
一、 引言:从软件安全到模型安全的范式转移
传统信息安全体系(CIA三要素)主要建立在代码与逻辑的确定性之上。然而,AI系统的引入导致攻击面发生了本质变化:威胁不再仅限于代码漏洞,更延伸至数据供应链的完整性与模型推理的不可解释性。2023年6月,Google基于其内部十余年的AI防御经验,正式发布SAIF框架。该框架并非单一工具的集合,而是一套覆盖模型全生命周期(MLOps + DevSecOps)的方法论,旨在解决“如何保护AI”与“如何用AI进行防御”的双重命题。
二、 架构核心:SAIF六大支柱深度解构
SAIF的设计理念并非推倒重来,而是主张在现有安全体系上进行“适配性扩展”。其架构由六个相互依存的支柱构成:

1. 夯实安全基座(Strong Security Foundations)
这是防御体系的物理层与逻辑层基础。SAIF主张将传统基础设施的安全控制延伸至AI生态:
-
供应链完整性:利用SLSA(Supply-chain Levels for Software Artifacts)框架确保模型训练数据、代码及配置文件的来源可信与防篡改。这要求对训练数据集建立严格的“成分清单”(SBOM)管理。
-
默认安全架构:在模型训练与推理环境中强制实施最小权限原则(PoLP)与零信任架构,防止通过模型接口横向移动至核心数据资产。
2. 泛化检测与响应(Extend Detection and Response)
面对AI特有的威胁(如模型窃取、成员推理攻击),传统的基于特征码的检测手段已失效。本支柱强调:
-
全链路遥测:建立对模型输入(Prompts)、输出(Outputs)及中间层激活状态的监控机制。
-
异常行为分析:识别非典型的推理模式,例如突发的长序列查询或特定的对抗性样本特征,将其纳入组织现有的SOC(安全运营中心)威胁情报流中。
3. 自动化防御体系(Automate Defenses)
鉴于AI攻击的规模化与自动化特征(如自动化生成的对抗样本),防御手段必须具备同等速度:
-
AI对抗AI:利用机器学习模型自动生成漏洞补丁、识别钓鱼攻击或过滤恶意提示词。
-
动态扩展:确保防御机制能随模型调用量的激增而线性扩展,避免因DDOS攻击导致的安全熔断。
4. 平台级控制协同(Harmonize Platform Controls)
针对企业内部存在的“影子AI”现象,SAIF主张:
-
统一治理平面:在组织层面标准化AI开发平台(如Vertex AI, TensorFlow Extended),避免因工具链碎片化导致的安全策略脱节。
-
资产可视性:建立统一的AI模型资产库,确保所有部署的模型均处于受控的配置管理之下。
5. 自适应控制机制(Adapt Controls)
AI系统的非确定性要求安全控制具备动态适应能力:
-
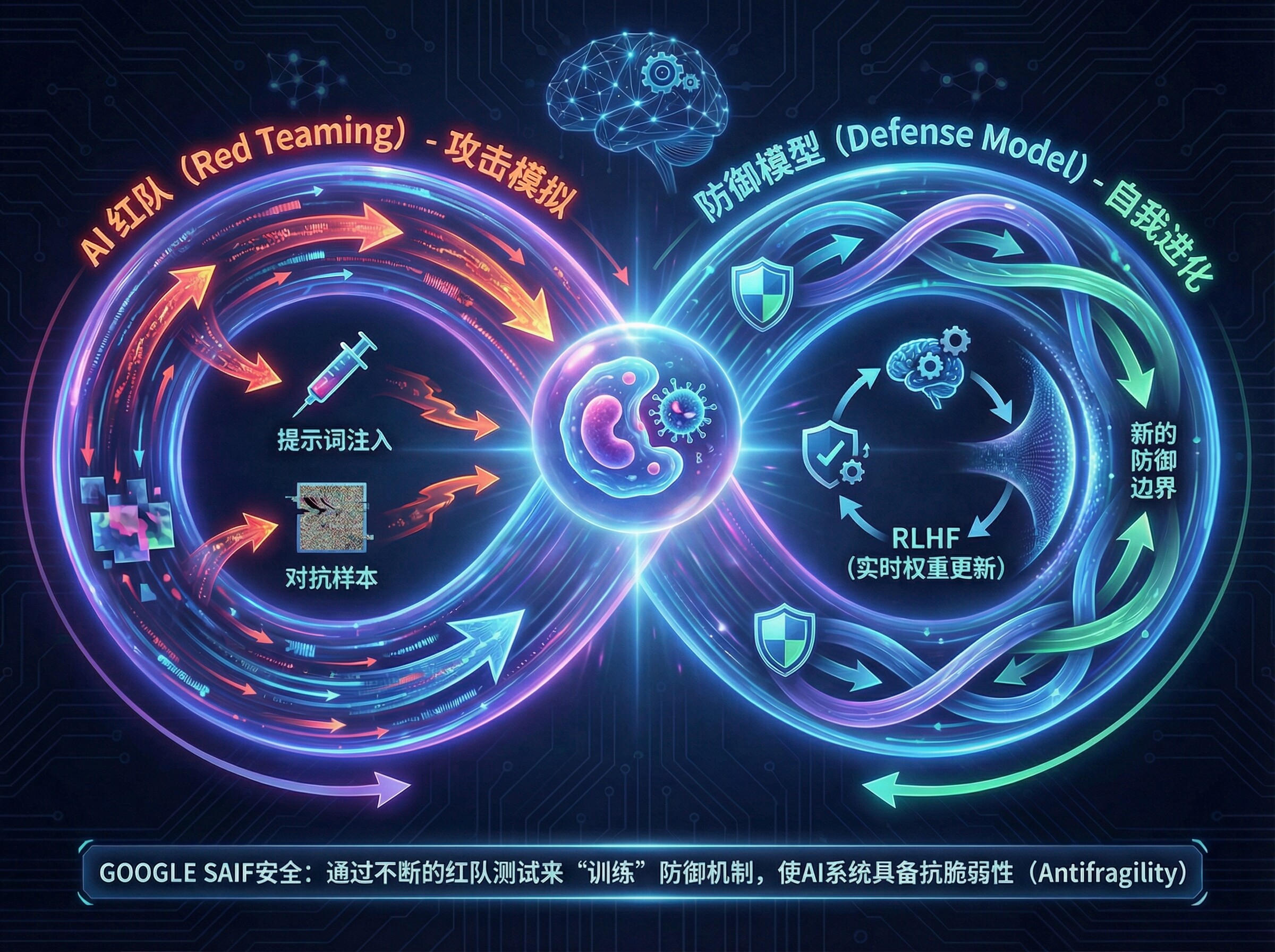
反馈闭环:基于强化学习(RLHF)理念,将安全测试(如红队演练)的结果实时反馈至模型微调过程中,使模型具备“内生免疫力”。
-
鲁棒性测试:定期进行对抗性测试,验证模型在遭受扰动时的稳定性,而非仅关注功能准确率。
6. 风险情境化(Contextualize Risks)
拒绝“一刀切”的合规策略,强调基于业务场景的风险评估:
-
领域差异化:医疗诊断AI与代码生成AI面临的风险权重截然不同(前者重隐私,后者重完整性)。SAIF要求建立基于场景的风险分级模型,避免过度防御阻碍业务创新。
三、 SAIF安全生态与标准化进程
SAIF并非Google的私有领地,而是构建开放安全生态的基石。其生态演进呈现出显著的“去中心化”与“标准化”趋势。
-
CoSAI与开源贡献:
2025年9月,Google向OASIS Open旗下的安全AI联盟(Coalition for Secure AI, CoSAI)捐赠了SAIF的核心数据与方法论,其中包括CoSAI风险图谱(CoSAI Risk Map)。这一举措将SAIF从企业内部框架提升为行业通用的开源标准,协助各方建立统一的AI威胁分类语言。 -
国际标准对齐:
SAIF的设计深度契合NIST AI风险管理框架(AI RMF)及ISO/IEC 42001标准。通过将SAIF的工程实践与ISO的管理体系相结合,企业可更顺畅地通过相关合规认证(如欧盟AI法案合规)。
四、 工具链与实战资源
为推动SAIF落地,Google及社区提供了一系列工程化资源:
-
AI红队(AI Red Team)演练机制:
Google引入了专门针对AI系统的红队测试方法论,模拟现实世界中的对抗性攻击(如提示词注入、训练数据提取)。其定期发布的《AI红队报告》成为行业识别新型攻击向量的重要情报源。
-
模型装甲(Model Armor):
作为SAIF在Google Cloud上的具象化落地,Model Armor提供了一层独立于基础模型的安全过滤网,能够实时拦截恶意的输入输出,防范包括越狱(Jailbreak)在内的多种攻击。 -
SAIF风险评估工具:
提供结构化的自查清单,帮助组织识别当前AI系统在数据隐私、模型鲁棒性及供应链安全方面的短板。
五、 演进与展望
回顾Google在AI安全领域的发展历程,清晰可见其从“原则”向“工程”的演进脉络:
-
2018年:发布AI原则(AI Principles),确立伦理边界。
-
2023年:正式推出SAIF框架,不仅关注“AI本身的安全”,也包含“用AI保障安全”。
-
2025年:通过CoSAI实现框架的开源化与标准化,推动全球AI安全共识的形成。
未来,随着Agentic AI(代理式AI)的兴起,SAIF预计将进一步向“自主系统安全”演进,重点解决AI代理在自主决策过程中的授权控制与行为边界问题。
Google的安全AI框架(SAIF)代表了当前业界对AI系统安全防护的最佳理解与实践成果的总结。通过其系统的框架设计、综合的要素构成、清晰的实施路径,SAIF为各类组织提供了一份实用的安全防护指南。
更为重要的是,SAIF所体现的思想——从被动到主动、从技术到管理、从单组织到生态——反映了安全防护认识的不断深化与升华。在生成式AI快速发展的当下,建立科学、系统、可持续的安全防护体系是迫在眉睫的任务,而SAIF无疑为这一任务的完成提供了有力的支撑。
随着AI技术的进一步发展与应用的深化,SAIF框架本身也将面临不断的演进与完善。但其所奠定的基础性认识——安全防护需要从战略、组织、技术等多个维度进行综合考虑——必将对行业的长期发展产生深远的影响。
参考文献
Google. (2023). Secure AI Framework (SAIF). Google Safety Center. https://safety.google/intl/zh-HK_ALL/safety/saif/
Google. (2025). Google Donates Secure AI Framework (SAIF) Data to Coalition for Secure AI. OASIS Open.
Google AI Red Team. (2023). Google AI Red Team Report: The Ethical Hackers Making AI Safer.
Google Cloud. (2021). Google introduces SLSA framework. Google Cloud Blog.
National Institute of Standards and Technology (NIST). (2023). AI Risk Management Framework (AI RMF 1.0).
原创文章,作者:lyon,如若转载,请注明出处:https://www.cncso.com/google-saif-ai-security-framework.html







