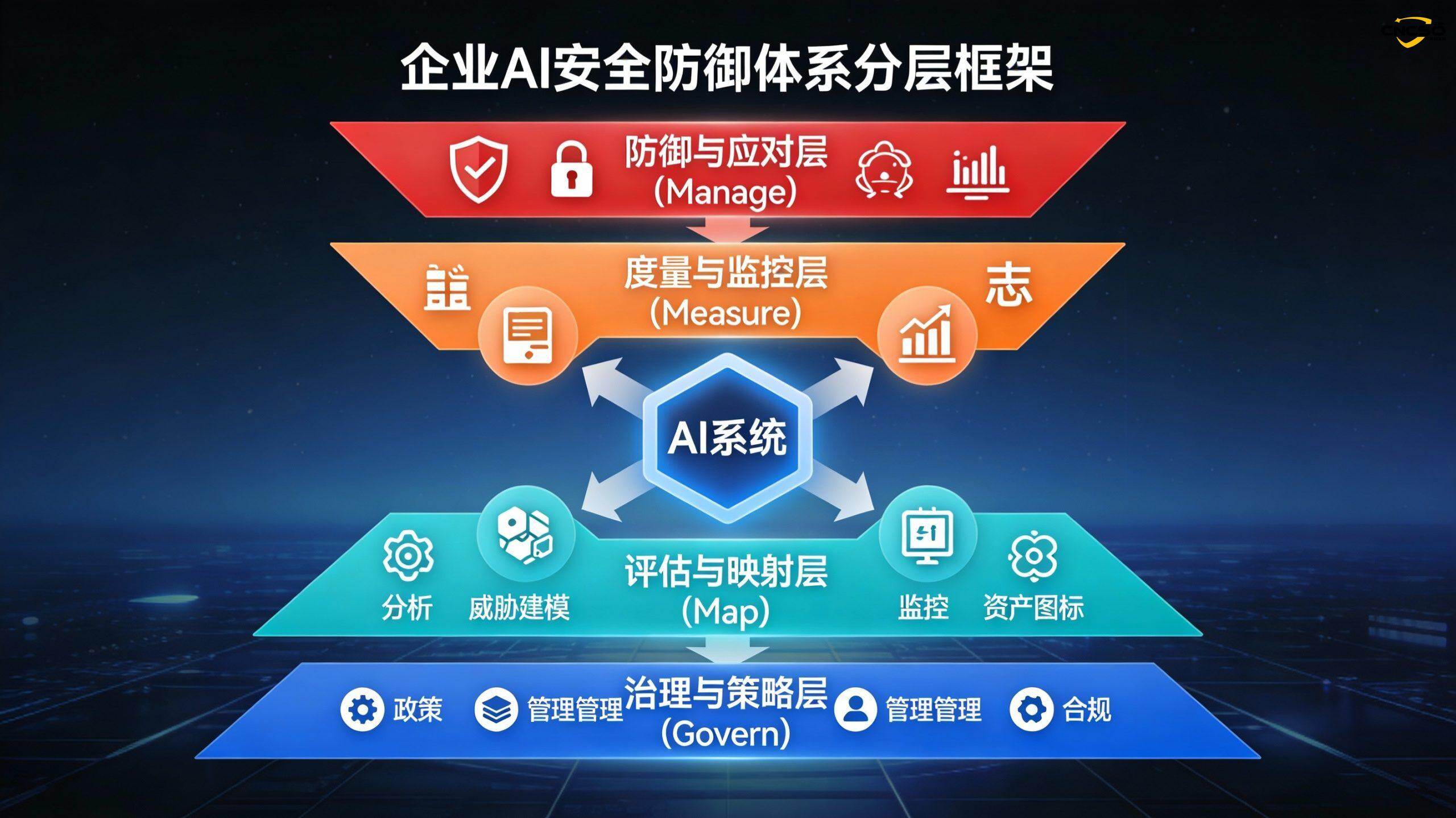
5.1 第1層:ガバナンスと戦略層(ガバナンス)
目標:組織レベルのAIセキュリティ文化と枠組みを確立し、AIセキュリティがトップからボトムまで真剣に取り組まれるようにする。
重要なコントロール
- AIセキュリティポリシーの策定:組織の理解を明確にするAIシステムのセキュリティポジション、要件、基準。
- リスク管理プロセス:AIのセキュリティリスクを特定、評価、対処するための標準化されたプロセスを確立し、すべての新規AIアプリケーションがリスクレビューの対象となるようにする。
- 役割と責任:データ所有者、モデル開発者、セキュリティエンジニアなど、組織内のAIセキュリティの責任者を特定する。
- コンプライアンス要件:規制要件(GDPR、AI法等)に沿った適切なコンプライアンスフレームワークを構築する。
5.2 レイヤー2:アセスメントとマッピングレイヤー(地図)
目標:AIシステムにおける潜在的なリスクポイントを包括的に特定し、その後の防衛策の基礎を提供する。
主な活動
- 資産目録:組織内のすべてのAIモデル、データセット、アプリケーション、インフラを列挙し、分類してラベル付けする。
- 脅威モデリング:脅威モデリング手法(STRIDEなど)を用いて、想定される攻撃シナリオを体系的に特定する。
- データフロー分析:AIシステム全体におけるデータの流れを追跡し、データ漏洩のリスクポイントを特定する。例えば、さまざまな段階で機密性の高いユーザーデータがどこに保存され、どこにアクセスされているかなど。
- 依存関係分析:モデル間の依存関係をマッピングし、クリティカルパスと単一障害点を特定する。
5.3 ティア3:測定とモニタリング ティア(測定法)
目標:定量的な指標と監視メカニズムを通じて、AIシステムのセキュリティ状況を継続的に評価する。
主な指標とメカニズム:
- モデル性能のベースライン:通常運用時の性能(精度、待ち時間、スループットなど)のベースラインを確立し、攻撃やモデルのドリフトを示す可能性のある異常を検出する。
- セキュリティ監査ログ:モデルのすべての入力と出力、構成変更、アクセス権限変更などを完全に記録し、イベント調査とフォレンジックに使用する。
- 敵対的ロバスト性評価:モデルは定期的にサンプルに対してテストされ、攻撃に対する耐性を評価する。
- プライバシー評価:メンバーシップ推論攻撃などの技術を使用して、モデルが訓練データを過剰に記憶していないかどうかを評価する。
- 行動異常検知:モデルの出力行動をリアルタイムで監視し、攻撃が成功したことを示す可能性のある、過去のパターンからの著しい逸脱を特定する。
5.4 ティア4:防衛・対応ティア(管理する)
目的:リスクの可能性と影響を低減するための具体的な技術的管理措置を実施する。
具体的な対策
データ層の保護
- データの分類とラベリング:データを機密性に応じて分類し、機密性の高いデータにはより厳格な保護を実施する。
- アクセス制御:最小特権の原則を実施し、誰がどのデータにアクセスできるかを制限し、ID、役割、コンテキストに基づいて権限を管理する。
- データの暗号化:データの傍受や漏洩を防ぐため、送信と保存に強力な暗号化を使用する。
- データの非感覚化と匿名化:トレーニングやデータ提示の際に、センシティブな個人情報を削除または暗号化すること。
モデル層の保護
- 敵対的訓練:モデルの頑健性を向上させるために、訓練過程で敵対的サンプルを追加する。
- 正則化と防御的蒸留:正則化技術を使用してオーバーフィッティングを減らし、蒸留を使用してモデルを圧縮し、頑健性を高める。
- 差分プライバシー:勾配更新にノイズを加え、個々のサンプルがモデルに与える影響を制限する。
- モデルの検証とテスト:敵対的サンプルテスト、プライバシー評価など、配備前の包括的なセキュリティテスト。
- モデルの署名と完全性の検出:デジタル署名を使用してモデルが改ざんされていないことを確認し、ハッシュチェックを使用してリアルタイムで異常を検出する。
アプリケーション層の保護
- 入力検証とクリーニング:すべてのユーザー入力の厳格な検証とクリーニングを行い、悪意のある入力や異常な入力をフィルタリングする。
- 出力フィルタリング:モデルの出力がユーザーに表示される前に、有害、違法、または機密情報を含む出力を拒否するためのコンテンツレビューが実行されます。
- レート制限とクエリ制御:単一のユーザーまたはIPに対するクエリの頻度と数を制限し、不正使用を防止します。
- RAGシステムのデータソース管理:RAG(Retrieval Augmented Generation)を使用する場合、悪意のあるコンテンツの注入を防ぐため、外部のデータソースは厳密に管理され、監査される。
組織層の保護
- 従業員向けセキュリティ研修:AIセキュリティの脅威に対する技術チームの意識を高め、安全な開発手法を指導する。
- インシデント対応計画:検知、隔離、調査、復旧を含む、インシデントへの明確な対応プロセスを策定する。
- ベンダー管理:サードパーティベンダーのセキュリティ慣行を定期的に監査し、それらが会 社の基準を満たしていることを確認する。
- 第三者評価:外部のセキュリティ組織を招き、独立した侵入テストとセキュリティ監査を実施する。
VI.AIセキュリティフレームワークの標準化:ISO/IEC 42001とNIST AI RMF
6.1 ISO/IEC 42001:AIマネジメントシステム規格
ISO/IEC 42001は、AIマネジメントシステムに関する最初の国際規格であり、組織がAIマネジメントシステムを確立し、維持するための構造化されたガイダンスを提供する。主な特徴は以下の通り:
- 幅広い範囲:計画から運用・保守まで、AIシステムのライフサイクル全体をカバー。
- 39 管理統制:AIガバナンス、リスク管理、データ保護、透明性など幅広い側面をカバーする。
- 認証監査: 第三者による監査と認証をサポートし、組織が認証の妥当性を確認できるようにします。AIセキュリティの実践。
6.2 NIST AI リスクマネジメントフレームワーク(NIST AI RMF)
NIST AI RMFは、米国国立標準技術研究所(National Institute of Standards and Technology)が発表した自主的なフレームワークで、AIのリスク管理に焦点を当て、4つの中核的機能を含んでいる:
- ガバナンス:リスクを認識する文化を確立し、リスク管理の方針とプロセスを定義する。
- 地図:AIシステムにおける潜在的リスクの特定
- 対策:特定されたリスクの可能性と影響を評価する。
- 管理:リスク軽減策の実施
6.3 2つのフレームワークの相乗的適用
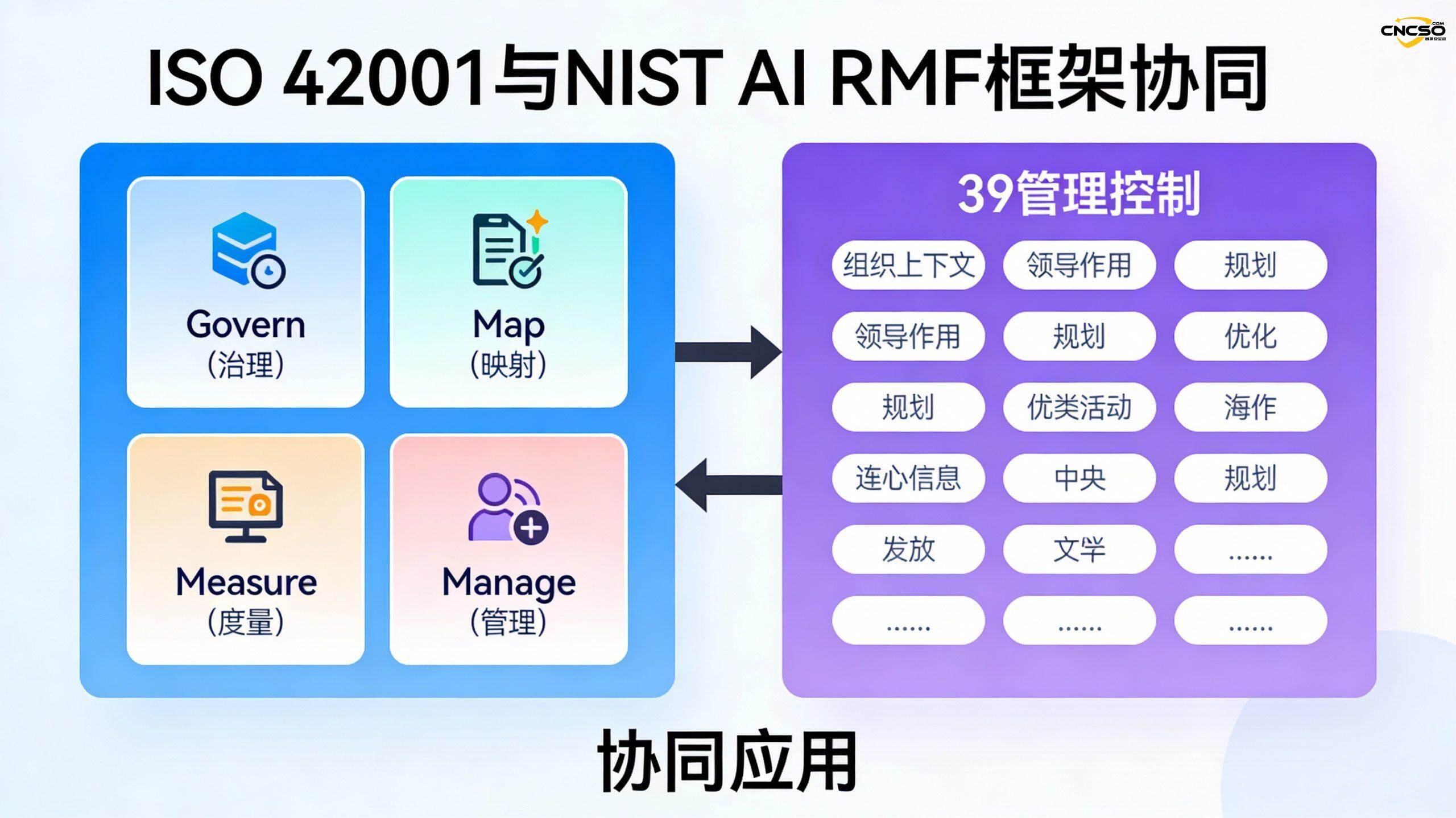
企業はISO/IEC 42001とNIST AI RMFを併用することができる:
- NIST AI RMFを用いたAI固有のリスク識別と評価
- ISO/IEC 42001を活用したより包括的なAIマネジメントシステムの構築
- 2つのフレームワークのマッピング関係により、組織はより効率的にコンプライアンスを達成することができる。
VII. 実践事例とベストプラクティス
7.1 ケーススタディ:攻撃の観点から見たAIシステムの攻撃連鎖
AIのセキュリティ脅威が実際にどのように発生するのかをより深く理解するために、現実的な攻撃シナリオであるマルウェア検知モデルのバイパス攻撃を分析してみよう:
第一段階:偵察
- 攻撃者は、ある企業が使用しているマルウェア検出モデルが学術論文に掲載された手法に基づいていることを発見した。
- 同社のブログと技術文書を分析したところ、特定のオープンソース・フレームワークが使用されていることが判明した。
ステージ2:モデル訪問
- 攻撃者は、同社のセキュリティAPIを通じてクエリーを繰り返し、さまざまな入力に対するモデルの反応を観察する。
- モデルの分類決定境界は、統計分析によって推測される。
ステージIII:攻撃の準備
- 同じようなモデルを自分の環境で再現した
- マルウェアを正規のソフトウェアとして分類するようにモデルを騙すことができる勾配降下法を用いた敵対的サンプルの設計
- 敵対的サンプルに一般的なバイパス機能を追加することで、ターゲットモデルに対して確実に機能するようにする
ステージIV:実施
- 慎重に作成されたマルウェア・サンプル(バイパス機能を含む)を会社の検知システムに提出する。
- このモデルは正規のソフトウェアとして誤って分類し、マルウェアは防御を回避することに成功した。
守備の啓示
- このような微妙な摂動に対してモデルが敏感に反応するようにするためには、敵対的ロバストネス・トレーニングを実施する必要がある。
- 正規のソフトウェアのように見えるが、異常な動作をするソフトウェアを検出するための動作解析の導入
- 攻撃者による大規模なプロービングを防ぐために、APIクエリの頻度制限と異常パターン検出を行う。
7.2 エンタープライズAIセキュリティ構築のためのベストプラクティスの提言
AIセキュリティの脅威マトリックスと防御フレームワークに基づいて、企業はAIセキュリティシステムを構築する際に以下の原則に従うべきである:
- リスク主導の優先順位付け:ビジネスへの影響と脅威の可能性に基づいて防御の優先順位を決める。万能を求めるのではなく、高リスク、高インパクトの分野にリソースを集中させる。
- フルライフサイクル・カバレッジ:モデルの推論フェーズに焦点を当てるだけでなく、データ収集、トレーニング、微調整、デプロイメント、メンテナンスのあらゆる側面を保護する。
- 防御の深さ:レイヤー防御(例えば、本稿で提案する4レイヤー防御システム)は、単一障害点を回避するために、複数のレベルで制御を展開するために使用される。
- 継続的な進化:AIのセキュリティ脅威は常に進化しており、組織は継続的な脆弱性管理、侵入テスト、防御の更新メカニズムを確立する必要がある。
- チーム横断的な協力:AIセキュリティはセキュリティ・チームだけの責任ではなく、AIエンジニア、プロダクト・マネージャー、法務、運用、保守など複数のチームの協力が必要である。
- 透明性と解釈可能性:ユーザーや利害関係者に対し、AIシステムの能力、限界、安全対策を明確に説明することで信頼を築く。
結論:将来を見据えたAIセキュリティシステムの構築
AIセキュリティ脅威マトリックスは、AIシステムに対する多次元的な脅威を特定し対応するための体系的かつ実行可能なフレームワークを組織に提供する。従来のサイバーセキュリティとは異なり、AIセキュリティは他に類を見ないほど複雑です。攻撃はデータ、モデリング、推論のあらゆる側面で発生する可能性があり、攻撃者の能力と知識レベルは攻撃の実行可能性に大きな影響を及ぼします。
企業は次のことを認識すべきである:
- AIのセキュリティはシステム的な問題であり、単一の防御策に頼るのではなく、データガバナンスからモデル開発、アプリケーションの展開、運用、保守監視に至るまで、総合的に取り組む必要がある。
- 成熟度評価は重要です。現在成熟している脅威(例:データポイズニング、敵対的サンプル)とまだ研究中の脅威(例:より高度なプライバシー攻撃)を理解することは、組織がより良い防御投資を計画するのに役立ちます。
- 防衛と開発はバランスをとる必要がある。いくつかの防衛策(例えば、差分プライバシー、防衛蒸留)は、モデルの精度を低下させる可能性があり、企業は自社のビジネス特性に基づいてバランスを見つける必要がある。
- テクニカル・ディフェンスは、システムとプロセスによってサポートされる必要がある。技術的な防御だけでは十分とは言えず、健全なシステムを確立する必要がある。AIセキュリティ・ガバナンスシステム、スタッフ訓練の仕組み、事故発生時の緊急対応計画など。
- 標準フレームワークとの整合。ISO/IEC 42001やNIST AI RMFのような国際的に認知された標準フレームワークを採用することは、組織がAIセキュリティシステムを体系的に構築し、規制遵守に備えるのに役立つ。
AI技術の急速な進化と脅威状況の絶え間ない変化に直面して、企業は継続的に進化し適応するAIセキュリティシステムを確立する必要があり、AIセキュリティ脅威マトリックスはこのシステムの重要な基盤である。
参照引用
- AIセキュリティ脅威マトリックスの公式サイト:https://aisecmatrix.org/matrix
- NIST AIリスクマネジメントフレームワーク:https://airc.nist.gov/
- ISO/IEC 42001規格国際電気標準会議が発行するAIマネジメントシステム規格
- MITRE ATLASフレームワーク:AIと機械学習システムのためのATT&CKライクなフレームワーク
元記事はChief Security Officerによるもので、転載の際はhttps://www.cncso.com/jp/ai-security-based-on-the-attck-framework.html。







