
コア・イノベーション・ハイライト
インテリジェンス主導のアクティブ・ディフェンス・システム
伝統的データセキュリティプロテクションは長い間、「ブラックリスト+ルールエンジン」のリアクティブ・アーキテクチャに依存してきたが、その根本的な欠陥は、プロテクションが常に脅威の進化に遅れをとることである。国内初のデータ・セキュリティ・インテリジェント機関大規模な言語モデルに基づく推論エンジンを採用することで、システムは「知覚-認知-決定-応答」の完全なインテリジェントな閉ループを備えている。システムは既知の攻撃の特徴を識別できるだけでなく、ディープラーニングと強化学習メカニズムを通じて、未知の脅威に対する確率的予測と適応的防御を行うことができる。このインテリジェンス主導のパラダイムにより、セキュリティ保護は「受動的なキャッチアップ」から「能動的な予測」へと進化し、脅威発見の適時性と精度が大幅に向上する。
システムに内蔵されたAI分析エンジンは、ミリ秒単位のレイテンシーで異常なデータアクセス動作を検出することができる。大規模なデータ汎化モデルを構築することで、システムは企業環境における99%以上の機密データ型を特定し、そのフロープロセスをリアルタイムで監視することができる。この機能の実装は、企業データの深い意味理解と行動パターンの学習に基づいており、従来の正規表現ベースの検出方法と比較して、精度率が5~10倍向上しています。
ゼロ・トラスト・アーキテクチャの下でのきめ細かなパーミッションモデル。
クラウドネイティブやハイブリッドクラウドの本番環境では、従来の境界保護はまったく効果がなくなっている。最初の国内データセキュリティインテリジェントボディに基づいている。ゼロトラスト・セキュリティこのシステムは「最小特権」の原則を採用し、ユーザがいつでも自分の仕事の責任範囲内で最小限のデータセットにしかアクセスできないことを保証する。このシステムは、「最小特権」の原則に基づく動的な権限割り当てメカニズムを採用し、ユーザーがいつでも自分の職務責任範囲内の最小限のデータセットにしかアクセスできないようにしています。
このアーキテクチャの革新的な点は、AI主導のコンテクスチュアル・アウェアネス・エンジンを導入したことで、システムがアクセス時間、地理的位置、アクセスデバイス、アクセスモードなどの複数の要因に基づいて特権ポリシーを動的に調整し、異常なアクセスパターンの使用を防ぐことができる。特権の踏み越えや異常なログイン行動を検出した場合、システムは秒以下の遅延で隔離の判断を下すことができ、真の意味での「ID最小化、特権最小化、ネットワーク最小化」の3次元ゼロトラスト防御を実現する。
プライバシー・コンピューティングの技術革新とデータの不動性
AIアプリケーションの普及の時代において、データのプライバシーをいかに保護するか、データの価値をいかに発揮させるかが、企業が直面する中心的なジレンマとなっている。国内初のデータ・セキュリティ・インテリジェンス以下のような複数のプライバシー・コンピューティング技術の融合ソリューションが使用されている。信頼できる実施環境(TEE)、差分プライバシー(差分プライバシー)、セキュア・マルチ・パーティ・コンピューティング(SMC)など。
システムは、信頼されたハードウェア環境で実行することにより、これを実現します。AIモデルこの推論により、機密データが計算プロセス中に常に暗号化されることが保証され、「機密性を保持したまま計算を行う」というエンド-クラウド協調モデルが実現される。差分プライバシーのメカニズムは、勾配更新プロセス中に注意深く較正されたノイズを注入することで、モデルが1つのデータレコードにオーバーフィットするのを防ぎ、推論中に学習データ内のプライベート情報が誤って開示されるのを防ぎます。この技術の組み合わせにより、攻撃者がモデル全体にアクセスしたとしても、元の機密データを逆実行することはできない。
マルチインテリジェンス・コラボレーションによる自動化されたオペレーション能力
伝統的安全な操作センター(SOC)は、専門アナリストの深刻な不足と攻撃への対応効率の深刻な遅れという最大の課題に直面しています。中国初のデータ・セキュリティ・インテリジェンスは、マルチインテリジェンス協調アーキテクチャにより、脅威の検知、トレーサビリティ分析、影響評価、対応意思決定の完全自動化を実現します。
このシステムには、少なくとも5種類の特殊知能が含まれており、それぞれが異なる責任を負っている:Traffic Analytics Intelligenceは、「quintuple + timestamp + session ID」の複合インデックスを構築する。さらに、ペタバイト規模の履歴トラフィックから正確な検索を数秒で完了し、パスマッピングインテリジェンスは因果推論とベイズアルゴリズムに基づいて完全な攻撃チェーンを自動的に構築し、詳細な調査と判断インテリジェンスは脅威の実際の影響範囲を評価し、セキュリティエキスパートインテリジェンスは重要な証拠と改善勧告を含む分析レポートを自動的に生成し、アナリストインテリジェンスはアラームを一般化して判断し、作業割り当てを生成します。このコラボレーション・モデルにより、8~12時間かかっていた手作業によるトレーサビリティ作業が30分で完了し、トレーサビリティの効率が94%向上しました。
技術アーキテクチャの詳細分析
重層的な保護による多次元的なセキュリティ・システム
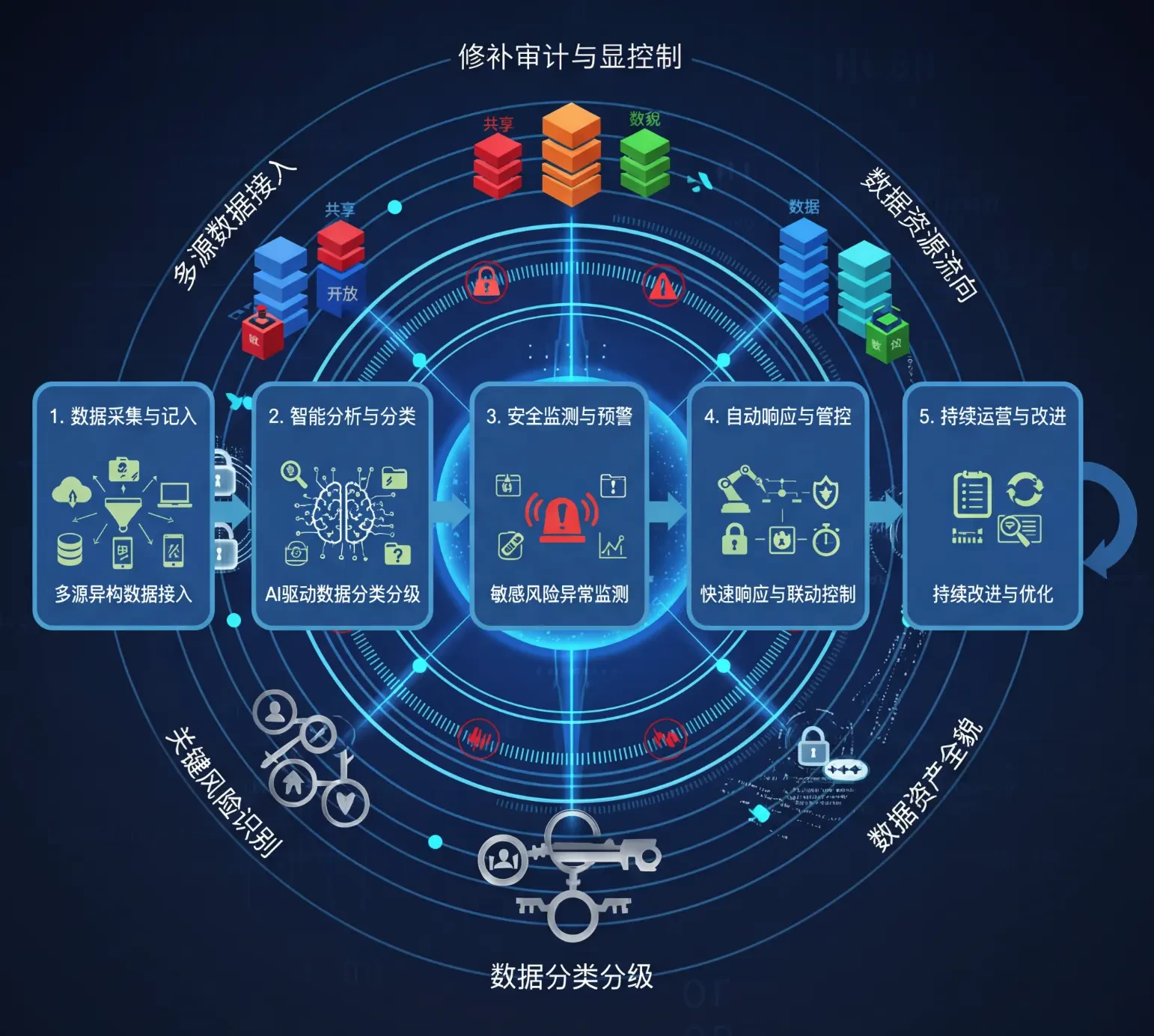
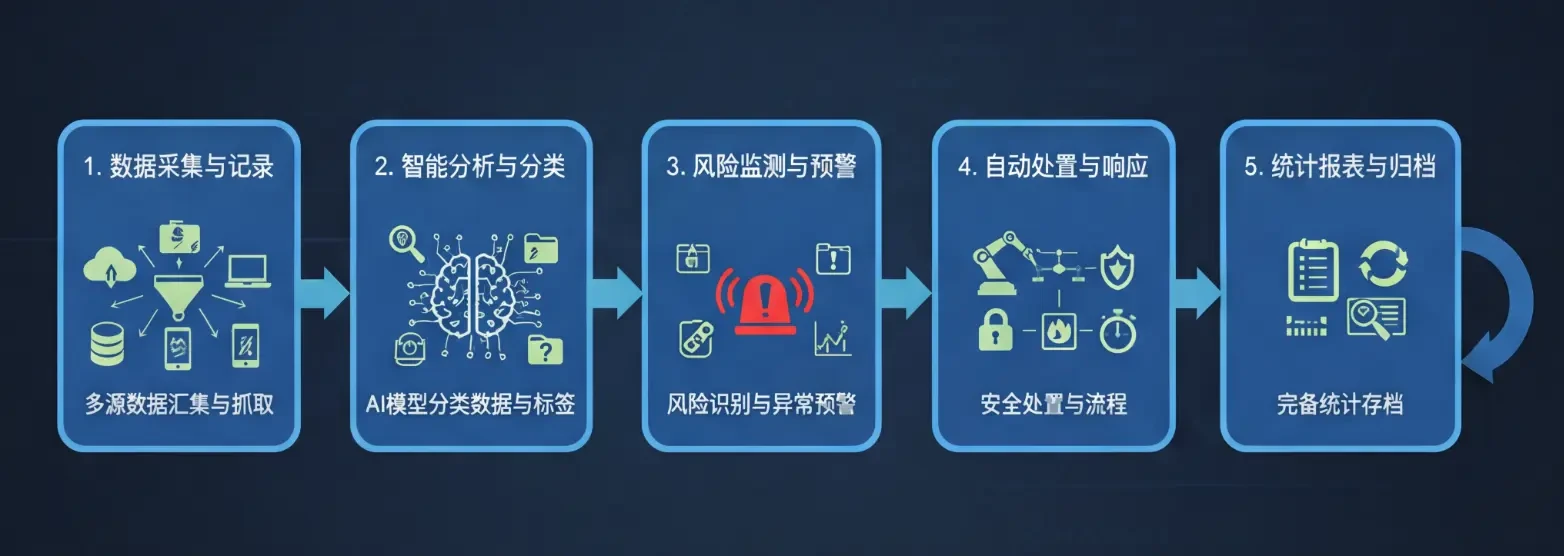
国内初のデータ・セキュリティ・インテリジェンスは、データ・フローの各段階で異なるセキュリティ・メカニズムを適用する、実証済みのレイヤード・プロテクション・アーキテクチャを採用している。このアーキテクチャは、下から上に向かって5つの主要なレイヤーに分かれている。
インフラストラクチャー層:物理的隔離、ネットワーク隔離、仮想化隔離による多重防御を提供します。VPC分離、サブネットセグメンテーション、マイクロセグメンテーションテクニックにより、攻撃対象領域を最小化します。
データ保存層:静的データの暗号化ストレージ、アクセス認証、監査証跡を実装。システムはAES-256アルゴリズムを使用して機密データを暗号化し、鍵管理サービス(KMS)を通じて安全な鍵ローテーションと分離を実現する。
アプリケーション処理層:パラメータ化されたクエリ、入力の検証、出力のフィルタリングという三重の防御ラインによって、SQLインジェクションやコマンド・インジェクションなどのアプリケーション層からの攻撃を防ぐことができる。LLMはこの層で厳密にサンドボックス化されており、生成されたコードは動的な型チェックと特権チェックの対象となる。
インテリジェント分析レイヤー:AIによる異常検知と脅威プロファイリングエンジンを導入し、すべてのデータアクセス行動をリアルタイムでスコアリング・分類します。このシステムは、異常なダウンロード、権限侵害、バッチクエリなど、リスクの高いパターンを特定することができます。
ガバナンス層の監査すべてのデータアクセス、変更、共有行動を記録し、完全な監査チェーンを形成する。セキュリティ・インシデントが発生した場合、監査ログは完全なイベントの再現と責任の追跡をサポートすることができる。
LLMとセキュリティのコンバージェンス・アーキテクチャ ナレッジ・ベース
中国初のデータ・セキュリティ・インテリジェンスのコアコンピタンスは、汎用ビッグ言語モデルと垂直ドメイン・セキュリティ知識ベースとの深い融合にある。システムはハイブリッド知識強化アーキテクチャを採用しています。
パラメトリックな知識:トレーニングデータには、国家標準システム(GB/T 35273、GB/T 40857など)、業界のベストプラクティス、攻撃シグネチャライブラリなどの構造化されたセキュリティ知識が組み込まれている。
ノンパラメトリックな知識:RAG(Retrieval-Augmented Generation)メカニズムにより、システムはリアルタイムの脅威インテリジェンス、既知の脆弱性データベース、規制ポリシーのテキストなどを含む外部の知識ベースを動的に呼び出すことができる。
解釈可能性の保証:監査コンプライアンスを満たし、ユーザーの信頼を得るためには、システムがセキュリティ上の決定を下す際の推論プロセスを明確に説明できることが重要です。モデル解釈に対するSHAPのようなアプローチにより、セキュリティチームは、AIシステムが特定の保護決定を下す理由を理解することができます。
このアーキテクチャの利点は、新しいタイプの脅威が出現したときに、システムがモデル全体を再学習する必要がなく、知識ベースを更新し、プロンプトを調整するだけで、新しいセキュリティシナリオに迅速に適応できることである。
主要コア・コンピテンシーのベンチマーク分析
インテリジェントな脅威検知機能
中国初のデータ・セキュリティ・インテリジェンスは、脅威検知の精度とスピードにおいて業界トップレベルに達している。このシステムで使用されている検知技術は以下の通り。
行動分析に基づく異常検知:時系列分析(ARIMA、Prophet)を使用したベースラインモデリングにより、非常に弱い行動偏差も識別できる。
コンテンツに基づく機密データの識別:自然言語処理とコンピュータ・ビジョンを組み合わせて、構造化データおよび非構造化データに含まれるPII、鍵、ソースコードなどの機密コンテンツを識別する。
アソシエーションに基づく高リスクリンクの特定グラフ・ニューラル・ネットワーク技術による事象間の因果関係の自動構築と多段階攻撃チェーンの特定
既知の機密データしか識別できない従来のDLP製品に比べ、システムの識別範囲は99%以上に達し、誤警報率は0.5%以内に抑えられており、国際的な先進レベルに達しています。
動的かつ適応的な保護メカニズム
従来の静的なセキュリティ・ポリシーが直面していた問題は、攻撃者がルールの抜け穴を見つけると、長期間にわたって保護をバイパスできてしまうことだ。中国初のデータ・セキュリティ・インテリジェンスは、動的適応型保護戦略を採用している。
フィードバックベースの戦略最適化:システムは強化学習アルゴリズムを使用し、保護ポリシーの実際の有効性を継続的に監視することで、保護ルールの重みを動的に調整し、保護ポリシーが現在の脅威環境に適合するようにします。
対決型ディフェンストレーニング:このシステムには敵対的な機械学習機能が組み込まれており、防御を回避する潜在的な方法を予測し、関連する防御を事前に強化する。
多次元的なリアルタイム意思決定不審な挙動を検知した場合、単純に「許可/遮断」の二値判定を行うのではなく、利用者の本人性、操作内容、操作環境などの多次元的な要素に基づき、追加認証の要求、危険度の高い操作の記録、アクセス速度の制限など、段階的な対応判定を行う。
実用シナリオと効果検証
金融業界向けAPTトレーサビリティ・アプリケーション
ある金融機関の実際のアプリケーションでは、中国初のデータ・セキュリティ・インテリジェンスが、高度な持続的脅威(APT)に直面して優れた能力を発揮した。攻撃者がイントラネットの横移動のためにソーシャル・エンジニアリングによって社内の従業員認証情報を入手した際、システムは部門をまたがる異常なデータ・アクセス行動を迅速に特定し、自動化されたトレーサビリティ・プロセスによって30分以内に完了させた。

完全な攻撃チェーンの特定(ウェブの脆弱性の悪用→ウェブシェルの埋め込み→イントラネットの横移動→データベースの権限取得→データのエクスポート→アウトバウンド)
影響を受ける資産とデータの正確な位置
攻撃者が使用するツールと暗号化キーの特定と解読
是正勧告と緊急対応プログラムの自動生成
この対応速度は、従来のセキュリティ・オペレーションと比較して20倍以上速く、データ侵害が発生するまでの時間を劇的に短縮する。
医療業界の患者プライバシー保護
ヘルスケア産業への応用において、中国初のデータ・セキュリティ・インテリジェンスの中核となる課題は、臨床医や研究者による合理的なデータ利用をサポートしながら、いかに患者のプライバシーを守るかである。このシステムのソリューションには以下が含まれる。
機密データの自動識別:このシステムは、患者名、ID番号、症例番号、診断記録などの幅広い機密フィールドを、人手を介さずに自動的に識別することができる。
動的脱感作戦略:訪問者の身元とアクセス目的に応じて、システムは自動的に異なるレベルの減感ポリシーを適用する。例えば、財務担当者が患者データにアクセスする場合、匿名化された料金情報しか見ることができませんが、担当医は完全な診察記録を見ることができます。
操作権限のきめ細かな制御:このシステムは、「誰がどのデータにアクセスできるか」だけでなく、「何が許可されているか」(閲覧、エクスポート、印刷、ダウンロード)も管理する。特定の機密データは「読み取り専用」のアクセスに制限され、さらに特定の操作には二次認証や医療倫理委員会の承認が必要となる。
このソリューションにより、ある医療グループの患者情報漏えいは年平均8~10件からゼロになり、代わりに臨床生産性が30%向上した。
消費財産業のための多次元データガバナンス
小売業や消費財企業では、データの断片化や事業部門間の頻繁な連携がデータセキュリティの課題となっている。大手ブランド企業が国内初のデータ・セキュリティ・インテリジェンスを採用した結果、以下のような成果が得られた。
販売分析、サプライチェーン連携、会員管理など様々なシナリオをカバーする、1000以上のビジネスシナリオに対応したデータセキュリティテンプレートライブラリを構築。
パーミッションの割り当てが手動承認から自動化され、承認サイクルが7日から2時間に短縮され、パーミッションの精度が「テーブルレベル」から「フィールドレベル」に改善された。”
GDPRおよび個人情報保護法のコンプライアンス要件を満たす、会員データへのアクセス、変更、エクスポートの完全な監査証跡による、機密データに関する操作の完全なトレーサビリティ。
データ漏洩リスクは「高リスク」から「管理可能」に格下げ、内部データ不正利用インシデントは減少 75%
従来のプログラムとの比較
DLP製品の機能的優位性を比較する
2010年代の企業セキュリティ保護の標準であった従来のデータ損失防止(DLP)製品は、核心的な限界に直面している。
| 比較次元 | 従来のDLP製品 | データ・セキュリティ・インテリジェンス |
| 検出方法 | 正規表現とブラックリストに基づく | ディープラーニングと大規模言語モデルに基づく |
| 脅威識別時間 | 後知恵分析、数時間遅れ | 100ms未満のレイテンシーでリアルタイム認識 |
| 未知の脅威からの保護 | 既知の脅威から身を守ることしかできない。 | 異常検知により未知の脅威を予測できる |
| ライツ・マネジメント | ビジネスの変化に対応しにくい静的なルール | コンテキストを考慮した動的適応サポート |
| 偽陽性率 | 15-25% | <0.5% |
| 営業費用 | 多数のセキュリティ・スペシャリストの必要性 | 自動化度 >90% |
| 規制遵守 | 受動応答 | GDPR/HIPAAへの積極的な対応 |
これらの比較は、国内初のデータ・セキュリティ・インテリジェンスが、データ保護のための新世代の技術パラダイムであることを十分に示している。
従来のセキュリティ・オペレーション・センターより進化
従来のセキュリティ・オペレーション・センター(SOC)は、人間のアナリストの専門知識と経験に強く依存していた。そのボトルネックは以下の通りである。
専門医の不足:市場のシニア・セキュリティ・アナリストの給与は年間50万円以上に達しており、中小企業はそのようなコストを支払う余裕がありません。中国初のデータ・セキュリティ・インテリジェンスは、人件費をソフトウェア・コストに置き換えることができ、10倍以上経済的です。
応答時間が長すぎる:従来のSOCは通常、中程度の複雑さのセキュリティ・イベントを分析するのに4~8時間かかるが、これは高度な脅威に直面した場合には十分とは言い難い時間枠である。このインテリジェントなシステムは、応答時間を30分未満に短縮することができました。
知識移転の難しさ:専門家が蓄積してきた経験を暗号化して継承することは困難であり、専門家が組織を離れると知識の喪失に直面する。ビッグ・ランゲージ・モデル」は、セキュリティの専門知識とベストプラクティスをパラメトリックにコード化し、知識の継続性と拡張性を確保する。
セキュリティとコンプライアンスの保証
多層セキュリティ認証メカニズム
中国初のデータセキュリティインテリジェンス機関は、LLM自体を十分に考慮した設計で、”幻覚問題”(Hallucination)が存在する、つまり、モデルは一見合理的に見えるが、実際には間違ったコンテンツを生成する可能性があります。このため、システムはマルチレベルの検証メカニズムを採用しています。
入力検証層:外部ソースからのすべての入力に対する厳格なサンドボックスとテイント・トラッキングにより、インジェクション攻撃を防ぐ。
プロセス検証レイヤー:LLMの推論プロセスでは、チェーン・オブ・ソート(思考の連鎖)とツリー・オブ・ソート(思考の木)により、完全な推論ステップをモデルが示す必要がある。
出力検証層:LLMによって生成された安全判断は、実行前にエキスパートシステムによって検証される必要があり、重要な判断は手動で確認される必要がある。
ポストホック検証層:システムは、実行されたすべてのセキュリティ操作を継続的に監視し、問題が検出された場合は直ちにロールバックするか、処理レベルをエスカレーションする。
このマルチレベルの検証により、たとえLLMにエラーがあったとしても、それがシステムのセキュリティ障害に直結しないことが保証される。
規制遵守のための組み込み設計
中国初のデータ・セキュリティ・インテリジェンスは、アーキテクチャ設計の段階でさまざまな規制コンプライアンス要件に完全に統合されている。
データ分類の階層:GB/T 35273、GB/T 40857などの国家標準に基づき、自動化されたデータ分類と等級付けエンジンを内蔵しています。
監査証跡の完全性:このシステムは、すべてのデータの収集、送信、保存、使用、共有、破棄のライフサイクル全体を記録し、GDPRやHIPAAなどの国際的な規制の要件を満たす監査ログを生成する。
プライバシー保護のための技術的措置差分プライバシーやホモモーフィック暗号化などの技術は、データがAIのトレーニングに合法的に使用される場合でも、個人のプライバシーが損なわれないことを保証する。
進化し続けるコンプライアンス:このシステムは、コンプライアンス・ポリシーの動的な更新をサポートしているため、コア・システムを変更する必要がなく、規制要件が変更された場合にナレッジ・ベースが更新されるだけである。
結論と今後の展望
ビッグ・ランゲージ・モデリング、マルチインテリジェンス・コラボレーション、プライバシー・コンピューティングを組み合わせた、国内初のデータ・セキュリティ・インテリジェンス、ゼロ・トラスト・アーキテクチャなどの最先端技術を結集している。企業データ保護パラダイムの画期的なアップグレード。従来の受動的、静的、マニュアル依存のプロテクション・システムに比べ、このシステムには以下のような特徴がある:
プロアクティブ:「修復」から「予測」へと進化し、脅威検知のレイテンシーを数時間からミリ秒へと最適化。
インテリジェンス:自動化の度合いが90%を超え、安全作業が「労働集約的なもの」から「自走式で効率的なもの」に変わる。
適応型:動的かつ適応的な保護戦略は、頻繁に人間が介入することなく、脅威環境の変化に追随して進化することができる。
信頼性:マルチレベルの検証メカニズムと完全に解釈可能な設計により、セキュリティの決定が正確で監査可能であることを保証する。
今後、強化学習や連合学習といった技術のさらなる成熟に伴い、国内初のデータ・セキュリティ・インテリジェンスは、以下のような方向でブレークスルーすることが期待される。
組織横断的なマルチインテリジェンス・コラボレーション:異なる組織のセキュリティ・インテリジェンスが、プライバシーを保護しながら、脅威インテリジェンスと保護経験を共有できる。
クラウド側とエンド側の協調防御:クラウド側の高度な分析能力とエンド側のリアルタイム防御能力の協調システムの構築
自律的なセキュリティ適応:システムは、人間の介入を最小限に抑えながら、保護戦略を学習し、進化させることができる。
全体として、国内初のデータ・セキュリティ・インテリジェント機関は、データ・セキュリティの「技術主導型」から「AI対応型」への重要な転換を示し、企業がAI時代に信頼性が高く、効率的で進化可能なデータ保護システムを構築するための完全なソリューションを提供する。
書誌
大規模言語モデルに基づくフルフロー・セキュリティ・インテリジェンス
インテリジェントボディAIセキュリティの枠組みとベストプラクティス
マイクロソフト データ損失防止(DLP)の定義と実装
360セキュリティ・インテリジェンスのアーキテクチャと応用
データ・セキュリティ・インテリジェンス本体のデザインパターンと実用化
AWSデータ損失防止(DLP)テクニカルアーキテクチャ
2025 データ・セキュリティの方向性とインテリジェント・オペレーション
ボルケーノ・エンジン・フェイリアン・データ・セキュリティ製品のアップデート
データセキュリティガバナンスのフレームワークと成熟度評価
データセキュリティ国家標準システム(2025年版)
私のブログは間もなくTencent Cloudの開発者コミュニティーに同期される予定です。https://cloud.tencent.com/developer/support-plan?invite_code=9mtn3hzk7c8
元記事はChief Security Officerによるもので、転載の際はhttps://www.cncso.com/jp/ai-powered-data-security-agent.html。







