
I. Введение:Безопасность ИИСрочность угрозы и системное мышление
С широким распространением больших языковых моделей (LLM) и генеративного искусственного интеллектаИИСистема стала вопросом непрерывности бизнеса,Безопасность данныхи критической инфраструктуры для обеспечения конфиденциальности пользователей. Однако, в отличие от традиционной кибербезопасности, угрозы для систем ИИ имеют уникальные характеристики: атаки могут происходить на протяжении всего жизненного цикла сбора данных, обучения модели, тонкой настройки и оптимизации, развертывания выводов и мониторинга эксплуатации и обслуживания. Системы ИИ сталкиваются с беспрецедентными проблемами безопасности: от вредоносного отравления данных для ухудшения способности модели к суждению, до тщательно разработанных образцов противника, вводящих систему в заблуждение, и скрытого введения слов-подсказок для обхода защиты.
Матрица рисков угроз безопасности ИИ, выпущенная совместно Tencent AI Lab, Tencent Jubilee Lab и Китайским университетом Гонконга (Шэньчжэнь), впервые систематически сортирует самые передовые результаты исследований в области безопасности ИИ с точки зрения всего жизненного цикла. В качестве теоретической основы матрица опирается на зрелую систему ATT&CK, а также раскрывает процесс атаки и технические средства реализации, с которыми могут столкнуться системы ИИ с точки зрения противника, чтобы предприятия могли быстро найти точки риска, оценить уровень угрозы и развернуть защитные меры. В этой статье мы обсудимМатрица угроз безопасности искусственного интеллектав котором систематически анализируются основные векторы атак и приводятся передовые методы защиты предприятий в различных аспектах.
II. Матрица угроз безопасности ИИ: основные принципы и система классификации
2.1 Применение методологии ATT&CK к областям ИИ
Система ATT&CK (Adversarial Tactics, Techniques & Common Knowledge) является относительно зрелой в области кибербезопасности и способна систематически описывать поведение при атаках с точки зрения противника. Матрица угроз безопасности ИИ как раз и является применением этой проверенной методологии к области ИИ, создавая практическое руководство. Матрица угроз безопасности ИИ применяет эту проверенную методологию к области ИИ и создает техническую основу с практическим руководством.
Уникальность матрицы AI Security Matrix по сравнению с традиционными моделями угроз кибербезопасности заключается в следующем:
- Полный жизненный цикл: матрица охватывает все аспекты системы искусственного интеллекта - от создания среды, сбора данных, обучения модели, тонкой настройки и оптимизации, выводов по развертыванию до технического обслуживания и эксплуатации.
- Иерархия зрелости: методы атак делятся на три уровня зрелости - зрелые угрозы (реально произошедшие атаки), изучаемые угрозы (подтвержденные академическими исследованиями, но еще не получившие широкого распространения) и потенциальные угрозы (теоретически возможные, но еще не встречающиеся на практике).
- Разработка перспективы противника: прямое представление того, как злоумышленник шаг за шагом преодолевает систему искусственного интеллекта, чтобы помочь защитнику понять логическую цепочку атаки.
- Практическое руководство: помимо описания угроз, матрица содержит целевые рекомендации по защите и варианты смягчения последствий.
2.2 Основные классификации угроз безопасности ИИ

Матрица угроз безопасности ИИ классифицирует угрозы для систем ИИ по девяти основным направлениям, каждое из которых содержит множество специфических векторов атак:
| Категория угрозы | Основные характеристики | Основные параметры воздействия |
|---|---|---|
| Отравление данных/введение в заблуждение (Отравление) | Внедрение вредоносных образцов в данные для обучения или тонкой настройки | Целостность, надежность |
| Состязание | Рассуждения с помощью моделей рассогласования тонких возмущений | Целостность, надежность |
| Конфиденциальность | Извлечение обучающих данных или вывод конфиденциальной информации | Конфиденциальность, частная жизнь |
| Внесение слов подсказки (Быстрое введение) | Создание вредоносных команд для обхода защиты | Целостность, доступность |
| Добыча/похищение моделей (IP-угроза) | Получение структуры и параметров модели путем запроса | Интеллектуальная собственность, конфиденциальность |
| Неправильное использование | Использование систем искусственного интеллекта во вредных целях | Соответствие нормам, репутация |
| Атака на цепь поставок | Загрязнение зависимых моделей, данных или компонентов | Целостность, доступность |
| Предрассудки и дискриминация (предубеждения) | Модель изучает смещение в обучающих данных | Справедливость, репутация, юридический риск |
| Ненадежный выход | Иллюзия модели, дрейф или неточные результаты | Надежность, репутация |
III. Цепочка атак ИИ: полный процесс от разведки до исполнения
Матрица угроз безопасности ИИ использует цепочку атак в качестве основной организационной структуры, четко представляя, как злоумышленники шаг за шагом преодолевают защиту систем ИИ. Этот процесс похож на модель цепочки атак в традиционной кибербезопасности, но специально разработан с учетом уникальных характеристик систем ИИ.
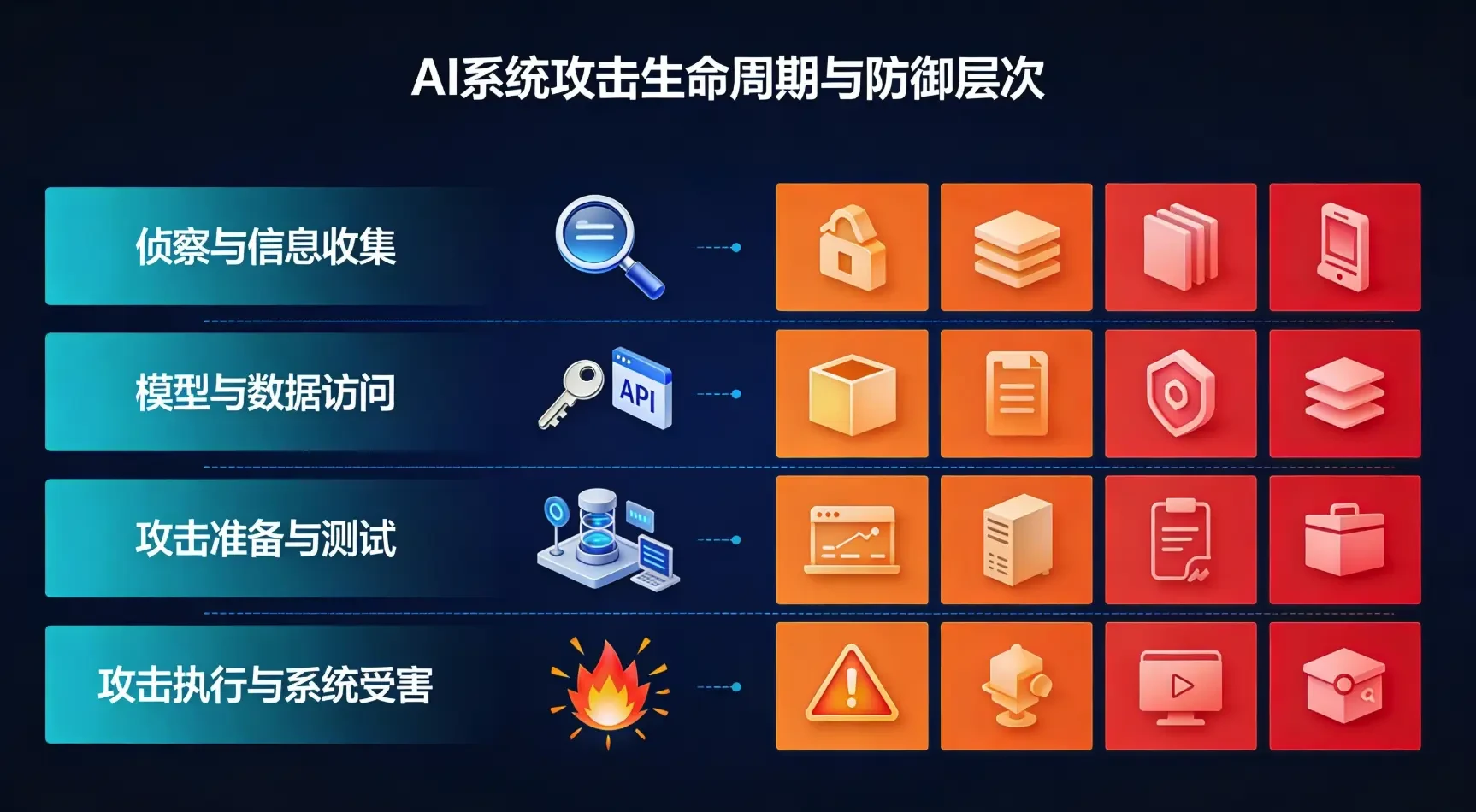
3.1 Этап I: разведка и сбор информации (рекогносцировка)
Характеристики этапа: злоумышленник пытается понять общую ситуацию с целевой системой ИИ, включая среду развертывания, тип используемых моделей, API-интерфейсы и характеристики обучающих данных.
Конкретные технические средства:
- Сбор публичной информации: технические подробности целевой модели можно получить из научных статей, технических документов, презентаций на конференциях, репозиториев GitHub, карточек моделей и других каналов.
- API-зондирование: анализ входных и выходных характеристик модели и вывод о внутренней архитектуре путем вызова API-сервиса ИИ. Например, злоумышленник может отправлять различные типы запросов и записывать шаблоны ответов модели, чтобы вывести логику ее классификации.
- Идентификация среды: определение того, на какой облачной платформе развернута система ИИ, какие фреймворки с открытым исходным кодом или коммерческие модели используются, а также какие методы передачи данных применяются.
Оборонная стратегия:
- Ограничить степень обнародования документации по модели, чтобы избежать чрезмерного разглашения технических деталей
- Реализация ограничений частоты запросов к API и обнаружение аномального поведения
- Следите за проектами с открытым исходным кодом и обсуждениями в социальных сетях, связанными с моделью
3.2 Этап 2: Моделирование и доступ к данным (Доступ к модели)
Характеристика фазы: злоумышленник получает прямой или косвенный доступ к целевой системе ИИ для подготовки к последующим глубоким атакам.
Конкретные технические средства:
- Доступ с черного ящика: запрос модели через API и наблюдение за выходной информацией, такой как доверительные оценки и распределения вероятностей. Этот тип запросов не требует больших затрат, но предоставляет ограниченный объем информации, однако злоумышленник может постепенно вывести свойства модели с помощью статистических методов.
- Доступ к "серому ящику": получение частичной информации о модели (например, выходов среднего слоя, информации о градиенте), что позволяет разрабатывать более точные атаки.
- Доступ из белого ящика: полный доступ к структуре и параметрам модели, который обычно возникает после инсайдерской утечки или взлома модели.
Оборонная стратегия:
- Обеспечьте строгий контроль доступа и аутентификацию
- Ограничить детализацию информации, возвращаемой API (например, не возвращать конкретные значения вероятности, а только результаты классификации).
- Развертывание ограничений частоты запросов и обнаружение аномалий
- Использование методов повышения конфиденциальности (таких какдифференцированная конфиденциальность) Нечеткая выходная информация
3.3 Фаза 3: Подготовка и тестирование атаки (постановка атаки)
Характеристика фазы: злоумышленники разрабатывают и тестируют методы атаки в самостоятельно созданной среде, проверяют их эффективность, а затем дорабатывают их на основе информации, полученной на этапах разведки и доступа.
Конкретные технические средства:
- Генерация неблагоприятных образцов: использование собственных данных и модели для создания входных образцов, которые могут ввести целевую модель в заблуждение. Например, добавление в изображение шума, незаметного для человеческого глаза, приводит к тому, что целевой классификатор распознает собаку как кошку.
- Создание образцов, отравляющих данные: разработка вредоносных обучающих образцов, способных повлиять на оценку целевой модели в процессе ее обучения, например, атаки с подменой меток или внедрение скрытого бэкдора.
- Разработка шаблонов для атак по подсказке слова: разработка различных типов шаблонов для атак по подсказке слова и инъекций при побеге из тюрьмы с использованием возможностей LLM. Эти шаблоны могут использовать различные техники, включая отказ в подавлении, ролевые игры, семантическую обфускацию и т.д.
Оборонная стратегия:
- Проведите тестирование на устойчивость к неблагоприятным воздействиям, чтобы заранее выявить и устранить уязвимости модели.
- Создание полной системы дистилляции и состязательной подготовки модели защиты
- Внедрите строгие механизмы проверки и очистки входных данных
3.4 Этап 4: Выполнение атаки и виктимизация системы (Выполнение)
Характеристика фазы: злоумышленник осуществляет хорошо продуманную атаку на реальную целевую систему, пытаясь достичь заранее поставленной цели. В зависимости от цели атаки этот этап включает в себя различные техники:
3.4.1 Атаки на отравление данных (Data Poisoning)
Принцип: злоумышленник внедряет вредоносные образцы в обучающие данные модели или данные тонкой настройки, в результате чего модель обучается неправильным связям.
Специфические типы:
- Атаки с переворачиванием меток: изменение меток нормальных образцов, например, маркировка "легитимных писем" как "спама". Было показано, что загрязнение всего 0,0011 TP3T данных может привести к существенному сбою модели.
- Атака скрытых меток: вместо того чтобы менять метки образцов, модель заставляют выдавать результаты, указанные злоумышленником, при определенных условиях, вставляя тонкие триггеры признаков. Эту атаку гораздо сложнее обнаружить.
- Отравление скрытых признаков: вставка в обучающие данные ложных признаков, которые сильно коррелируют с определенной категорией, например, добавление визуальных элементов, связанных с "взрывом", к обучающему изображению "цветка" приводит к тому, что модель ассоциирует "цветок" с "опасностью". Это заставляет модель ассоциировать "цветок" с "опасностью".
Защитные механизмы:
- Очистка и проверка данных: обнаружение выбросов и статистический анализ обучающих данных для выявления и удаления образцов, подозреваемых в отравлении.
- Надежное обучение: с помощью таких методов, как обучение по принципу состязательности, модели учатся быть устойчивыми к загрязненным данным.
- Разнообразие данных: сбор данных для обучения из нескольких надежных источников снижает риск того, что один источник данных будет полностью контролироваться.
- Дифференциальная конфиденциальность: во время обучения добавляется шум, чтобы ограничить влияние отдельных образцов на модель.
3.4.2 Адверсивные образцы и адверсивные атаки (адверсивные примеры)
Принцип: злоумышленник заставляет модель делать ложные прогнозы, внося в исходные данные сложные возмущения, которые практически незаметны для человека.
Типичный случай:
- Атаки на классификацию изображений: добавление тщательно рассчитанного шума к фотографиям, чтобы заставить системы автопилотирования неверно определять дорожные знаки.
- Атаки на распознавание речи: встраивание в аудио частот, незаметных для человеческого слуха, что заставляет голосовые помощники выполнять непредусмотренные команды.
Защитные механизмы:
- Защитная дистилляция: обучение модели ученика с помощью более надежной модели учителя снижает чувствительность модели к неблагоприятным выборкам.
- Методы регуляризации: использование ограничений, таких как регуляризация L1/L2, для предотвращения чрезмерной подгонки модели под конкретные входные шаблоны.
- Обнаружение аномалий: развертывание детекторов аномальных образцов для выявления и отбраковки входных данных, предположительно являющихся антагонистическими образцами в процессе вывода.
- Преобразование и реконструкция входных данных: денуаризация входных данных до того, как они попадут в модель, например, сжатие JPEG, гауссова фильтрация и т.д.
3.4.3 Атаки на утечку конфиденциальной информации и вывод членства (Privacy Leakage & Membership Inference)
Сценарии угроз:
- Извлечение обучающих данных: злоумышленник постепенно восстанавливает реальные данные, использованные при обучении модели, путем многократных запросов к ней. Например, можно восстановить медицинские карты или финансовые данные, содержащие личную информацию пользователей.
- Атака с инверсией модели (MIA): злоумышленник анализирует выходные данные модели, чтобы определить, какие характеристики обучающих данных соответствуют определенному входному сигналу. По модели распознавания лиц злоумышленник может восстановить исходное изображение лица на основе достоверного вывода модели.
- Атака на основе членства (Membership Inference Attack, MIA): злоумышленник использует поведенческие характеристики модели, чтобы определить, использовалась ли конкретная точка данных для обучения. Это представляет собой серьезную угрозу для защиты конфиденциальности, особенно в таких чувствительных областях, как здравоохранение и финансы.
Защитные механизмы:
- Дифференциальное обучение конфиденциальности: добавление тщательно продуманного шума к градиенту или данным гарантирует, что удаление отдельных образцов не приведет к существенному изменению поведения модели.
- Классификация и минимизация данных: маркировка конфиденциальных данных и ограничение их использования в обучении модели.
- Федеративное обучение: децентрализованное обучение моделей на нескольких пограничных устройствах, что делает все данные обучения недоступными для центральной системы.
- Обнаружение умозаключений: создание конвейера для выявления рисков нарушения конфиденциальности в тексте, сгенерированном моделью.
3.4.4 Атаки с внедрением и побегом из тюрьмы (Prompt Injection & Jailbreak)
Принцип: Злоумышленники пытаются обойти средства защиты LLM, тщательно конструируя подсказки, побуждающие модель генерировать контент, который является вредным, оскорбительным или превышает ожидания.
Специфические атаки:
- Прямое введение слов-подсказок:
- Злоумышленники добавляют специальные символы, странные суффиксы или бессмысленные символы, чтобы запутать механизмы фильтрации безопасности модели.
- Торможение отторжения: побуждение модели игнорировать правило безопасности "Я не могу этого сделать" с помощью обратной психологии или косвенного представления.
- Ролевая игра: погружая модель в вымышленный сюжетный сценарий, легче направить ее в неправильное русло.
- Косвенное введение слов-подсказок:
- Отравление веб-данных: домены, срок действия которых истек и которые фигурировали в обучающих данных модели, покупаются, наполняются вредоносным содержимым и заражаются, когда модель их получает.
- Скрытая инъекция инструкций: встраивание специальных инструкций в безобидные на первый взгляд изображения, аудио или PDF-файлы, которые активируются, когда модель обрабатывает мультимодальные входные данные.
- Состязательная система побуждает к утечкам:
- Злоумышленник подделывает сообщения, которые кажутся исходящими от системы, и побуждает модель выводить свои скрытые слова подсказки системы, чтобы узнать об ограничениях модели.
Защитные механизмы:
- Фильтрация и очистка входных данных: предопределенные черные списки и правила, однако следует признать, что правилам сложно охватить все сложные семантические атаки.
- Обнаружение аномалий на основе моделей: использование моделей обнаружения для выявления вредоносных слов-ключей является более гибким, чем методы составления черных списков.
- Распознавание намерений: добавлен специальный модуль распознавания намерений для определения того, пытается ли пользователь выполнить отмену.
- Тренировка в условиях противоборства: добавьте в обучающие данные образцы "кий-инъекция-правильный-ответ", чтобы повысить устойчивость модели.
- Многомодельная перекрестная валидация: параллельно обрабатывайте один и тот же входной сигнал несколькими LLM и сравнивайте согласованность результатов.
- Обнаружение совпадения выходных данных: выходные данные модели проверяются на совпадение с исходным заданием, и ответы, отклоняющиеся от ожидаемых, отклоняются.
3.4.5 Извлечение модели и кража знаний (извлечение модели)
Принцип: злоумышленник крадет интеллектуальную собственность модели, копируя или выводя структуру, параметры или поведение целевой модели путем обширных запросов и обратного проектирования.
Специфические техники:
- Репликация модели "черного ящика": обучение альтернативной модели для имитации поведения целевой модели с помощью статистического шаблона вызова API.
- Градиентная инверсия: использование информации о выходном градиенте модели для пошагового определения параметров модели.
Защитные механизмы:
- Водяной знак модели: встраивание скрытых водяных знаков в параметры модели с целью проверки права собственности на модель и обнаружения украденных копий.
- Контроль запросов: ограничение частоты запросов к API, обнаружение и отклонение аномальных шаблонов запросов.
- Обескураживание вывода: уменьшение детализации информации, возвращаемой API, например, возвращение только окончательных результатов классификации, а не уровня доверия.
IV. Цепочки поставок и экологическая безопасность: новый тип угроз для систем ИИ
По мере бурного развития экосистемы внедрения ИИ безопасность цепочек поставок становится новым аспектом, который нельзя игнорировать. Предприятия редко создают системы ИИ с нуля, вместо этого они быстро развертывают их, интегрируя предварительно обученные модели, фреймворки с открытым исходным кодом, сторонние API и облачные вычислительные сервисы. Такая сложная система цепочки поставок создает беспрецедентные риски:
4.1 Моделирование рисков цепочки поставок
- Загрязнение предварительно обученных моделей: модели с открытым исходным кодом или веса моделей из ненадежных источников могут быть отравлены или снабжены бэкдорами.
- Уязвимость зависимостей: используемый фреймворк глубокого обучения или пакеты зависимостей могут иметь известные уязвимости или уязвимости нулевого дня, которые могут быть использованы злоумышленником.
- Риск данных для тонкой настройки: при тонкой настройке на основе предварительно обученной модели, если данные для тонкой настройки загрязнены, вся модель может быть испорчена.
4.2 Стратегии защиты цепи поставок
- Оценка и сертификация поставщиков: проведение аудита безопасности всех сторонних поставщиков на предмет соответствия стандартам безопасности компании.
- Управление спецификацией материалов (SBOM): ведение подробной спецификации материалов программного обеспечения, отслеживание источников и версий моделей, фреймворков и пакетов зависимостей.
- Подпись и верификация моделей: цифровая подпись всех развернутых моделей для предотвращения фальсификации.
- Постоянный мониторинг и сканирование уязвимостей: сканирование уязвимостей и оценка безопасности всех компонентов системы искусственного интеллекта на регулярной основе.
V. Многоуровневая система защиты для обеспечения безопасности корпоративного ИИ
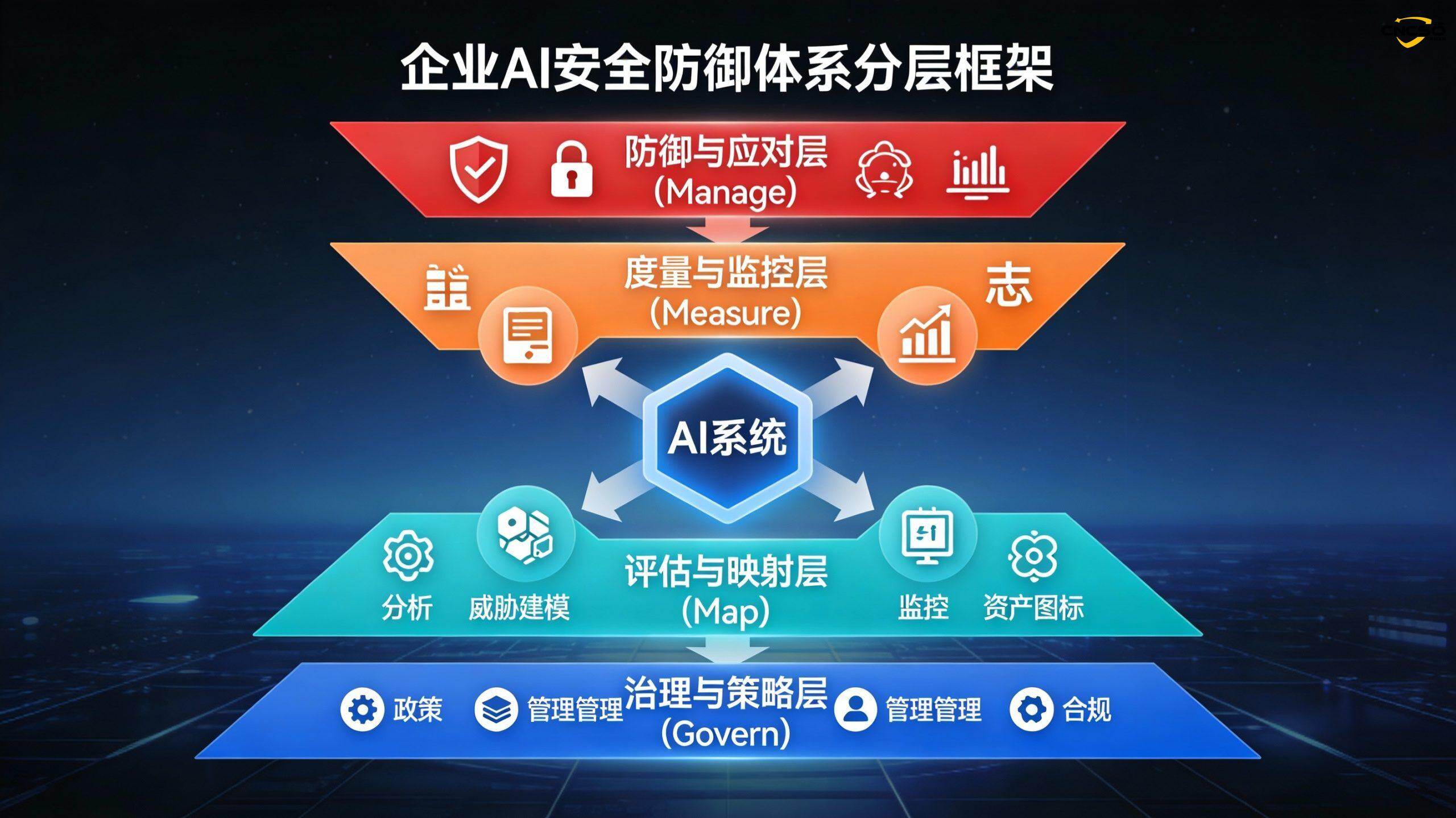
5.1 Уровень 1: Уровень управления и стратегии (Govern)
Цель: создать культуру и рамки безопасности ИИ на уровне организации, чтобы обеспечить серьезное отношение к безопасности ИИ сверху донизу.
Критические средства контроля:
- Разработка политики безопасности ИИ: уточнение понимания организациямиБезопасность системы искусственного интеллектадолжности, требования и стандарты.
- Процесс управления рисками: создание стандартизированного процесса для выявления, оценки и устранения рисков безопасности ИИ, а также обеспечение того, чтобы все новые приложения ИИ подвергались анализу рисков.
- Роли и обязанности: определите ответственных за безопасность ИИ в организации, включая владельцев данных, разработчиков моделей, инженеров по безопасности и т. д.
- Требования к соответствию: разработка соответствующей системы соответствия в соответствии с нормативными требованиями (например, GDPR, AI Act и т. д.), в частности, требованиями к защите конфиденциальности и справедливости.
5.2 Слой 2: Слой оценки и картирования (карта)
Цель: всестороннее выявление потенциальных точек риска в системе искусственного интеллекта и создание основы для последующих мер защиты.
Основные виды деятельности:
- Инвентаризация активов: перечислите все модели ИИ, наборы данных, приложения и инфраструктуру в организации, классифицируйте и обозначьте их.
- Моделирование угроз: систематическое определение возможных сценариев атак с помощью методов моделирования угроз (например, STRIDE и т. д.).
- Анализ потоков данных: отследите, как данные проходят через всю систему искусственного интеллекта, и определите точки риска, связанные с воздействием на данные. Например, где хранятся конфиденциальные данные пользователей и где к ним осуществляется доступ на разных этапах.
- Анализ зависимостей: отображение зависимостей между моделями, выявление критических путей и единых точек отказа.
5.3 Уровень 3: Уровень измерения и мониторинга (измерение)
Цель: постоянно оценивать состояние безопасности систем ИИ с помощью количественных показателей и механизмов мониторинга.
Ключевые показатели и механизмы:
- Базовый уровень производительности модели: устанавливает базовый уровень производительности (точность, задержка, пропускная способность и т. д.) во время нормальной работы и обнаруживает аномалии, которые могут указывать на атаки или дрейф модели.
- Журнал аудита безопасности: полная запись всех входов и выходов модели, изменений конфигурации, изменений привилегий доступа и т. д. для расследования событий и судебной экспертизы.
- Оценка устойчивости к атакам: модель периодически тестируется на образцах, чтобы оценить ее устойчивость к атакам.
- Оценка конфиденциальности: использование таких методов, как атаки на вывод членства, для оценки того, не слишком ли модели запоминают обучающие данные.
- Обнаружение поведенческих аномалий: мониторинг выходного поведения модели в режиме реального времени, выявление значительных отклонений от исторических моделей, которые могут свидетельствовать об успешной атаке.
5.4 Уровень 4: Уровень защиты и реагирования (управление)
Цель: Реализация конкретных мер технического контроля для снижения вероятности и воздействия рисков.
Конкретные меры:
Защита на уровне данных
- Классификация и маркировка данных: классифицируйте данные в зависимости от их чувствительности и применяйте более строгую защиту для особо чувствительных данных.
- Контроль доступа: соблюдение принципа наименьших привилегий, ограничение доступа к данным и управление разрешениями на основе идентификации, роли и контекста.
- Шифрование данных: для предотвращения перехвата или утечки данных при передаче и хранении используется надежное шифрование.
- Десенсибилизация и анонимизация данных: удаление или шифрование конфиденциальной личной информации при обучении или представлении данных.
Защита модельного уровня
- Обучение с использованием состязательных примеров: состязательные примеры добавляются в процессе обучения для повышения устойчивости модели.
- Регуляризация и защитная дистилляция: использование методов регуляризации для уменьшения избыточной подгонки и дистилляции для сжатия модели и повышения ее устойчивости.
- Дифференциальная конфиденциальность: добавляет шум в обновление градиента, ограничивая влияние отдельных образцов на модель.
- Проверка и тестирование модели: комплексное тестирование безопасности перед развертыванием, включая тестирование на образцах противника, оценку конфиденциальности и т. д.
- Подпись модели и обнаружение целостности: используйте цифровые подписи, чтобы убедиться, что модель не была подделана, и хэш-проверки для обнаружения аномалий в режиме реального времени.
защита на уровне приложений
- Проверка и очистка ввода: строгая проверка и очистка всех вводимых пользователем данных, отсеивание вредоносных и необычных вводов.
- Фильтрация выходных данных: проверка содержимого выполняется для отсеивания выходных данных, содержащих вредную, незаконную или конфиденциальную информацию, до того, как выходные данные модели будут показаны пользователям.
- Ограничение скорости и контроль запросов: ограничьте частоту и количество запросов для одного пользователя или IP-адреса, чтобы предотвратить злоупотребления.
- Управление источниками данных для систем RAG: если используется система Retrieval Augmentation Generation (RAG), внешние источники данных строго контролируются и проверяются, чтобы предотвратить внедрение вредоносного контента.
Защита тканевого слоя
- Обучение сотрудников мерам безопасности: повышение осведомленности технических специалистов об угрозах безопасности ИИ и обучение безопасным методам разработки.
- План реагирования на инциденты: разработайте четкий процесс реагирования на инциденты, включая обнаружение, изоляцию, расследование и восстановление.
- Управление поставщиками: регулярно проверяйте методы обеспечения безопасности сторонних поставщиков, чтобы убедиться в том, что они соответствуют стандартам компании.
- Сторонние оценки: внешние организации по безопасности приглашаются для проведения независимых тестов на проникновение и аудита безопасности.
VI. Стандартизация рамок безопасности ИИ: ISO/IEC 42001 и NIST AI RMF
6.1 ISO/IEC 42001: Стандарт системы управления искусственным интеллектом
ISO/IEC 42001 - это первый международный стандарт на системы менеджмента ИИ, который предоставляет организациям структурированное руководство по созданию и поддержанию системы менеджмента ИИ. Его основные характеристики включают:
- Широкая сфера применения: охватывает весь жизненный цикл системы искусственного интеллекта, от планирования до эксплуатации и технического обслуживания.
- 39 элементов управления: охватывают широкий спектр аспектов, таких как управление ИИ, управление рисками, защита данных и прозрачность.
- Сертификационный аудит: поддержка аудита и сертификации третьей стороной, чтобы помочь организациям подтвердить своиПрактика обеспечения безопасности искусственного интеллекта.
6.2 NIST AI Risk Management Framework (NIST AI RMF)
NIST AI RMF - это добровольная система, опубликованная Национальным институтом стандартов и технологий, которая посвящена управлению рисками ИИ и содержит четыре основные функции:
- Управление: создание культуры осознания рисков и определение политики и процессов управления рисками
- Карта: выявление потенциальных рисков в системах искусственного интеллекта
- Измерение: оценка вероятности и влияния идентифицированных рисков
- Управление: реализация мер по снижению рисков
6.3 Синергетическое применение двух концепций
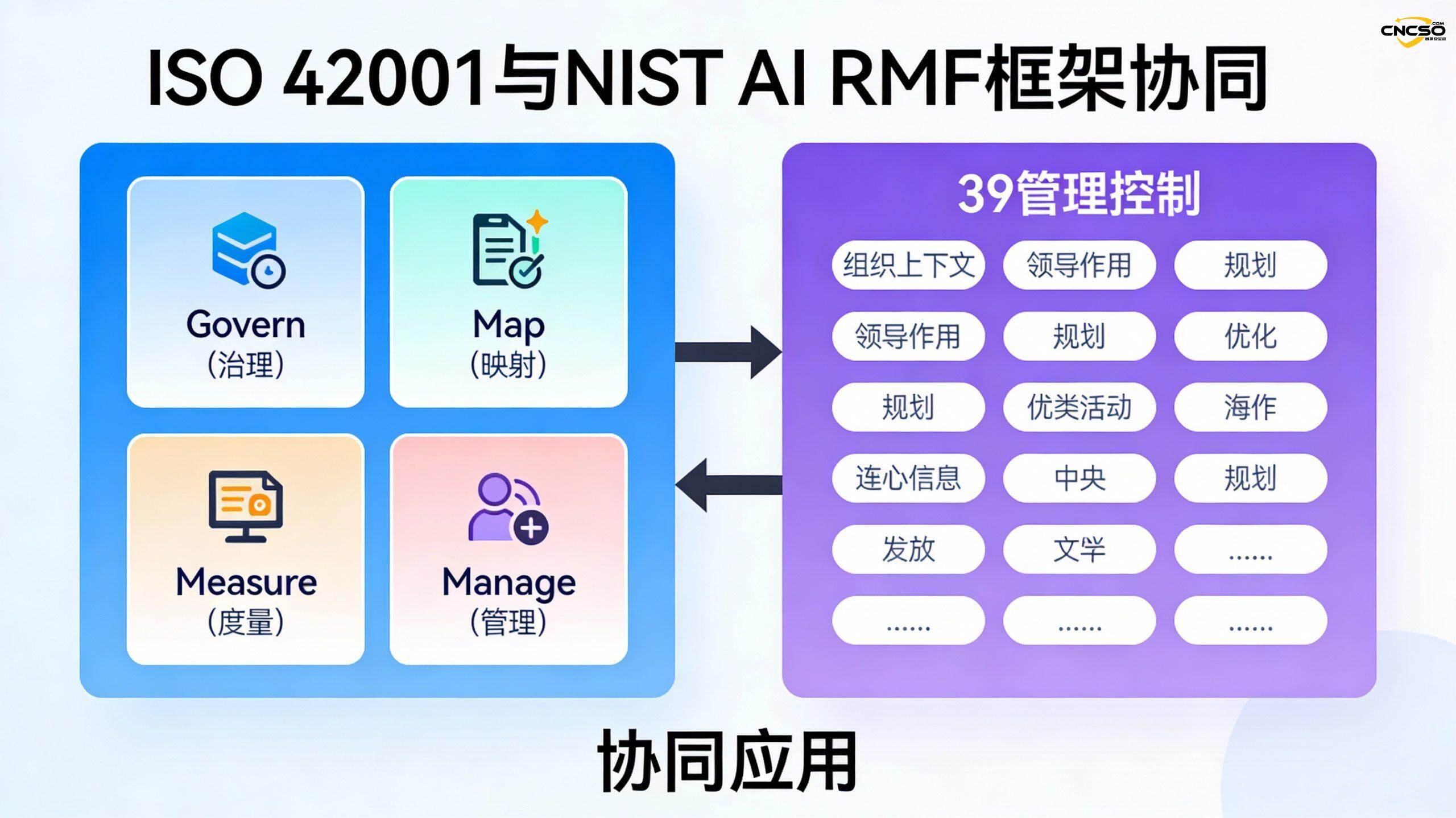
Компании могут использовать ISO/IEC 42001 в сочетании с NIST AI RMF:
- Выявление и оценка рисков, связанных с ИИ, с помощью NIST AI RMF
- Создание более комплексной системы управления ИИ с использованием ISO/IEC 42001
- Взаимосвязь между этими двумя системами позволяет организациям более эффективно добиваться соответствия требованиям.
VII. Практические случаи и лучшие практики
7.1 Пример: цепочка атак систем искусственного интеллекта в перспективе
Чтобы глубже понять, как на самом деле возникают угрозы безопасности с помощью ИИ, давайте проанализируем реалистичный сценарий атаки - обход модели обнаружения вредоносного ПО:
Этап I: разведка
- Злоумышленники обнаружили, что модель обнаружения вредоносных программ, используемая компанией, основана на методах, опубликованных в научных работах.
- Проанализировав блог компании и техническую документацию, удалось выяснить, что используется определенный фреймворк с открытым исходным кодом
Этап 2: Посещение моделей
- Злоумышленники неоднократно запрашивают API системы безопасности компании, чтобы проследить за реакцией модели на различные входные данные.
- Граница классификационного решения модели определяется с помощью статистического анализа
Стадия III: подготовка к атаке
- Воспроизвел аналогичную модель в своей собственной среде
- Разработка образцов с использованием методов градиентного спуска, которые позволяют обмануть модели и классифицировать вредоносное ПО как легитимное.
- Добавление общих функций обхода к образцам противника гарантирует, что они будут работать для целевой модели
Этап IV: Реализация
- Отправка тщательно разработанных образцов вредоносного ПО (содержащих функции обхода) в систему обнаружения компании.
- Модель неверно классифицировала его как легитимное программное обеспечение, и вредоносная программа успешно обошла защиту.
Откровение защиты:
- Чтобы сделать модель невосприимчивой к таким тонким возмущениям, необходимо провести тренировку на устойчивость к состязаниям.
- Внедрение поведенческого анализа для обнаружения программ, которые кажутся легитимными, но ведут себя ненормально
- Ограничение частоты и обнаружение аномальных паттернов для API-запросов для предотвращения масштабного зондирования со стороны злоумышленников
7.2 Рекомендации по созданию системы безопасности искусственного интеллекта на предприятии
Основываясь на матрице угроз безопасности ИИ и системе защиты, предприятия должны следовать следующим принципам при создании системы безопасности ИИ:
- Расстановка приоритетов с учетом рисков: определяйте приоритеты защитных мер с учетом влияния на бизнес и вероятности угроз. Вместо того чтобы стремиться быть всем для всех, следует сосредоточить ресурсы на областях с высоким риском и высокой степенью воздействия.
- Охват всего жизненного цикла: не только фаза вывода модели, но и защита всех аспектов сбора данных, обучения, тонкой настройки, развертывания и обслуживания.
- Глубина защиты: многоуровневая защита (например, четырехслойная система защиты, предложенная в данной статье) используется для развертывания мер контроля на нескольких уровнях, чтобы избежать единых точек отказа.
- Непрерывное развитие: угрозы безопасности ИИ постоянно развиваются, поэтому организациям необходимо создать механизмы непрерывного управления уязвимостями, тестирования на проникновение и обновления средств защиты.
- Межкомандное сотрудничество: безопасность ИИ - это не только ответственность команды безопасности, но и необходимость сотрудничества нескольких команд, таких как инженеры ИИ, менеджеры по продуктам, юристы, операторы и специалисты по обслуживанию.
- Прозрачность и интерпретируемость: укрепление доверия путем четкого описания возможностей, ограничений и мер безопасности систем ИИ для пользователей и заинтересованных сторон.
VIII. Заключение: создание перспективной системы безопасности с искусственным интеллектом
Матрица угроз безопасности ИИ предоставляет организациям систематизированную и действенную основу для выявления и реагирования на многомерные угрозы для систем ИИ. В отличие от традиционной кибербезопасности, безопасность ИИ отличается уникальной сложностью - атаки могут происходить на все аспекты данных, моделирования и рассуждений, а возможности и уровень знаний злоумышленника оказывают огромное влияние на жизнеспособность атаки.
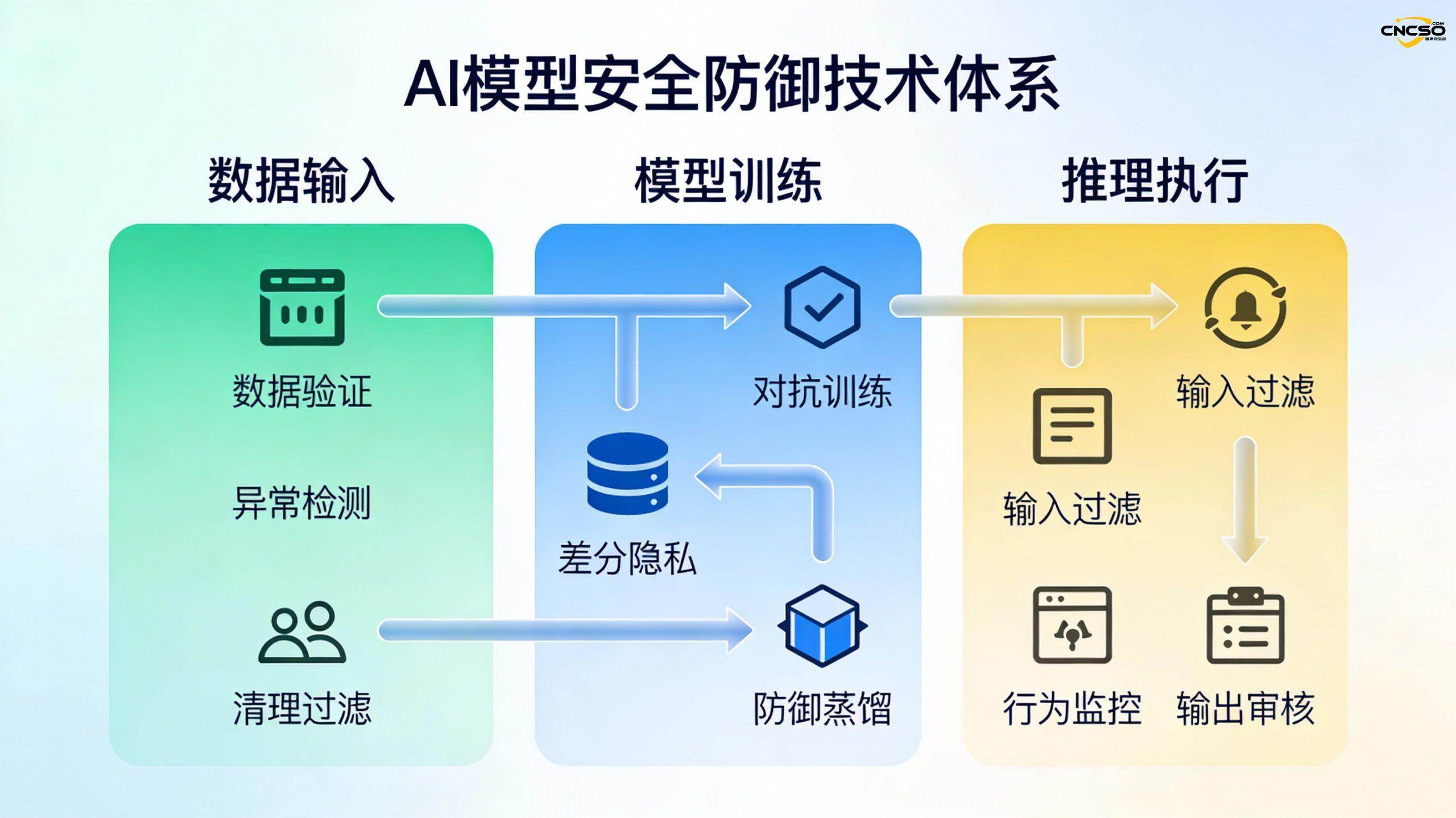
Предприятиям следует учитывать следующее:
- Безопасность ИИ - это системный вопрос, который необходимо решать комплексно, начиная с управления данными, разработки моделей, развертывания приложений, эксплуатации и мониторинга обслуживания, а не полагаться только на одну защитную меру.
- Оценка зрелости очень важна. Понимание существующих угроз, которые уже созрели (например, отравление данных, враждебные образцы), и тех, которые еще изучаются (например, более продвинутые атаки на конфиденциальность), может помочь организациям лучше планировать инвестиции в защиту.
- Защита и развитие должны быть сбалансированы. Некоторые меры защиты (например, дифференциальная конфиденциальность, дистилляция защиты) могут снизить точность модели, и компаниям необходимо найти баланс, исходя из особенностей своего бизнеса.
- Техническая защита должна подкрепляться системами и процессами. Одной технической защиты далеко не достаточно, она также требует создания надежнойУправление безопасностью искусственного интеллектасистема, механизм обучения персонала, план действий в чрезвычайных ситуациях и т.д.
- Согласование со стандартами. Принятие международно признанных стандартов, таких как ISO/IEC 42001 и NIST AI RMF, может помочь организациям систематически создавать системы безопасности ИИ и готовиться к соблюдению нормативных требований.
В условиях быстрого развития технологий ИИ и постоянного изменения угроз предприятиям необходимо создать постоянно развивающуюся и адаптивную систему безопасности ИИ, а матрица угроз безопасности ИИ является важной основой этой системы.
цитирование ссылок
- Официальный сайт матрицы угроз безопасности ИИ:https://aisecmatrix.org/matrix
- NIST AI Risk Management Framework:https://airc.nist.gov/
- ISO/IEC 42001: стандарты системы менеджмента AI, выпущенные Международной электротехнической комиссией
- Фреймворк MITRE ATLAS: ATT&CK-подобный фреймворк для систем ИИ и машинного обучения
Оригинальная статья написана Chief Security Officer, при воспроизведении просьба указывать: https://www.cncso.com/ru/ai-security-based-on-the-attck-framework.html.







