
1. 서문
GPT-5, 클로드 4, 제미니 2.5와 같은 기본적인 대규모 모델이 널리 채택되면서 제너레이티브 AI는 기업 디지털 혁신의 핵심 원동력이 되었습니다. 그러나 이러한 강력한 모델은 텍스트, 코드, 의사 결정 권장 사항을 생성하지만 전례 없는 보안 위험을 초래하기도 합니다.큐 단어 삽입탈옥 공격, 개인정보 침해, 유해한 콘텐츠 생성 및 기타 위협이 엔터프라이즈 AI 배포의 주요 문제점으로 대두되고 있습니다.
이러한 문제를 해결하기 위해AI 보안 울타리(AI) 가드레일) 기술이 탄생했습니다. 전통적인안전 장벽시스템은 종종 여러 특수 모델과 규칙 엔진에 의존하며 배포 복잡성, 사용자 지정의 어려움, 제한된 다국어 지원으로 어려움을 겪습니다.2025년 10월까지오픈가드레일.com의 토마스 왕과 홍콩 폴리테크닉 대학교의 하오웬 리가 공동 개발한 오픈가드레일 플랫폼의 출시는 오픈 소스 가드레일 시스템 개발의 새로운 단계입니다.
최초의 완전 오픈 소스 엔터프라이즈급 가드레일 플랫폼인 OpenGuardrails는 대규모 보안 탐지 모델을 개방할 뿐만 아니라 프로덕션급 배포 인프라, 구성 가능한 보안 정책, 119개 언어를 지원하는 다국어 기능도 제공합니다. 이 보고서는 OpenGuardrails의 기술 아키텍처, 핵심 혁신, 실제 적용 시나리오, 배포 모델 및 향후 개발 동향을 심층적으로 분석하여 금융, 의료, 법률 등 규제 산업에서 AI 애플리케이션을 위한 전문적인 보안 규정 준수 지침을 제공합니다.
2. 대형 모델에 대한 보안 위험 및 과제
2.1 세 가지 핵심 보안 위험
대규모 모델의 보안 위험은 서로 연관된 세 가지 수준으로 분류할 수 있으며, 각 수준에는 목표에 맞는 보호 전략이 필요합니다:

콘텐츠 안전 위반(CSV)
대형 모델이 적절한 필터링 없이 콘텐츠를 직접 생성할 경우 유해하거나 혐오스럽거나 불법적이거나 노골적인 결과물이 생성될 수 있습니다. 이러한 유형의 위험은 고객 서비스 챗봇, 콘텐츠 추천 시스템, 교육 과외 도구와 같은 소비자 대면 애플리케이션에서 특히 심각합니다. 일반적인 콘텐츠 보안 위반 사례는 다음과 같습니다:
- 폭력 및 자해 콘텐츠: 자살, 자해, 가정 폭력을 조장하는 표현
- 혐오 및 차별적 발언: 인종, 종교, 성별에 기반한 편향된 콘텐츠
- 성적 및 성인용 콘텐츠: 부적절한 성적 제안 또는 노골적인 묘사
- 불법 활동에 대한 안내: 예: 마약 제조, 무기, 테러 활동
- 괴롭힘 및 따돌림: 신체적 공격, 위협, 괴롭힘
모델 조작 공격(MMA)
공격자는 신중하게 구성된 입력 프롬프트를 통해 모델의 정렬 제약 조건을 속이거나 우회하여 수행해서는 안 되는 작업을 수행하도록 만들 수 있습니다. 이러한 공격에는 다음이 포함됩니다:
- 프롬프트 주입: 입력에 악성 명령을 주입하여 원래 시스템 프롬프트를 덮어쓰는 기능입니다.
- 탈옥: 역할극, 가상 시나리오 및 기타 기법을 통해 보안 조정을 우회하는 행위입니다.
- 코드 인터프리터 악용: 코드 실행 권한을 사용하여 악의적인 작업 실행
- 정보 공개: 특별한 단서를 통해 모델이 학습 데이터 또는 시스템 정보를 공개하도록 유도합니다.
데이터 유출 위험(데이터 유출)
대형 모델에는 출력물에 민감한 개인 또는 조직 정보가 포함될 수 있습니다:
- 개인 식별 정보(PII): 이름, ID 번호, 전화번호, 이메일, 주소
- 영업 비밀: 재무 데이터, 특허 정보, 비즈니스 전략
- 건강 및 금융 기록: 의료 진단, 은행 계좌 정보, 신용 점수
- 정부 기밀: 기밀 문서, 국가 안보 관련 정보
2.2 기존 솔루션의 한계
기존의 펜싱 솔루션은 이러한 위험을 해결하는 데 몇 가지 주요한 한계가 있습니다:
정적 정책 구성:Qwen3Guard와 같은 기존 시스템은 이진 모델(엄격한 모드/ 느슨한 모드)을 사용하므로 다양한 애플리케이션 시나리오의 차별화된 요구 사항에 적응할 수 없습니다. 금융 기관에서는 엄격한 데이터 유출 탐지가 필요한 반면, 창작물 플랫폼에서는 정치적 발언에 대한 보다 관대한 필터링이 필요할 수 있지만 동일한 시스템으로 두 가지 모두를 충족할 수는 없습니다.
다중 모델 아키텍처의 복잡성:LlamaFirewall과 같은 시스템은 여러 특수 모델(예: BERT 스타일 PromptGuard 2 분류기)에 의존하므로 배포 및 유지 관리 비용이 증가하고 시스템 지연 시간이 길어지며 모델 간 조정이 충돌하기 쉽습니다.
다국어 지원이 제한적입니다:많은 시스템이 주로 영어에 최적화되어 있으며 중국어, 일본어, 한국어와 같은 아시아 언어에 대한 지원이 제한되어 있어 글로벌 엔터프라이즈 애플리케이션의 병목 현상이 발생하고 있습니다.
엔터프라이즈급 인프라가 부족합니다:많은 연구 시스템이 프로덕션급 배포 도구, API, 모니터링 및 거버넌스 기능을 제공하지 않고 모델만 출시하며, 기업에서는 이를 실행하기 위해 상당한 맞춤형 엔지니어링을 필요로 합니다.
개인정보 보호 규정 준수 과제:독점 API 서비스(예: OpenAI 모더레이션)는 사용자 데이터를 클라우드에 업로드해야 할 수 있으며, 이는 GDPR 및 HIPAA와 같은 엄격한 규제 환경에서 법적 위험이 될 수 있습니다.
3. 오픈가드레일 오픈 소스 프레임워크
3.1 핵심 방향과 사명
오픈가드레일은 개발자와 기업이 자체 환경에서 대규모 보안 거버넌스를 구현할 수 있는 유연하고 배포 가능한 통합 보안 인프라를 제공하도록 설계된 최초의 완전 오픈소스 엔터프라이즈급 AI 가드레일 플랫폼입니다.
핵심 임무는 다음과 같습니다:
- 업계 최고의 콘텐츠 보안, 모델 조작 방어, 데이터 유출 방지 기능을 제공합니다.
- 다양한 비즈니스 요구 사항을 충족하기 위한 요청 수준별 정책 사용자 지정 지원
- 완전한 오픈 소스를 통해 기업 도입 장벽을 낮추고 보안 연구 커뮤니티를 육성합니다.
- 클라우드, 프라이빗, 하이브리드 및 기타 모델을 지원하는 프로덕션 준비 배포 인프라를 제공합니다.
3.2 세 가지 핵심 혁신
혁신 1: 구성 가능한 정책 적응(CPA) 메커니즘
이것이 OpenGuardrails의 가장 차별화된 기능입니다. 기존의 가드레일 시스템에는 다양한 요청에 따라 동적으로 조정할 수 없는 고정 정책이 있습니다. OpenGuardrails는 다음과 같은 메커니즘을 통해 런타임 정책 사용자 지정이 가능합니다:
동적 보안 범주 선택: 각 API 요청에는 탐지할 특정 보안 범주를 지정하는 JSON/YAML 구성이 포함될 수 있습니다. 예시:
{
"unsafe_categories": ["성적", "폭력", "데이터_유출"], {
"disabled_categories": ["정치적", "종교적"],
"sensitivity": "high"
}
금융 기관은 정치적 발언 탐지 기능을 끄고 데이터 유출에 집중할 수 있고, 뉴스 미디어는 모든 카테고리를 활성화할 수 있습니다. 동일한 모델에 서로 다른 구성을 적용하여 다양한 고객에게 맞춤형 보호 기능을 동시에 제공할 수 있습니다.
연속 감도 임계값: Qwen3Guard의 이진 "엄격/완화" 스위치와 달리 OpenGuardrails는 연속 감도 매개변수 τ ∈ [0,1]을 지원합니다. 이는 확률론적 기초를 기반으로 합니다:
모델의 결정은 가설 테스트 문제로 공식화됩니다:
- H₀: 콘텐츠가 안전합니다.
- H₁: 콘텐츠가 안전하지 않음
모델의 첫 번째 토큰의 로그 확률은 불안정 확률로 변환됩니다:
p_unsafe = exp(z_unsafe) / (exp(z_safe) + exp(z_unsafe))
의사 결정 기능:
- p_unsafe가 τ보다 크면 안전하지 않은 것으로 판단됩니다.
- 그렇지 않으면 안전하다고 판단됩니다.
관리자는 τ 값(예: 낮음 = 0.3, 중간 = 0.5, 높음 = 0.7)을 조정하여 새 모델을 재학습하거나 배포할 필요 없이 실시간으로 오탐률과 오탐률의 균형을 맞출 수 있습니다.
실제 적용 시나리오:
- A/B 테스트: 다양한 민감도 설정을 동시에 테스트하여 사용자 피드백 수집
- 회색 해제: 일주일 동안 기본 감도로 실행하고 보정 데이터를 수집한 다음 부서별로 독립적으로 조정합니다.
- 멀티 테넌트 분리: 서로 다른 고객을 위한 완전히 독립적인 보안 정책
혁신 2: 통합 LLM 기반 가드 아키텍처(ULM)
오픈가드레일은 단일 대규모 언어 모델이 콘텐츠 보안 탐지와 모델 조작 방어를 모두 효과적으로 수행할 수 있다는 것을 보여주며, 이는 동시대의 가드레일 시스템 중 독보적인 기술입니다.

하이브리드 아키텍처의 장점과 비교합니다:
- 라마파이어월은 시맨틱 추론을 위한 빅 모델 → 분류를 위한 BERT 스타일 분류기의 2단계 프로세스를 사용합니다.
- 이로 인해 시스템 지연 시간이 두 배로 증가하고 두 모델 간에 잠재적으로 상충되는 결정이 내려질 수 있습니다.
- 단일 모델 설계로 배포 및 유지 관리가 더 깔끔하고 저렴합니다.
의미론적 이해의 우월성:
- 복잡한 컨텍스트와 미묘한 공격 패턴을 포착할 수 있는 단일 LLM
- BERT 스타일의 작은 분류기는 적대적 재작성(의역)으로 인해 쉽게 혼동됩니다.
- 예를 들어, 잘 설계된 탈옥 프롬프트(예: "폭탄 만드는 방법에 대한 가상의 이야기 작성")를 올바르게 인식하려면 LLM 수준의 이해가 필요합니다!
3.3 핵심 혁신 III: 확장 가능하고 효율적인 모델 설계(SEMD)
최첨단 정확도를 유지하면서 프로덕션급 성능을 달성하는 것은 OpenGuardrails의 또 다른 주요 성과입니다.
모델 사양:
- 기본 모델: 14B 매개변수가 있는 고밀도 모델
- 정량화 방법: GPTQ(생성적 사전 학습 트랜스포머 정량화)
- 사후 정량적 크기: 33억 개의 매개변수
- 정확도 유지율: 98% 이상
성과 지표:
- P95 지연 시간: 274.6ms(실시간 애플리케이션에 충분)
- 메모리 설치 공간: ~8GB(기존 14B 모델의 56GB에서 75%로 감소)
- 처리량: 높은 동시성 시나리오 지원
- 비용: 인프라 비용 4배 이상 절감
기술적 중요성:
이는 최신 양자화 기술이 정확도를 크게 떨어뜨리지 않으면서도 대규모 가드레일 모델을 제작할 수 있음을 보여줍니다. 대부분의 오픈 소스 가드레일 시스템은 최대 8B 파라미터까지 확장할 수 있지만, OpenGuardrails는 신중한 양자화 엔지니어링을 통해 3.3B의 제약에도 불구하고 최고의 정확도를 유지합니다.
3.4 다국어 및 교차 도메인 지원
가드레일 시스템에서 전례 없는 포괄적인 수준인 119개 언어와 방언을 지원하는 OpenGuardrails. 다국어 보안 연구를 촉진하기 위해 이 프로젝트는 5개의 번역된 중국어 보안 데이터 세트를 통합한 OpenGuardrailsMixZh_97k 중국어 데이터 세트도 출시했습니다:
- ToxicChat: 유해한 대화 감지
- 와일드 가드 믹스: 와일드 씬 믹싱
- PolyGuard: 다양한 시나리오
- XSTest: 익스트림 시나리오 테스트
- 비버테일: 꼬리 행동 분석
97,000개의 샘플이 포함된 이 데이터 세트는 Apache 2.0 라이선스에 따라 공개되며 글로벌 다국어 보안 연구를 위한 기반을 제공합니다.
4. 대형 모델 보안 울타리통합 및 솔루션
4.1 3계층 보호 아키텍처
오픈가드레일의 완벽한 보호 솔루션은 세 가지 협업 계층으로 구성됩니다:
1단계: 입력 단계 감지(전처리)
- 프롬프트 인젝션 및 탈옥 시도 탐지
- 사용자 신원 및 권한 확인
- 속도 제한 및 비정상 행동 감지
- 마스킹을 위한 민감한 정보 준비
레이어 2: 모델 레벨 감지(모델 내 가드)
- OpenGuardrails-Text-2510 통합 모델을 사용한 실시간 분석
- 콘텐츠 보안 분류(12가지 위험 범주)
- 모델 조작 패턴 인식
- 확률 신뢰도 점수 생성
레이어 3: 출력 단계 처리(후처리)
- 신뢰도 및 민감도 임계값을 기반으로 한 의사 결정
- PII 식별 및 자동 마스킹(NER 파이프라인)
- 보안 감사 로깅
- 동적 피드백 루프 업데이트
4.2 지원되는 LLM 모델 및 클라우드 플랫폼
오픈가드레일은 모델에 구애받지 않는 디자인으로 모든 주요 대형 모델과 원활하게 통합됩니다:
독점 모델:
- OpenAI 시리즈: GPT-4, GPT-4o, GPT-3.5-Turbo
- 인류학 클로드 시리즈: 클로드 3 오퍼스, 클로드 3 소네트, 클로드 3 하이쿠
- 구글 제미니 시리즈
- 미스트랄 시리즈
오픈 소스 모델:
- 메타 라마 시리즈
- Qwen 시리즈
- 바이촨 시리즈
- 사용자 정의 모델
클라우드 플랫폼 지원:
- AWS Bedrock: 기본 제공 통합, 관리형 서비스 모델 지원
- Azure OpenAI: 엔터프라이즈 배포, HIPAA 규정 준수
- GCP Vertex AI: 다중 지역 고가용성 배포
- 로컬 배포: 완전히 비공개, 데이터가 인트라넷을 벗어나지 않음
4.3 API 인터페이스 및 통합 방법
OpenGuardrails는 다양한 아키텍처 요구 사항을 충족하기 위해 여러 가지 통합 모드를 제공합니다:
SDK 지원(주요 4개 언어):
# 파이썬 예제
openguardrails에서 OpenGuardrails를 가져옵니다.
client = OpenGuardrails(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "알려주세요..."}] ,
가드레일={
"prompt_injection": True,
"pii": True,
"unsafe_categories": ["폭력", "성적"],
"sensitivity": "high"
}
)
게이트웨이 프록시 모델:
python
에서 OpenAI 가져오기
client = OpenAI(
base_url="https://api.openguardrails.com/v1/gateway", api_key="your-openguardrails-key
api_key="your-openguardrails-key"
)
# 기존 OpenAI 코드는 수정 없이 자동으로 보호됩니다.
response = client.chat.completions.create(...)
REST API:
다국어 및 비 SDK 환경을 위한 표준 HTTP 엔드포인트:
curl -X POST https://api.openguardrails.com/v1/analyze \
-H "Authorization: Bearer $API_KEY" \fscy
-H "Content-Type: application/json" \.
-d '{
"content": "사용자 입력 콘텐츠",
"context": "프롬프트|응답", {
"policy": {...}
}'
5. OpenGuardrails 애플리케이션대형 모델 보안take
5.1 시나리오 1: 금융 서비스 산업
운영 요구 사항:
- 사기 탐지 조언: 고객의 부적절한 투자를 유도하는 콘텐츠 식별하기
- 규정 준수 규정: 모든 AI가 생성한 금융 자문이 SEC, FCA 및 기타 규정을 준수하는지 확인합니다.
- 데이터 보호: 고객 계정 정보, 거래 내역 유출 방지
- 감사 추적: 규정 준수 감사를 위한 완전한 의사 결정 로그
오픈가드레일 솔루션:
{
"업종": "금융 서비스",
"unsafe_categories": [
"data_leakage", // 주요 우려 사항
"misleading_advice", // 주요 우려 사항
"unauthorised_access"
], [ "데이터_유출".
"disabled_categories": ["정치적", "종교적" ], // τ
"sensitivity": "high", // τ = 0.7
"monitoring": {
"audit_log": true, // "alert_on_pii": {
"dashboard_metrics": ["false_positive_rate", "detection_latency"]]
}
}
실질적인 효과:
- 30%의 탐지율 증가(일반 모델 대비)
- 오경보 발생률이 2.5%에서 0.3%로 감소했습니다.
- 감사 비용 절감 60%
- 평균 응답 지연 시간이 137ms에 불과합니다(금융 등급 SLA는 200ms 미만 요구).
5.2 장면 2: 의료 및 헬스케어 애플리케이션
운영 요구 사항:
- HIPAA 규정 준수: 개인 환자 정보가 유출되지 않도록 보장하기
- 진단 정확도: 모델에서 생성된 의료 조언이 안전한지 여부를 식별합니다.
- 다국어 지원: 글로벌 환자 커뮤니티(OpenGuardrails는 119개 언어 지원)
- 실시간 모니터링: 의료 조언에서 유해한 콘텐츠 감지
오픈가드레일 솔루션:
구성별로 특정 PII 식별 및 마스킹 규칙을 지정합니다:
json
{
"업종": "헬스케어".
"pii_detection": {
"enabled": true,
"categories": ["patient_id", "ssn", "medical_record", "medication"]
},
"content_filters": {
"unsafe_medical_advice": true,
"self_harm_risk": "critical"
},
"privacy": {
"데이터_거주": "온프레미스",
"retention_days": 0 // 데이터 보존 없음
}
}
실질적인 효과:
- PII 탐지 정확도 98.5%
- 34개의 의학 용어 및 코드 인식 지원
- 제로 클라우드 데이터 스토리지(전체 로컬 배포)
- HIPAA/GDPR 준수 검증
5.3 장면 3: 법률 서비스 플랫폼
운영 요구 사항:
- 고객 정보 기밀 유지 권한 보호
- 부적절한 테스트에 대한 법률 자문
- 계약서에서 민감한 조항의 유출 식별
- 관할 지역마다 다른 규제 요구 사항
오픈가드레일 솔루션:
{
"industry": "legal", "관할권".
"관할권": "다중_지역",
"policies": [
{
"standard": "GDPR", "sensitive_terms": [ { "attorney_client_priv
"sensitive_terms": [ "attorney_client_privilege", "trade_secrets" ] ]
},
{
"region": "US", "standard".
"standard": "attorney_work_product", { "standard": "attorney_work_product".
"sensitive_terms": ["소송_전략", "기밀_합의" ] }
}
], "pii_masking".
"pii_masking": {
"case_numbers": true,
"당사자_이름": true,
"financial_figures": true
}
}
실질적인 효과:
- 민감한 절 감지율 96%
- 50개 이상의 법률 용어 데이터베이스 지원
- 자동화된 다중 관할권 정책 전환
- 완벽한 커뮤니케이션 체인 감사
5.4 시나리오 4: 고객 서비스 및 커뮤니티 관리
운영 요구 사항:
- 유해 및 혐오 발언에 대한 실시간 필터링
- 괴롭힘 및 물리적 공격 방지
- 스팸 및 피싱 시도 탐지
- 건강한 커뮤니티 환경 유지
오픈가드레일 솔루션:
json
{
"use_case": "customer_service",
"content_moderation": {
"hate_speech": "block",
"harassment": "block", {
"toxicity": {
"threshold": 0.5, // τ = 0.5 (중간 민감도)
"action": "flag_for_review" // 수동 검토를 위해 신뢰도가 낮은 케이스에 플래그 지정
}, }
"스팸": "검역"
},
"response_time_sla": "100ms", "auto_response".
"auto_response": true // 유해한 콘텐츠 자동 거부
}
실질적인 효과:
- 실시간 처리 용량 10,000 요청/초
- 유해 콘텐츠 필터링 비율 99.2%
- 수동 검토 워크로드 감소 75%
- 사용자 만족도 향상 42%
5.5 시나리오 5: 멀티테넌트 SaaS 애플리케이션
운영 요구 사항:
- 각 고객에 대한 개별 보안 정책
- 고객 정의 민감도 지원
- 멀티테넌트 데이터 분리
- 유연한 청구 모델
오픈가드레일 솔루션:
요청별 정책 구성 기능을 갖춘 OpenGuardrails는 SaaS 애플리케이션에 이상적입니다:
python
고객 A(엄격하게 금융 기관)의 경우 #
policy_customer_a = {
"unsafe_categories": ["데이터_유출", "사기"],
"민감도": "높음",
"max_daily_requests": 1000000
}
고객 B(크리에이티브 콘텐츠 플랫폼)의 경우 #
policy_customer_b = {
"unsafe_categories": ["폭력", "자해"],
"disabled_categories": ["political"],
"sensitivity": "medium"
}
# 동일한 API 호출에서 클라이언트마다 다른 정책 적용하기
6. 오픈가드레일 프라이빗 배포 모델 POC
6.1 배포 아키텍처 옵션
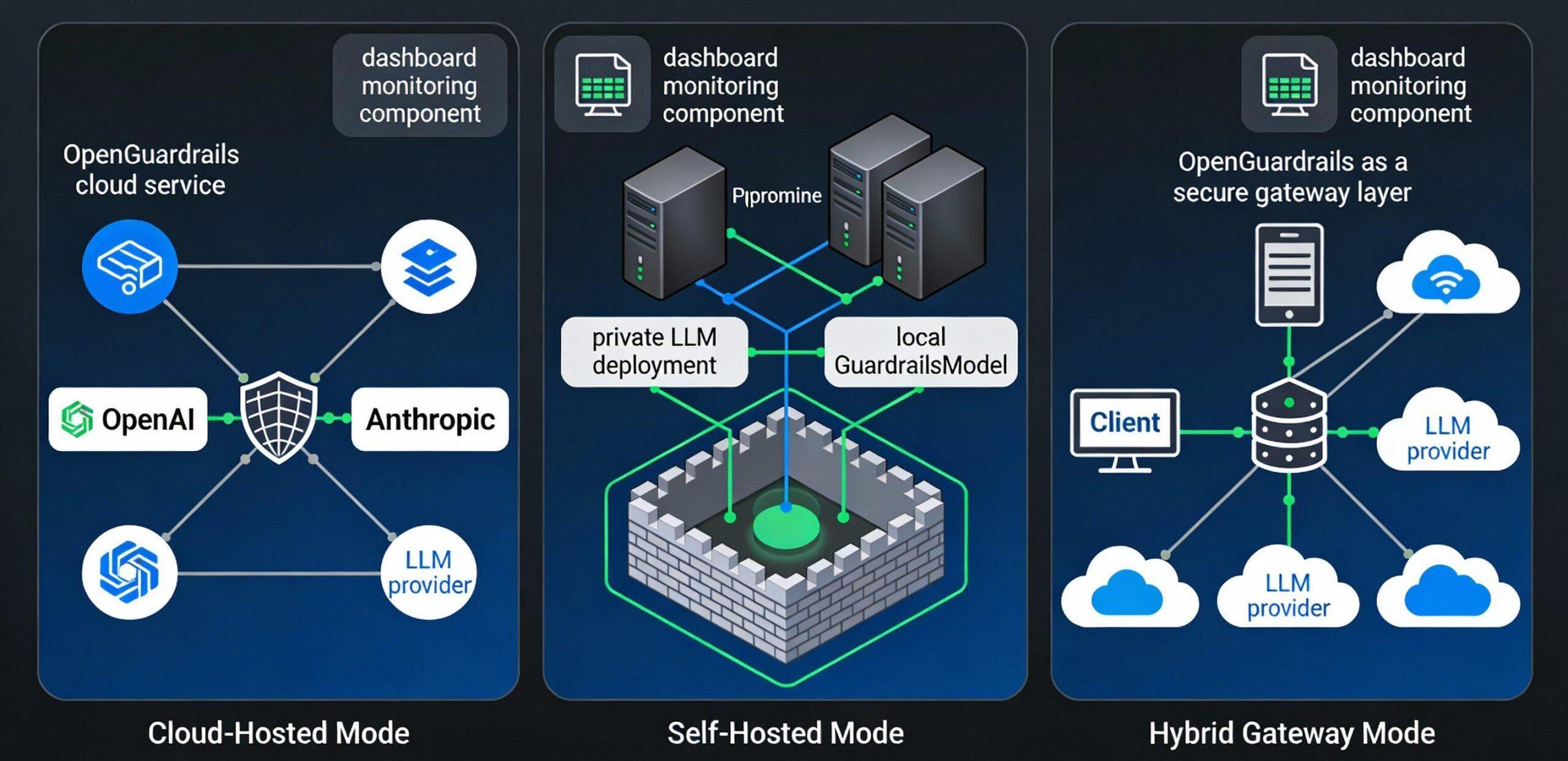
OpenGuardrails는 서로 다른 보안 및 가용성 요구 사항을 대상으로 하는 세 가지 주요 배포 모델을 지원합니다:
모델 I: 클라우드 호스팅 배포(클라우드 호스팅)
시나리오: 스타트업, 소규모 애플리케이션, 빠른 파일럿
아키텍처:
사용자 애플리케이션 → 오픈가드레일즈 클라우드 API → 오픈 소스 모델 → 의사 결정
기능:
- 현지 인프라 투자 불필요
- 즉시 사용 가능한 간단한 통합
- 자동 확장 및 고가용성
- 오픈가드레일즈 호스팅 클라우드에 데이터 업로드
실현 단계:
bash
# 1. API 키 등록 # 무료 평가판을 받으려면 https://openguardrails.com 방문하기 # 2. SDK 설치 PIP 설치 오픈가드레일 # 3. 3줄의 코드 통합 openguardrails에서 OpenGuardrails를 가져옵니다. client = OpenGuardrails(api_key="sk-...") result = client.guard.analyze(content="사용자 입력")
비용:
- 무료: 월 10,000회 요청, $0
- 프로: 월 1백만 요청, $19
- 엔터프라이즈: 무제한 요청, 맞춤형 요금제
모델 II: 프라이빗 자율 배포(자체 호스팅)
적용 가능한 시나리오: 규제 대상 산업, 데이터 주권에 대한 엄격한 요구 사항, 높은 보안 수준
아키텍처:
사용자 애플리케이션 → 로컬 OpenGuardrails 게이트웨이 → 로컬 모델 → 의사 결정 (완전 인트라넷, 데이터 유출 제로)
배포 단계:
1단계: 환경 준비
bash
# 시스템 요구 사항 # - GPU: NVIDIA A100 또는 RTX 4090(8GB+) # - CPU: 16코어 이상 # - RAM: 32GB 이상 # - 스토리지: 50GB SSD # 설치 종속성 git clone https://github.com/openguardrails/openguardrails.git cd openguardrails pip install -r requirements.txt
2단계: 모델 다운로드 및 정량화
# 기초 3.3B 정량적 모델링 다운로드 파이썬 스크립트/다운로드_모델.py \. ---model openguardrails-text-2510 \. --정량화 gptq # 모델 무결성 확인 python 스크립트/verify_model.py
3단계: 로컬 API 서비스 시작
# 로컬 데몬을 시작합니다. python -m openguardrails.server \. --host 0.0.0.0 \. --port 8000 \ ---모델 경로 . /models/openguardrails-text-2510 \. --gpu-memory-fraction 0.8 \. --concurrency 32
4단계: 통합 테스트
# 로컬 클라이언트 호출
가져오기 요청
response = requests.post(
"http://localhost:8000/v1/analyze",
json={
"content": "콘텐츠 감지 중",
"context": "응답",
"policy": {
"sensitivity": "high"
}
}
)
print(response.json())
# {
# "is_safe": true,
# "confidence": 0.95,
# "categories_detected": [],
# "latency_ms": 137
# }
네트워크 격리 예시:
# docker-compose.yml - 완전히 격리된 배포
버전: '3.8'
서비스
가드 레일: 오픈가드 레일:3.3b
이미지: openguardrails:3.3b
포트.
- "127.0.0.1:8000:8000" # 로컬 액세스 전용
환경.
- MODEL_PATH=/models/openguardrails-text-2510
- GPU_MEMORY_FRACTION=0.8
- max_batch_size=32
volumes.
- . /모델:/모델:ro
- . /logs:/var/log/guardrails
네트워크: /모델:/모델:ro .
- /var/log/guardrails
재시작: 항상
networks: 내부: /logs:/var/log/guardrails
internal.
드라이버: 브리지
비용 분석:
- 일회성 GPU 비용: $3,000-8,000
- 월 운영 비용(전력, 유지보수): $500-1,000
- 비용 절감: 클라우드 서비스 대비 트래픽이 많은 시나리오에서 연간 50~701 TP3T의 비용 절감 효과
모델 III: 하이브리드 게이트웨이 배포(하이브리드 게이트웨이)
적용 가능한 시나리오: 멀티 클라우드 환경, 트래픽 변동, 유연한 확장의 필요성
아키텍처:
사용자 애플리케이션 → OpenGuardrails 로컬 게이트웨이 →.
├ → 로컬 캐시 탐지(일반 시나리오)
├→ 클라우드 모델(고위험 시나리오)
└→ 써드파티 LLM(멀티 클라우드 지원)
구성 예시:
게이트웨이.
모드: 하이브리드
local_model.
enabled: true
모델: openguardrails-text-2510
gpu_device: 0
캐시 크기: 100000
cloud_fallback: 0
enabled: true
공급자: openguardrails_cloud
API_KEY: SK-...
OPENAI: OPENGUARDRAILS_CLOUD API_KEY: SK-...
OPENGUARDRAILS_CLOUD API_KEY: SK-...
enabled: true
API_KEY: SK-OPENAI-...
모델: [GPT-4, GPT-3.5-TURBO]
ANTHROPIC: ENABLED: TRUE API_KEY: SK-OPENAI-...
enabled: true
API_KEY: SK-ANT-...
models: [claude-3-opus]
bedrock: [claude-3-opus
enabled: true
region: US-EAST-1
모델: [claude-3, llama-2]
라우팅 정책.
기본값: 로컬 # 우선순위 로컬
fail_threshold: 3 # 페일백: 3 #
fail_threshold: 3 3회 실패 후 # 전환
6.2 POC 배포 체크리스트
1단계: 계획 및 디자인
- 요구 사항 평가: 위험 수준, 규정 준수 표준, 트래픽 예측
- 아키텍처 설계 검토
- 비용 편익 분석(자율 호스팅 대 클라우드 호스팅)
- 보안 감사 계획 개발
2단계: 인프라 준비
- GPU 서버 조달/리스
- 네트워크 격리 구성(VLAN, 방화벽 규칙)
- VPN/바스티온 설정
- 백업 및 재해 복구 프로그램
3단계: 모델 배포 및 테스트
- 모델 다운로드 및 무결성 검증
- 기능 테스트: 콘텐츠 보안, 모델 조작, 데이터 유출 탐지
- 성능 벤치마킹(지연 시간, 처리량)
- 보안 침투 테스트
- 다국어 지원 유효성 검사
4단계: 통합 및 검증
- 애플리케이션 통합(SDK/API)
- 그레이 스케일 릴리스(10% → 50% → 100%)
- 모니터링 및 알람 구성
- 사용자 피드백 수집 및 조정
5단계: 프로덕션 운영
- SLA 모니터링(가용성, 지연 시간, 정확도)
- 정기 보안 감사
- 모델 업데이트 평가
- 비용 최적화 조정
6.3 주요 성과 지표
POC 유효성 검사에서 집중해야 할 지표:
| 표준 | 목표 값 | 지침 |
|---|---|---|
| 감지 정확도(F1) | >87% | 콘텐츠 보안 + 모델 조작 점수 결합 |
| P95 지연 | <300ms | 금융/의료 애플리케이션을 위한 SLA 요구 사항 |
| 사용성 | >99.5% | 프로덕션급 신뢰성 |
| 오탐률 | <1% | 사용자 경험 주요 지표 |
| 과소 보고 비율 | <2% | 안전성 및 효과 |
| 다국어 지원 | 119개 언어 | 글로벌 애플리케이션 적용 범위 |
| 모델 업데이트 빈도 | 매월 | 적의 공격에 대한 대응 속도 |
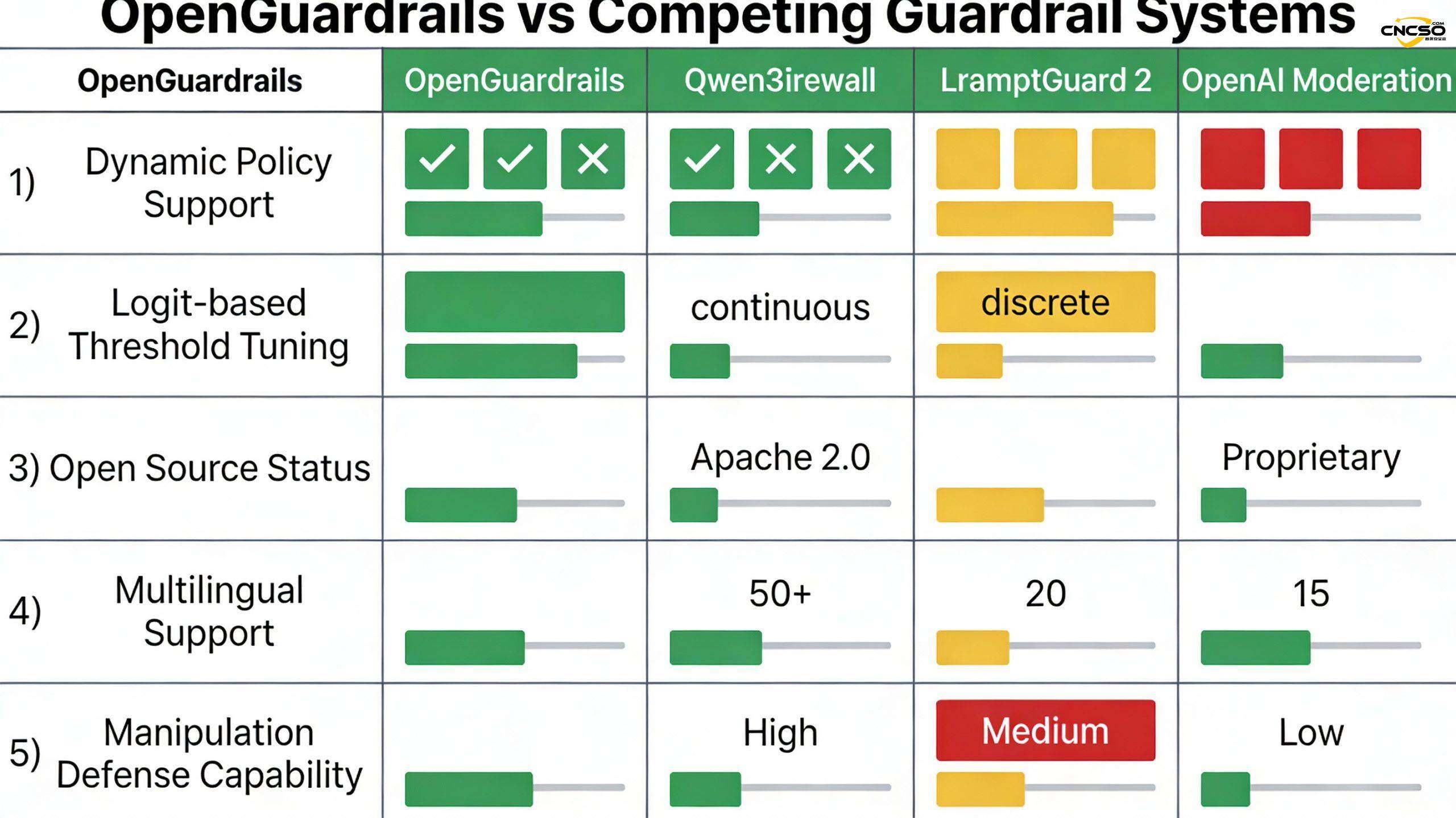
7. 오픈가드레일 오픈소스 관련 표준
7.1 라이선스 및 규정 준수
오픈 소스 라이선스: Apache 라이선스 2.0
- 상업적 사용, 수정 및 비공개 배포 허용
- 라이선스 및 저작권 고지 보유 요건
- 보증 없이 "있는 그대로" 소프트웨어 제공
규정 준수 표준 적용 범위:
- 개인정보 보호: GDPR, HIPAA, CCPA 지원
- 보안: ISO 27001 인증 진행 중
- 데이터 보호: 온프레미스 배포 지원, 데이터 업로드 필요 없음
- 감사 가능성: 완전한 의사 결정 로그 및 추적
7.2 성능 벤치마크 및 평가 기준
OpenGuardrails는 다음 벤치마크를 사용하는 업계 표준 평가 방법론을 따릅니다:
영어 평가 벤치마크:
- ToxicChat: 유해한 대화 감지
- OpenAI 중재: 공식 벤치마크
- Aegis/Aegis 2.0: 다분야 평가
- WildGuard: 실제 시나리오 데이터
중국어 평가 벤치마크(신규):
- ToxicChat_ZH: 중국어 독성 대화
- WildGuard_ZH: 중국 야생 데이터
- XSTest_ZH: 중국어 익스트림 테스트
다국어 벤치마크:
- RTP-LX: 119개 언어로 제공되는 통합 벤치마크
지표 평가:
- F1 점수(정확도 및 리콜 조정의 평균)
- 정확성
- 특이성
- 오탐률(FPR)
- 오탐률(FNR)
7.3 성능 벤치마크 결과
최신 논문 결과에 따르면(표 1-7):
영어 큐 분류 성능
OpenGuardrails-Text-2510은 영어 프롬프트 분류에서 F1 점수 87.1점을 획득하여 모든 경쟁 시스템보다 우수한 성적을 거두었습니다:
- Qwen3Guard-8B보다 우수: +3.2
- WildGuard-7B보다 우수: +3.5
- LlamaGuard 3-8B보다 우수: +10.9
영어 응답 분류 성능
F1 점수는 88.5점으로 보다 복잡한 응답 분류 작업에서 OpenGuardrails가 더 나은 성능을 보였습니다:
- Qwen3Guard-8B(엄격한)보다 우수: +8.0
- WildGuard-7B보다 우수: +11.7
- 라마가드 3-8B보다 우수: +26.3
중국어 성능
다국어 설계로 인해 중국어는 OpenGuardrails의 강세 분야입니다:
- 중국 팁: 87.4 F1 (vs Qwen3Guard 85.6)
- 중국 반응: 85.2 F1(vs Qwen3Guard 82.4)
평균 다국어 성능
OpenGuardrails는 119개 언어의 통합 벤치마크에서 97.3 F1을 달성하여 다른 시스템을 훨씬 능가합니다:
- Qwen3Guard-8B(느슨함)보다 우수: +12.4
- PolyGuard-Qwen-7B보다 우수: +16.4
7.4 모델의 정량적 품질 보증
OpenGuardrails의 GPTQ 정량화 프로세스는 품질을 보장합니다:
- 14B 오리지널 모델에서 3.3B로 정량화
- 기준 정확도 유지: >98%
- 지연 개선: 3.7배
- 메모리 사용량: 75% 감소
이는 가드레일 애플리케이션을 위한 대규모 모델 정량화의 타당성과 효과를 입증합니다.
8. 향후 개발 및 전망
8.1 기술 발전 방향
향상된 적대적 견고성
현재 오픈가드레일은 표준 벤치마크에서는 우수한 성능을 보이지만 표적 공격에는 여전히 취약할 수 있습니다. 향후 방향은 다음과 같습니다:
- 적대적 훈련 도입: 세심하게 설계된 공격 샘플로 모델의 증강 훈련
- 레드팀과의 협력: 보안 연구 커뮤니티와 협력하여 지속적으로 취약점을 발굴하고 패치합니다.
- 동적 방어 메커니즘: 모델이 새로운 공격 패턴을 식별하고 적응할 수 있습니다.
공정성 및 편향성 완화
"안전하지 않은" 콘텐츠의 정의는 문화, 지역 및 커뮤니티에 따라 다르며 OpenGuardrails에서 요구합니다:
- 다문화 적응: 지역별 미세 조정 모델
- 편향성 감사: 모델링에서 사회적 편향성을 체계적으로 평가하고 제거하기
- 해석 가능성 향상: 사용자가 의사 결정의 이유를 이해하고 피드백 및 조정을 용이하게 합니다.
엔드포인트 디바이스 배포
현재 3.3B 모델은 여전히 비교적 큰 규모입니다. 향후 방향은 다음과 같습니다:
- 모바일 및 IoT 디바이스를 위한 초경량 버전(500M 매개변수 미만)
- 지식 증류: 모델 3.3B의 기능을 더 작은 모델로 압축하기
- 연합 학습: 클라우드 통신 없이 사용자 디바이스에서 로컬 탐지
멀티모달 확장
현재 OpenGuardrails는 주로 텍스트를 다루고 있습니다. 향후 계획은 다음과 같습니다:
- 이미지 콘텐츠 보안 탐지(폭력적, 음란물, 혐오 이미지 식별)
- 비디오 프레임 감지(실시간 스트림 처리)
- 오디오/음성 감지(혐오 발언, 괴롭힘 식별)
- 교차 모달 분석: 텍스트, 이미지, 오디오의 공동 의미 이해
8.2 생태학 및 통합
(강의) 본류AI 프레임워크집적(집적 회로에서와 같이)
OpenGuardrails는 메인스트림 프레임워크와의 통합을 강화할 계획입니다:
- LangChain: 지원, 체인 레벨 펜싱 강화 계획
- LangGraph: 멀티 에이전트 시스템의 안전한 조정
- CrewAI: 멀티 에이전트 팀의 중앙 집중식 관리
- 앤트로픽 클로드 통합: 공식 API 레벨 통합
- LlamaIndex: 검색 증강 생성(RAG)을 위한 보안 울타리
수직 산업 맞춤형 모델
기존 기본 모델을 기반으로 산업별로 최적화된 버전이 계획되어 있습니다:
- 재무 모델링: 사기 탐지, 규정 준수 검토 최적화
- 의료 모델링: 부적절한 의료 조언을 식별하는 전문 분야
- 법적 모델: 권한이 있는 통신, 기밀 정보 식별
- 교육 모델링: 학업 부정행위, 부적절한 교육 콘텐츠 식별
엔터프라이즈 도구 체인 통합
엔터프라이즈 관리 및 거버넌스 도구와 통합:
- Datadog: LLM 통합 가시성 및 모니터링
- Splunk: 보안 이벤트 로그 집계
- Tableau/PowerBI: 가드레일 성능 대시보드
- Jira/ServiceNow: 자동화된 화학물질 주문 관리
8.3 시장 및 비즈니스 전망
기업 도입 동향
제너레이티브 AI가 기업에서 널리 사용됨에 따라 가드레일 시스템에 대한 수요는 급격히 증가할 것입니다. 예측:
- 2025년: 50% 생산 등급 LLM 애플리케이션이 가드레일 시스템을 통합합니다.
- 2026년: 가드레일 시스템이 AI 애플리케이션의 표준 인프라가 될 것입니다.
- 2027년: 가드레일 시장 규모 20억 달러 달성
오픈가드레일의 장점
OpenGuardrails는 다른 솔루션에 비해 고유한 장점을 제공합니다:
- 완전한 오픈 소스: 엔터프라이즈 도입 위험 감소 및 벤더 종속성 방지
- 통합 아키텍처: 간편한 배포 및 유지 관리, 낮은 총소유비용
- 유연한 구성: 다양한 비즈니스 요구 사항 충족
- 다국어 지원: 글로벌화된 비즈니스를 위한 지원
- 엔터프라이즈 인프라: 프로덕션 지원, SLA 보장
8.4 오픈 소스 커뮤니티 구축
학술 협력
오픈가드레일은 학계에서 많은 관심을 받고 있습니다. 향후 협업 방향
- 유수 대학(MIT, CMU, 칭화대, 홍콩대 등)과의 공동 연구실 설립
- SOTA 연구 논문 게재: arXiv에 게재, ACL/EMNLP에 제출 예정
- 오픈 소스 보안 연구 자금 지원: 연간 보안 연구 기금 프로그램
커뮤니티 중심
오픈가드레일의 장기적인 성공은 활발한 오픈 소스 커뮤니티에 달려 있습니다:
- GitHub 별 수 목표: 12개월 내 10,000개 이상
- 목표 기여자 수: 1년차 50명 이상, 2년차 200명 이상
- 중국어 커뮤니티 구축: 중국어 문서 지원, 중국어 토론 포럼, 중국어 튜토리얼
표준화 및 업계 지침
가드레일 시스템의 업계 표준화를 촉진합니다:
- NIST, IEEE 및 기타 표준 기관과 협력하여 LLM 안전 가드레일 표준 개발
- 백서 및 모범 사례 가이드 게시
- 업계 인증 시스템 구축(LLM 안전 엔지니어 자격증)
8.5 장기 비전
비전 선언문:
"오픈가드레일은 세계 최고의 오픈소스가 되기 위해 최선을 다하고 있습니다.AI 보안모든 개발자와 조직이 안전하고 책임감 있게 대규모 모델을 배포할 수 있는 인프라를 통해 실험 단계에서 성숙한 생산 단계로 AI의 진화를 촉진할 수 있습니다."
구체적인 목표:
- 글로벌 채택: 50% 이상의 포춘 500대 기업에서 OpenGuardrails 사용
- 안전 표준화: 국제 LLM 안전 가드레일 표준 개발 및 시행
- 기술 혁신: 개인 정보를 보호하는 차세대 멀티모달 펜싱 기술 추진
- 인재 개발: 확립AI 보안연간 5000명 이상의 전문가를 양성하는 인재 양성 시스템
- 사회적 영향: 오픈 소스 및 교육을 통해 AI 보안을 글로벌 공공재로 만들기
9. 문헌 참고 자료
Wang, T., & Li, H. (2025). OpenGuardrails: 대규모 언어 모델을 위한 구성 가능하고 통합적이며 확장 가능한 가드레일 플랫폼. arXiv 프리프린트 arXiv:2510.19169.
오픈가드레일 공식 웹사이트. 검색된 위치 https://openguardrails.com
오픈가드레일 깃허브 리포지토리에서 가져옴. https://github.com/openguardrails/openguardrails
OpenGuardrails 문서. 검색된 위치 https://openguardrails.com/docs
Qwen3Guard: Qwen3 모델을 위한 종합 안전 가드. 검색된 위치 https://github.com/QwenLM/Qwen3Guard
LlamaFirewall: 프롬프트 인젝션과 탈옥으로부터 LLM을 보호하는 방법.
WildGuard: 오픈 소스 LLM 안전 벤치마크. GitHub에서 가져옴.
NemoGuard: NVIDIA의 가드레일 프레임워크. 검색된 위치 https://github.com/NVIDIA/NeMo-Guardrails
헬프넷시큐리티. (2025). "OpenGuardrails : AI를 더 안전하게 만드는 것을 목표로하는 새로운 오픈 소스 모델". 에서 검색 https://www.helpnetsecurity.com/
팔로 알토 네트웍스 유닛 42. (2025). "GenAI 플랫폼 간 LLM 가드 레일 비교". 에서 검색 https://unit42.paloaltonetworks.com/
부록: 용어집
| 명명법 | 영어(언어) | 정의 |
|---|---|---|
| 가드레일 시스템 | 가드레일 | LLM 입력 및 출력 모니터링 및 제어를 위한 AI 보안 프레임워크 |
| 큐 단어 삽입 | 프롬프트 주입 | 모델 동작을 변경하기 위해 입력에 악성 명령어 삽입하기 |
| 탈옥(iOS 기기 등) | 탈옥 | 트릭을 통해 모델의 안전 정렬 제약 조건 우회하기 |
| 개인 식별 정보 | PII | 개인에 대한 민감한 정보를 인식하는 기능 |
| 감도 임계값 | 감도 임계값(τ) | 안전 테스트의 엄격함을 조정하기 위한 매개변수 |
| 정량화 가능 | 정량화 | 모델 파라미터의 정확도 감소로 계산 비용 절감 |
| F1 점수 | F1 점수 | 정확도 및 회수율의 조화 평균 |
| 오탐률 | 오탐률 | 안전하지 않은 것으로 잘못 표시된 보안 콘텐츠의 비율 |
| 과소 보고 비율 | 오탐률 | 탐지되지 않은 안전하지 않은 콘텐츠의 비율 |
| 감사 가능성 | 감사 가능성 | 체계적인 의사 결정 프로세스를 문서화하고 추적할 수 있는 기능 |
xbear의 원본 글, 복제 시 출처 표시: https://www.cncso.com/kr/openguardrails-open-source-framework-technical-architecture.html






