
I. Einleitung:KI-SicherheitDringlichkeit der Bedrohung und systemisches Denken
Mit dem weit verbreiteten Einsatz von Large Language Models (LLMs) und generativer KI hat sich dieKünstliche Intelligenz (KI)Das System ist zu einer Frage der Geschäftskontinuität geworden,Datensicherheitund kritische Infrastrukturen für den Schutz der Privatsphäre der Nutzer. Im Gegensatz zur herkömmlichen Cybersicherheit weisen KI-Systeme jedoch einzigartige Merkmale auf: Angriffe können während des gesamten Lebenszyklus der Datenerfassung, des Modelltrainings, der Feinabstimmung und Optimierung, der Bereitstellung von Schlussfolgerungen und der Überwachung von Betrieb und Wartung auftreten. Von der böswilligen Vergiftung von Daten zur Beeinträchtigung der Modellbeurteilungsfähigkeit über sorgfältig konzipierte gegnerische Proben zur Irreführung von Systementscheidungen bis hin zur verdeckten Einspeisung von Schlüsselwörtern zur Umgehung des Sicherheitsschutzes stehen KI-Systeme vor noch nie dagewesenen Sicherheitsherausforderungen.
Die gemeinsam von Tencent AI Lab, Tencent Jubilee Lab und der Chinesischen Universität Hongkong (Shenzhen) herausgegebene KI-Sicherheitsrisikomatrix ist das erste Mal, dass die neuesten Forschungsergebnisse auf dem Gebiet der KI-Sicherheit systematisch aus der Perspektive des gesamten Lebenszyklus zusammengestellt werden. Die Matrix basiert auf dem ausgereiften ATT&CK-Rahmenwerk als theoretischer Grundlage und beleuchtet den Angriffsprozess und die technischen Implementierungsmöglichkeiten, denen KI-Systeme aus der Sicht des Gegners begegnen können, so dass Unternehmen die Risikopunkte schnell ausfindig machen, das Bedrohungsniveau einschätzen und Abwehrmaßnahmen ergreifen können. In diesem Papier werden wir Folgendes erörternMatrix für AI-Sicherheitsbedrohungenanalysiert systematisch die wichtigsten Angriffsvektoren und bietet bewährte Praktiken für die Unternehmensabwehr in mehreren Dimensionen.
II. die Matrix für KI-Sicherheitsbedrohungen: Kernrahmen und Klassifizierungssystem
2.1 Anwendung der ATT&CK-Methodik auf KI-Domänen
Das ATT&CK-Framework (Adversarial Tactics, Techniques & Common Knowledge) ist im Bereich der Cybersicherheit relativ ausgereift und in der Lage, das Angriffsverhalten aus der Perspektive des Gegners systematisch zu beschreiben. Die KI-Bedrohungsmatrix ist genau die Anwendung dieser bewährten Methodik auf den Bereich der KI, wobei ein praktischer Leitfaden erstellt wird. Die AI Security Threat Matrix wendet diese bewährte Methodik auf den Bereich der KI an und bildet einen technischen Rahmen mit praktischen Anleitungen.
Die Einzigartigkeit der KI-Sicherheitsmatrix im Vergleich zu traditionellen Cybersecurity-Bedrohungsmodellen ist:
- Vollständige Abdeckung des Lebenszyklus: Vom Aufbau der Umgebung, der Datenerfassung, dem Modelltraining, der Feinabstimmung und Optimierung, der Einsatzinferenz bis hin zur Wartung und Instandhaltung deckt die Matrix jeden Aspekt des KI-Systems ab.
- Reifegradhierarchie: Angriffstechniken werden in drei Reifegrade eingeteilt - ausgereifte Bedrohungen (tatsächlich erfolgte Angriffe), untersuchte Bedrohungen (durch akademische Forschung validiert, aber noch nicht weit verbreitet) und potenzielle Bedrohungen (theoretisch möglich, aber noch nicht in der Praxis gesehen).
- Entwurf der Angreiferperspektive: direkte Darstellung, wie der Angreifer das KI-System Schritt für Schritt durchbricht, um dem Verteidiger zu helfen, die Angriffslogikkette zu verstehen.
- Praktische Hinweise: Die Matrix beschreibt nicht nur die Bedrohungen, sondern gibt auch gezielte Empfehlungen für die Verteidigung und Möglichkeiten zur Schadensbegrenzung.
2.2 Wichtige Klassifizierungen von KI-Sicherheitsbedrohungen

Die AI Security Threat Matrix kategorisiert die Bedrohungen für KI-Systeme in neun Hauptbereiche, die jeweils mehrere spezifische Angriffsvektoren enthalten:
| Kategorie der Bedrohung | Wesentliche Merkmale | Wichtigste Wirkungsdimensionen |
|---|---|---|
| Datenvergiftung/ Irreführung (Poisoning) | Einschleusen bösartiger Proben in Trainings- oder Feinabstimmungsdaten | Integrität, Zuverlässigkeit |
| Gegensätzliches | Reasoning durch Modelle der Feinststörung Fehlleitung | Integrität, Zuverlässigkeit |
| Datenschutz | Extrahieren von Trainingsdaten oder Ableiten sensibler Informationen | Vertraulichkeit, Privatsphäre |
| Cue word injection (Sofortige Injektion) | Konstruktion bösartiger Befehle zur Umgehung der Sicherheit | Integrität, Verfügbarkeit |
| Modell-Extraktion/Diebstahl (IP-Bedrohung) | Ableitung der Modellstruktur und der Parameter durch Abfrage | Geistiges Eigentum, Vertraulichkeit |
| Missbräuchliche Verwendung | Einsatz von KI-Systemen für schädliche Zwecke | Einhaltung der Vorschriften, Reputation |
| Angriff auf die Lieferkette | Verunreinigung von abhängigen Modellen, Daten oder Komponenten | Integrität, Verfügbarkeit |
| Vorurteile und Diskriminierung (Biases) | Das Modell lernt die Verzerrungen in den Trainingsdaten | Fairness, Ruf, rechtliches Risiko |
| Unzuverlässiger Output | Modell-Illusion, Drift oder ungenaue Ergebnisse | Verlässlichkeit, Reputation |
III. die KI-Angriffskette: der gesamte Prozess von der Aufklärung bis zur Ausführung
Die Matrix für KI-Sicherheitsbedrohungen verwendet die Angriffskette als zentralen organisatorischen Rahmen, der klar aufzeigt, wie Angreifer die Abwehrmechanismen von KI-Systemen Schritt für Schritt durchbrechen. Der Prozess ähnelt dem Kill-Chain-Modell der traditionellen Cybersicherheit, ist aber speziell auf die einzigartigen Merkmale von KI-Systemen zugeschnitten.
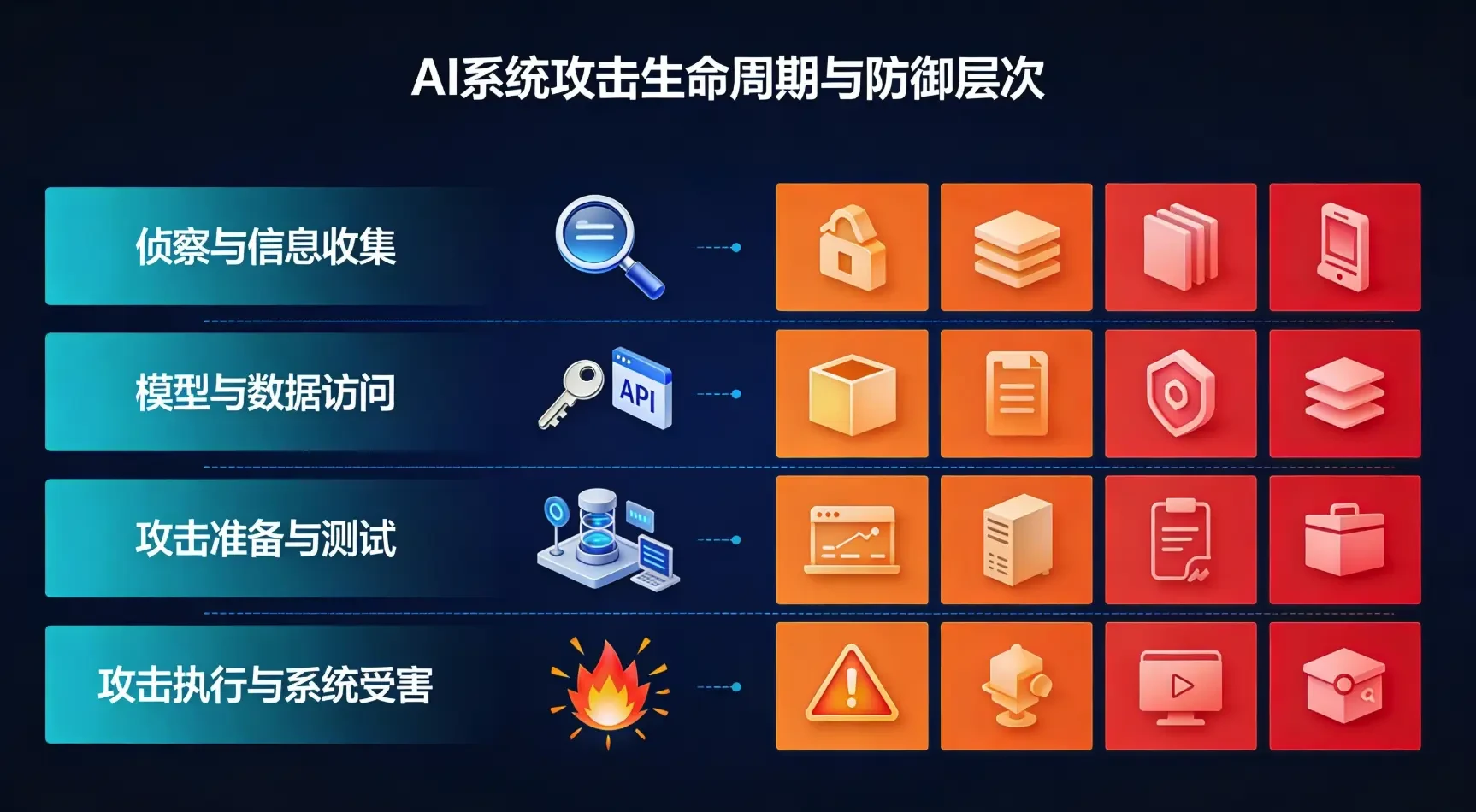
3.1 Phase I: Erkundung und Informationsbeschaffung (Erkundung)
Merkmale der Stufe: Der Angreifer versucht, die Gesamtsituation des Ziel-KI-Systems zu verstehen, einschließlich der Einsatzumgebung, der Art der verwendeten Modelle, der API-Schnittstellen und der Merkmale der Trainingsdaten.
Spezifische technische Mittel:
- Sammlung öffentlicher Informationen: Die technischen Details des Zielmodells werden über akademische Arbeiten, technische Dokumente, Konferenzpräsentationen, GitHub-Repositories, Modellkarten und andere Kanäle beschafft.
- API-Sondierung: Analyse der Eingabe- und Ausgabemerkmale des Modells und Rückschlüsse auf die interne Architektur durch Aufruf der API des KI-Dienstes. So kann ein Angreifer beispielsweise verschiedene Arten von Abfragen senden und die Antwortmuster des Modells aufzeichnen, um dessen Klassifizierungslogik abzuleiten.
- Identifizierung der Umgebung: Feststellung, auf welcher Cloud-Plattform das KI-System eingesetzt wird, welche Open-Source-Frameworks oder kommerziellen Modelle verwendet werden und welche Art von Datenflussmethoden eingesetzt werden.
Verteidigungsstrategie:
- Begrenzung des Umfangs, in dem die Modelldokumentation veröffentlicht wird, um eine übermäßige Offenlegung technischer Details zu vermeiden
- Implementierung von Grenzwerten für die Häufigkeit von API-Abfragen und Erkennung von anormalem Verhalten
- Überwachung von Open-Source-Projekten und Diskussionen in den sozialen Medien im Zusammenhang mit dem Modell
3.2 Phase 2: Modellierung und Datenzugang (Modellzugang)
Merkmale der Phase: Der Angreifer verschafft sich direkten oder indirekten Zugang zum KI-Zielsystem, um nachfolgende tiefgreifende Angriffe vorzubereiten.
Spezifische technische Mittel:
- Black-Box-Zugang: Abfrage des Modells über die API und Beobachtung der Ausgabedaten wie Konfidenzwerte und Wahrscheinlichkeitsverteilungen. Diese Art der Abfrage ist kostengünstig, liefert aber nur begrenzte Informationen. Der Angreifer kann jedoch mithilfe statistischer Methoden schrittweise auf Modelleigenschaften schließen.
- Grey-Box-Zugang: Erhalt von Teilinformationen des Modells (z. B. Ausgaben der mittleren Schicht, Informationen über den Gradienten), was die Entwicklung präziserer Angriffe ermöglicht.
- White-Box-Zugriff: vollständiger Zugriff auf die Modellstruktur und -parameter, der in der Regel nach einem Insider-Leck oder nach dem Knacken eines Modells erfolgt.
Verteidigungsstrategie:
- Einführung einer strengen Zugangskontrolle und Authentifizierung
- Begrenzung der Granularität der von der API zurückgegebenen Informationen (z. B. keine spezifischen Wahrscheinlichkeitswerte zurückgeben, sondern nur Klassifizierungsergebnisse)
- Einsatz von Grenzwerten für die Abfragehäufigkeit und Erkennung von Anomalien
- Verwendung von Techniken zur Verbesserung der Privatsphäre (wie z. B.differenzierte Privatsphäre) Unscharfe Ausgangsinformationen
3.3 Phase 3: Angriffsvorbereitung und -test (Attack Staging)
Merkmale der Phase: Die Angreifer entwerfen und testen Angriffsmethoden in einer selbst konstruierten Umgebung, validieren ihre Wirksamkeit und stimmen sie dann auf der Grundlage der in der Aufklärungs- und Zugriffsphase gewonnenen Informationen ab.
Spezifische technische Mittel:
- Erzeugung von Negativproben: Verwendung der eigenen Daten und des eigenen Modells, um Eingabeproben zu erstellen, die das Zielmodell in die Irre führen können. Wenn man beispielsweise einem Bild Rauschen hinzufügt, das für das menschliche Auge nicht wahrnehmbar ist, erkennt der Zielklassifikator einen Hund als Katze.
- Konstruktion von Datenvergiftungsmustern: Entwicklung von bösartigen Trainingsmustern, die das Urteilsvermögen des Zielmodells während des Lernprozesses beeinträchtigen können, z. B. Angriffe durch Umkehrung von Kennzeichnungen oder versteckte Hintertürchen.
- Entwicklung von Vorlagen für Prompt-Word-Angriffe: Entwurf verschiedener Arten von Vorlagen für Prompt-Word- und Injektionsangriffe zum Gefängnisausbruch unter Verwendung der Funktionen von LLM. Diese Vorlagen können eine Vielzahl von Techniken verwenden, einschließlich Denial-of-Suppression, Rollenspiele, semantische Verschleierung, etc.
Verteidigungsstrategie:
- Durchführung gegnerischer Robustheitstests, um Modellschwachstellen im Voraus zu erkennen und zu beheben
- Einrichtung eines vollständigen Systems für die Destillation von Verteidigungsmodellen und die Ausbildung von Gegnern
- Strenge Eingabevalidierung und Bereinigungsmechanismen implementieren
3.4 Phase 4: Ausführung des Angriffs und Viktimisierung des Systems (Execution)
Merkmale der Phase: Der Angreifer führt einen gut durchdachten Angriff auf ein reales Zielsystem durch, um ein vorher festgelegtes Ziel zu erreichen. Je nach dem Ziel des Angriffs umfasst diese Phase eine Vielzahl von Techniken:
3.4.1 Angriffe zum Vergiften von Daten (Data Poisoning)
Prinzip: Ein Angreifer injiziert bösartige Muster in die Trainings- oder Feinabstimmungsdaten des Modells und veranlasst das Modell, die falsche Zuordnungsbeziehung zu lernen.
Spezifische Typen:
- Label-Flipping-Angriffe: Umkehrung der Kennzeichnung normaler Proben, z. B. Kennzeichnung von "legitimen E-Mails" als "Spam". Es hat sich gezeigt, dass eine Verunreinigung von nur etwa 0,0011 TP3T der Daten zu einem erheblichen Modellversagen führen kann.
- Hidden-Label-Attacke: Anstatt die Etiketten der Proben zu ändern, wird das Modell dazu gebracht, die vom Angreifer festgelegten Ergebnisse unter bestimmten Bedingungen auszugeben, indem subtile Merkmalsauslöser eingefügt werden. Dieser Angriff ist sehr viel schwieriger zu erkennen.
- Hidden Feature Poisoning: Einfügen von falschen Merkmalen in die Trainingsdaten, die stark mit einer bestimmten Kategorie korreliert sind, z. B. das Hinzufügen von visuellen Elementen, die mit "Explosion" zusammenhängen, zu einem Trainingsbild von "Blume" veranlasst das Modell, "Blume" mit "Gefahr" zu assoziieren. Dies veranlasst das Modell, "Blume" mit "Gefahr" zu assoziieren.
Verteidigungsmechanismen:
- Datenbereinigung und -validierung: Erkennung von Ausreißern und statistische Analyse von Trainingsdaten zur Identifizierung und Entfernung von Proben, die im Verdacht stehen, vergiftet zu sein.
- Robustes Training: Mithilfe von Techniken wie adversarialem Training lernen die Modelle, gegen kontaminierte Daten resistent zu sein.
- Datenvielfalt: Das Sammeln von Schulungsdaten aus mehreren vertrauenswürdigen Quellen verringert das Risiko, dass eine einzige Datenquelle vollständig kontrolliert wird.
- Differenzielle Privatsphäre: Während des Trainings wird Rauschen hinzugefügt, um den Einfluss einzelner Proben auf das Modell zu begrenzen.
3.4.2 Versuchsmuster und Versuchsangriffe (Versuchsbeispiele)
Prinzip: Ein Angreifer bringt ein Modell dazu, falsche Vorhersagen zu machen, indem er ausgeklügelte Störungen an den Eingaben vornimmt, die für den Menschen weitgehend unsichtbar sind.
Typischer Fall:
- Angriffe auf die Bildklassifizierung: Hinzufügen von sorgfältig berechneten Störgeräuschen zu Fotos, damit Autopilot-Systeme Straßenschilder falsch erkennen.
- Angriffe auf die Spracherkennung: Einbettung von Frequenzen in den Ton, die für das menschliche Gehör nicht wahrnehmbar sind, so dass Sprachassistenten unbeabsichtigte Befehle ausführen.
Verteidigungsmechanismen:
- Defensive Destillation: Das Trainieren eines Schülermodells mit einem robusteren Lehrermodell verringert die Empfindlichkeit des Modells gegenüber gegnerischen Stichproben.
- Regularisierungstechniken: Verwendung von Einschränkungen wie L1/L2-Regularisierung, um eine Überanpassung des Modells an bestimmte Eingabemuster zu verhindern.
- Erkennung von Anomalien: Einsatz von Detektoren für anomale Proben, um Eingaben, bei denen der Verdacht besteht, dass es sich um antagonistische Proben handelt, während der Inferenz zu identifizieren und zurückzuweisen.
- Eingangstransformation und -rekonstruktion: Entrauschung des Eingangs, bevor er in das Modell eingeht, z. B. JPEG-Kompression, Gauß-Filterung usw.
3.4.3 Angriffe auf die Privatsphäre (Privacy Leakage & Membership Inference)
Bedrohungs-Szenarien:
- Extraktion von Trainingsdaten: Der Angreifer gewinnt nach und nach die echten Daten, die beim Training des Modells verwendet wurden, indem er das Modell wiederholt abfragt. So können beispielsweise medizinische Aufzeichnungen oder Finanzdaten, die persönliche Informationen der Nutzer enthalten, wiederhergestellt werden.
- Model Inversion Attack (MIA): Der Angreifer analysiert die Ausgabe des Modells, um auf die Merkmale der Trainingsdaten zu schließen, die einer bestimmten Eingabe entsprechen. Anhand des Gesichtserkennungsmodells kann der Angreifer das ursprüngliche Gesichtsbild auf der Grundlage der Vertrauensausgabe des Modells rekonstruieren.
- Membership Inference Attack (MIA): Ein Angreifer nutzt die Verhaltensmerkmale eines Modells, um daraus zu schließen, ob ein bestimmter Datenpunkt zum Training verwendet wurde. Dies stellt eine ernsthafte Bedrohung für den Schutz der Privatsphäre dar, insbesondere in sensiblen Bereichen wie dem Gesundheits- und Finanzwesen.
Verteidigungsmechanismen:
- Differenzielles Privatsphären-Training: Durch Hinzufügen von sorgfältig konzipiertem Rauschen zum Gradienten oder zu den Daten wird sichergestellt, dass die Entfernung einzelner Stichproben das Modellverhalten nicht wesentlich verändert.
- Datenklassifizierung und -minimierung: Kennzeichnung sensibler Daten und Einschränkung ihrer Verwendung beim Modelltraining.
- Federated Learning: dezentralisiertes Training von Modellen auf mehreren Edge-Geräten, so dass die gesamten Trainingsdaten für das zentrale System unzugänglich sind.
- Inferenzerkennung: Aufbau einer Erkennungspipeline zur Identifizierung von Risiken für Datenschutzverletzungen in modellgeneriertem Text.
3.4.4 Prompt Injection & Jailbreak-Angriffe (Prompt Injection & Jailbreak)
Prinzip: Angreifer versuchen, die Sicherheitsvorkehrungen des LLM zu umgehen, indem sie sorgfältig Eingabeaufforderungen konstruieren, die das Modell dazu veranlassen, Inhalte zu generieren, die schädlich, beleidigend oder mehr als erwartet sind.
Spezifische Angriffe:
- Direkte Injektion des Stichworts:
- Angreifer mischen Sonderzeichen, seltsame Suffixe oder bedeutungslose Symbole ein, um die Sicherheitsfiltermechanismen des Modells zu verwirren.
- Ablehnungshemmung: Das Modell wird durch umgekehrte Psychologie oder indirekte Darstellung veranlasst, die Sicherheitsregel "Das kann ich nicht" zu ignorieren.
- Rollenspiel: Wenn das Modell in ein fiktives Szenario eintaucht, ist es leichter, es in die falsche Richtung zu lenken.
- Indirekte Injektion des Stichworts:
- Vergiftung von Webdaten: Domänen, deren Gültigkeit abgelaufen ist und die in den Trainingsdaten des Modells auftauchen, werden gekauft, mit bösartigen Inhalten gefüllt und verseucht, wenn das Modell sie abruft.
- Hidden Instruction Injection: Einbettung spezieller Anweisungen in scheinbar harmlose Bilder, Audiodateien oder PDFs, die aktiviert werden, wenn das Modell multimodale Eingaben verarbeitet.
- Ein gegnerisches System führt zu undichten Stellen:
- Der Angreifer fälscht Nachrichten, die vom System zu stammen scheinen, und veranlasst das Modell, seine verborgenen Systemstichwörter auszugeben, um etwas über die Beschränkungen des Modells zu erfahren.
Verteidigungsmechanismen:
- Filterung und Bereinigung von Eingaben: vordefinierte schwarze Listen und Regeln, wobei jedoch zu berücksichtigen ist, dass es für Regeln schwierig ist, alle komplexen semantischen Angriffe abzudecken.
- Modellbasierte Erkennung von Anomalien: Die Verwendung von Erkennungsmodellen zur Identifizierung bösartiger Stichwörter ist flexibler als Blacklisting-Methoden.
- Absichtserkennung: Ein spezielles Modul zur Absichtserkennung wird hinzugefügt, um festzustellen, ob ein Benutzer versucht, eine Übersteuerung vorzunehmen.
- Adversariales Training: Fügen Sie "cue-injected-correct-answer"-Proben zu den Trainingsdaten hinzu, um die Widerstandsfähigkeit des Modells zu verbessern.
- Kreuzvalidierung mit mehreren Modellen: Verarbeiten Sie dieselbe Eingabe parallel mit mehreren LLMs und vergleichen Sie die Konsistenz der Ausgabeergebnisse.
- Erkennung von Übereinstimmungen mit der Ausgabe: Die Modellausgabe wird auf Übereinstimmungen mit der ursprünglichen Aufgabe geprüft, und Antworten, die von der erwarteten abweichen, werden zurückgewiesen.
3.4.5 Modellextraktion und Wissensdiebstahl (Modellextraktion)
Prinzip: Der Angreifer stiehlt das geistige Eigentum des Modells, indem er die Struktur, die Parameter oder das Verhalten des Zielmodells durch umfangreiche Abfragen und Reverse Engineering kopiert oder ableitet.
Spezifische Techniken:
- Black-Box-Modellreplikation: Training eines alternativen Modells, um das Verhalten des Zielmodells durch ein statistisches API-Aufrufmuster zu simulieren.
- Gradienteninversion: Verwendung der Informationen über den Ausgangsgradienten des Modells, um die Parameter des Modells Schritt für Schritt abzuleiten.
Verteidigungsmechanismen:
- Modell-Wasserzeichen: Einbettung verdeckter Wasserzeichen in Modellparameter, um das Eigentum am Modell zu überprüfen und gestohlene Kopien zu erkennen.
- Abfragekontrolle: Begrenzung der Häufigkeit von API-Abfragen, Erkennung und Zurückweisung abnormaler Abfragemuster.
- Verschleierung der Ausgabe: Reduzierung der Granularität der von der API zurückgegebenen Informationen, z. B. Rückgabe nur der endgültigen Klassifizierungsergebnisse und nicht des Konfidenzniveaus.
IV. Lieferkette und ökologische Sicherheit: eine neue Art der Bedrohung für KI-Systeme
Mit dem Aufschwung des Ökosystems der KI ist die Sicherheit der Lieferkette zu einer neuen Dimension geworden, die nicht ignoriert werden kann. Unternehmen bauen KI-Systeme nur selten von Grund auf neu auf. Stattdessen werden sie schnell durch die Integration von vorab trainierten Modellen, Open-Source-Frameworks, APIs von Drittanbietern und Cloud-Computing-Diensten bereitgestellt. Dieses hochkomplexe Lieferkettensystem birgt noch nie dagewesene Risiken:
4.1 Modellierung des Risikos in der Lieferkette
- Verunreinigung von vortrainierten Modellen: Open-Source-Modelle oder Modellgewichte aus nicht vertrauenswürdigen Quellen können vergiftet oder mit Hintertüren versehen worden sein.
- Abhängigkeitsschwachstelle: Das Deep-Learning-Framework oder die verwendeten Abhängigkeitspakete können bekannte oder Zero-Day-Schwachstellen aufweisen, die von einem Angreifer ausgenutzt werden können.
- Risiko von Feinabstimmungsdaten: Bei der Feinabstimmung auf der Grundlage eines vorab trainierten Modells kann das gesamte Modell beschädigt werden, wenn die Feinabstimmungsdaten kontaminiert sind.
4.2 Strategien zur Verteidigung der Lieferkette
- Bewertung und Zertifizierung von Anbietern: Durchführung von Sicherheitsaudits bei allen Drittanbietern, um zu überprüfen, ob sie die Sicherheitsstandards des Unternehmens einhalten.
- Bill of Materials (SBOM) Management: Führen Sie eine detaillierte Software-Stückliste, in der Sie die Quellen und Versionen von Modellen, Frameworks und Abhängigkeitspaketen verfolgen.
- Modellsignatur und -überprüfung: Signieren Sie alle eingesetzten Modelle digital, um Manipulationen zu verhindern.
- Kontinuierliche Überwachung und Schwachstellen-Scans: Regelmäßige Schwachstellen-Scans und Sicherheitsbewertungen aller Komponenten des KI-Systems.
V. Mehrstufiges Verteidigungssystem zum Schutz der KI-Sicherheit in Unternehmen
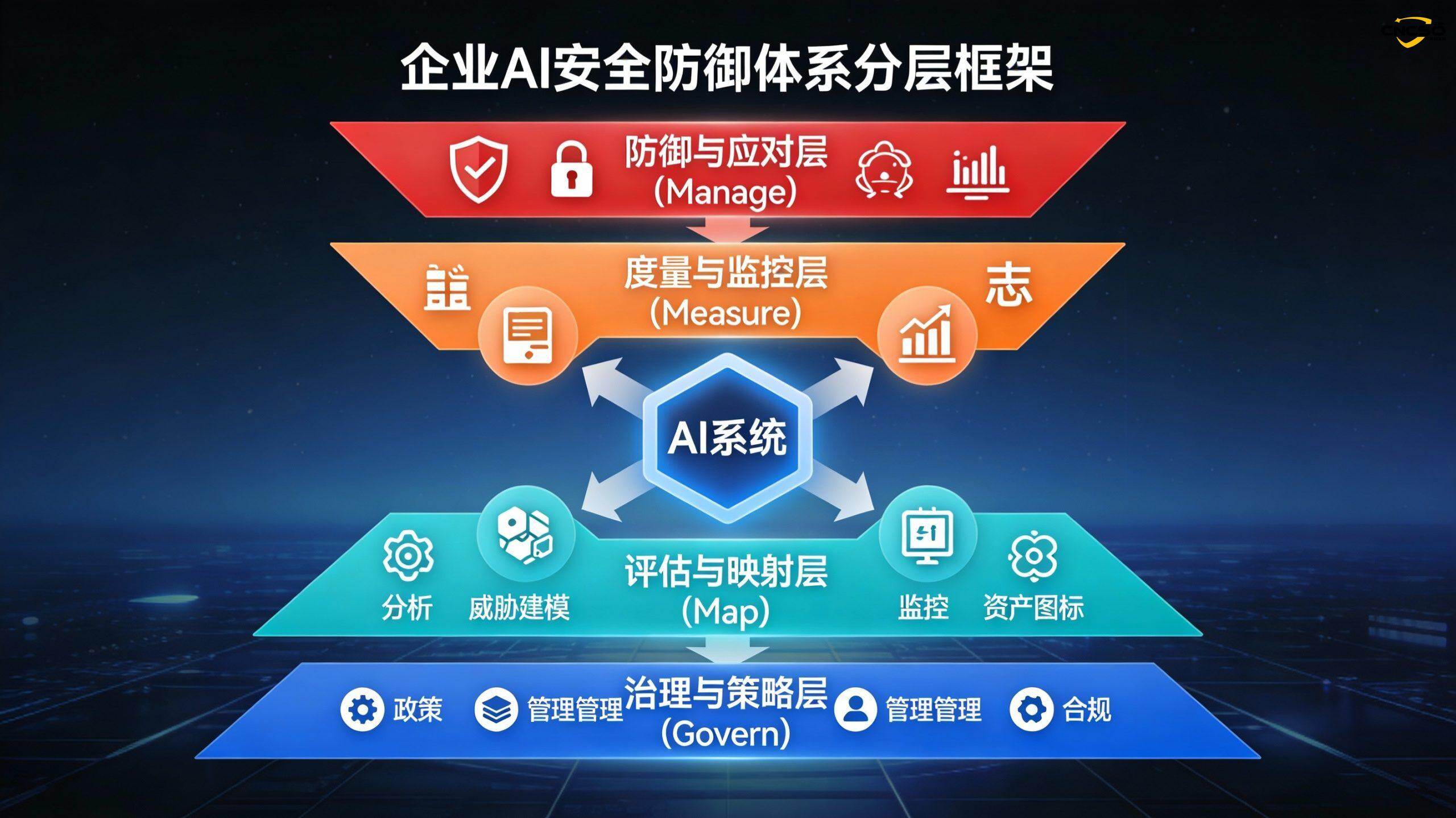
5.1 Ebene 1: Governance- und Strategieebene (Govern)
Ziel: Schaffung einer KI-Sicherheitskultur und eines entsprechenden Rahmens auf Unternehmensebene, um sicherzustellen, dass die KI-Sicherheit von oben bis unten ernst genommen wird.
Kritische Kontrollen:
- Entwicklung einer KI-Sicherheitspolitik: Klärung des Verständnisses der Organisationen fürSicherheit des AI-SystemsPositionen, Anforderungen und Standards.
- Risikomanagementprozess: Einführung eines standardisierten Prozesses zur Identifizierung, Bewertung und Bewältigung von KI-Sicherheitsrisiken und Gewährleistung, dass alle neuen KI-Anwendungen einer Risikoprüfung unterzogen werden.
- Rollen und Zuständigkeiten: Ermittlung der für die KI-Sicherheit verantwortlichen Personen in der Organisation, einschließlich Dateneigentümer, Modellentwickler, Sicherheitsingenieure usw.
- Compliance-Anforderungen: Entwicklung eines angemessenen Compliance-Rahmens im Einklang mit den regulatorischen Anforderungen (z. B. GDPR, AI Act usw.), insbesondere in Bezug auf Datenschutz und Fairness.
5.2 Schicht 2: Bewertungs- und Kartierungsschicht (Karte)
Ziel: Umfassende Identifizierung potenzieller Risikopunkte im KI-System und Schaffung einer Grundlage für nachfolgende Abwehrmaßnahmen.
Hauptaktivitäten:
- Bestandsaufnahme: Aufzählung aller KI-Modelle, Datensätze, Anwendungen und Infrastrukturen im Unternehmen sowie Klassifizierung und Kennzeichnung dieser.
- Bedrohungsmodellierung: systematische Ermittlung möglicher Angriffsszenarien mit Hilfe von Bedrohungsmodellierungsmethoden (z. B. STRIDE usw.).
- Datenflussanalyse: Verfolgen Sie, wie Daten durch das gesamte KI-System fließen, und ermitteln Sie Risikopunkte für die Datenexposition. Zum Beispiel, wo sensible Nutzerdaten gespeichert werden und wo in verschiedenen Phasen darauf zugegriffen wird.
- Abhängigkeitsanalyse: Abbildung von Abhängigkeiten zwischen Modellen, Identifizierung kritischer Pfade und einzelner Fehlerpunkte.
5.3 Ebene 3: Mess- und Überwachungsebene (Maßnahme)
Ziel: Kontinuierliche Bewertung des Sicherheitsstatus von KI-Systemen durch quantitative Messgrößen und Überwachungsmechanismen.
Schlüsselindikatoren und Mechanismen:
- Baseline der Modellleistung: Erstellung einer Baseline der Leistung (Genauigkeit, Latenz, Durchsatz usw.) im Normalbetrieb und Erkennung von Anomalien, die auf Angriffe oder Modellabweichungen hindeuten könnten.
- Sicherheitsauditprotokoll: Vollständige Aufzeichnung aller Eingaben und Ausgaben des Modells, Konfigurationsänderungen, Änderungen der Zugriffsrechte usw. für die Untersuchung von Ereignissen und die Forensik.
- Bewertung der Robustheit gegenüber Angriffen: Das Modell wird in regelmäßigen Abständen anhand von Stichproben getestet, um seine Widerstandsfähigkeit gegenüber Angriffen zu bewerten.
- Bewertung des Datenschutzes: Anwendung von Techniken wie z.B. Membership Inference Attacks, um zu beurteilen, ob Modelle zu viele Trainingsdaten speichern.
- Erkennung von Verhaltensanomalien: Echtzeit-Überwachung des Ausgabeverhaltens des Modells, um signifikante Abweichungen von historischen Mustern zu erkennen, die auf einen erfolgreichen Angriff hindeuten könnten.
5.4 Stufe 4: Verteidigungs- und Reaktionsstufe (Verwalten)
Zielsetzung: Durchführung spezifischer technischer Kontrollmaßnahmen zur Verringerung der Wahrscheinlichkeit und der Auswirkungen von Risiken.
Spezifische Maßnahmen:
Schutz der Datenschicht
- Klassifizierung und Kennzeichnung von Daten: Klassifizierung von Daten nach ihrer Sensibilität und strengerer Schutz für hochsensible Daten.
- Zugriffskontrolle: Durchsetzung des Prinzips der geringsten Privilegien, Begrenzung der Zugriffsrechte auf bestimmte Daten und Verwaltung von Berechtigungen auf der Grundlage von Identität, Rolle und Kontext.
- Datenverschlüsselung: Bei der Übertragung und Speicherung wird eine starke Verschlüsselung verwendet, um ein Abfangen oder Durchsickern von Daten zu verhindern.
- Desensibilisierung und Anonymisierung von Daten: Entfernen oder Verschlüsseln sensibler persönlicher Informationen bei der Schulung oder Präsentation von Daten.
Schutz der Modellebene
- Adversariales Training: Während des Trainingsprozesses werden adversarische Proben hinzugefügt, um die Robustheit des Modells zu verbessern.
- Regularisierung und defensive Destillation: Einsatz von Regularisierungstechniken zur Verringerung der Überanpassung und Destillation zur Komprimierung des Modells und Verbesserung der Robustheit.
- Differenzielle Privatsphäre: Fügt der Gradientenaktualisierung Rauschen hinzu, um die Auswirkungen einzelner Proben auf das Modell zu begrenzen.
- Modellvalidierung und -tests: umfassende Sicherheitstests vor der Einführung, einschließlich Tests mit gegnerischen Stichproben, Datenschutzbewertung usw.
- Modellsignatur und Integritätserkennung: Mit digitalen Signaturen wird sichergestellt, dass das Modell nicht manipuliert wurde, und mit Hash-Checks werden Anomalien in Echtzeit erkannt.
Schutz der Anwendungsschicht
- Eingabevalidierung und -bereinigung: Strenge Validierung und Bereinigung aller Benutzereingaben, Herausfiltern bösartiger oder ungewöhnlicher Eingaben.
- Ausgabefilterung: Der Inhalt wird überprüft, um Ausgaben mit schädlichen, illegalen oder sensiblen Informationen abzulehnen, bevor die Modellausgabe den Benutzern angezeigt wird.
- Ratenbegrenzung und Abfragekontrolle: Begrenzen Sie die Häufigkeit und Anzahl der Abfragen für einen einzelnen Benutzer oder eine IP, um Missbrauch zu verhindern.
- Verwaltung von Datenquellen für RAG-Systeme: Wenn Retrieval Augmented Generation (RAG) verwendet wird, werden externe Datenquellen streng kontrolliert und geprüft, um die Einspeisung von bösartigen Inhalten zu verhindern.
Schutz der Gewebeschicht
- Sicherheitsschulungen für Mitarbeiter: Sensibilisierung des technischen Teams für KI-Sicherheitsbedrohungen und Vermittlung sicherer Entwicklungspraktiken.
- Plan zur Reaktion auf Zwischenfälle: Entwicklung eines klaren Verfahrens zur Reaktion auf Zwischenfälle, einschließlich Erkennung, Isolierung, Untersuchung und Wiederherstellung.
- Lieferantenmanagement: Prüfen Sie regelmäßig die Sicherheitspraktiken von Drittanbietern, um sicherzustellen, dass sie den Unternehmensstandards entsprechen.
- Bewertungen durch Dritte: Externe Sicherheitsorganisationen werden aufgefordert, unabhängige Penetrationstests und Sicherheitsaudits durchzuführen.
VI. Standardisierung von KI-Sicherheitsrahmen: ISO/IEC 42001 und das NIST AI RMF
6.1 ISO/IEC 42001: AI-Managementsystem-Norm
ISO/IEC 42001 ist die erste internationale Norm für AI-Managementsysteme und bietet eine strukturierte Anleitung für Organisationen zur Einrichtung und Aufrechterhaltung eines AI-Managementsystems. Seine wichtigsten Merkmale sind:
- Breiter Anwendungsbereich: deckt den gesamten Lebenszyklus eines KI-Systems ab, von der Planung bis zum Betrieb und zur Wartung.
- 39 Verwaltungskontrollen: Sie decken ein breites Spektrum von Aspekten wie KI-Governance, Risikomanagement, Datenschutz und Transparenz ab.
- Zertifizierungsaudit: Unterstützt Audits und Zertifizierungen durch Dritte, um Organisationen bei der Validierung ihrerAI-Sicherheitspraktiken.
6.2 NIST AI Risk Management Framework (NIST AI RMF)
Das NIST AI RMF ist ein vom National Institute of Standards and Technology veröffentlichtes freiwilliges Rahmenwerk, das sich auf das KI-Risikomanagement konzentriert und vier Kernfunktionen enthält:
- Governance: Schaffung einer risikobewussten Kultur und Festlegung von Risikomanagementstrategien und -verfahren
- Karte: Identifizierung potenzieller Risiken in KI-Systemen
- Maßnahme: Bewertung der Wahrscheinlichkeit und der Auswirkungen der ermittelten Risiken
- Verwalten: Umsetzung von Maßnahmen zur Risikominderung
6.3 Synergistische Anwendung der beiden Rahmenwerke
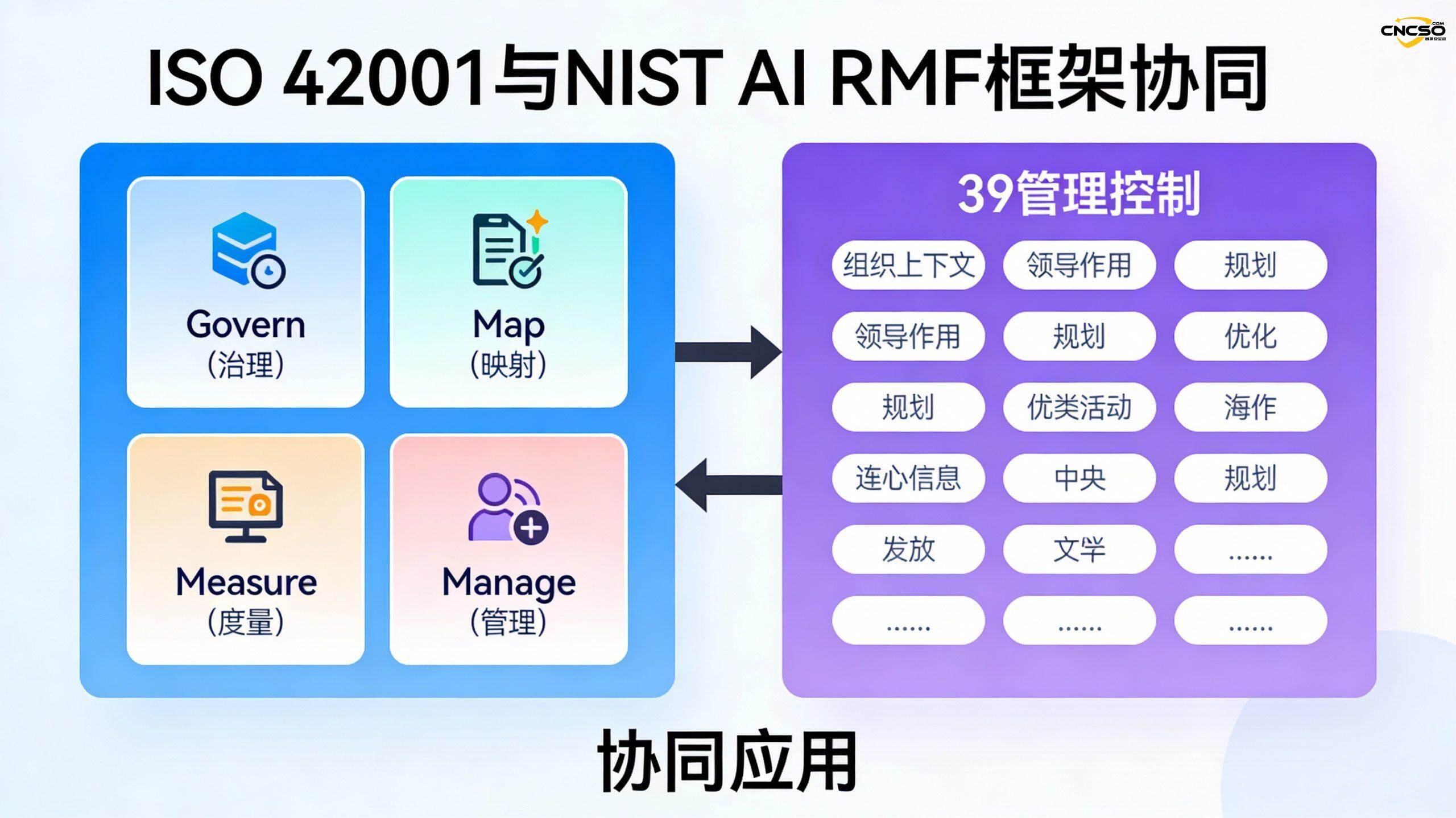
Unternehmen können ISO/IEC 42001 in Verbindung mit der NIST AI RMF verwenden:
- AI-spezifische Risikoidentifizierung und -bewertung unter Verwendung des NIST AI RMF
- Aufbau eines umfassenderen AI-Managementsystems mit ISO/IEC 42001
- Die Zuordnung zwischen den beiden Rahmenwerken ermöglicht es Organisationen, die Einhaltung der Vorschriften effizienter zu erreichen.
VII. praktische Fälle und bewährte Praktiken
7.1 Fallstudie: Angriffskette von KI-Systemen in der Angriffsperspektive
Um ein tieferes Verständnis dafür zu erlangen, wie KI-Sicherheitsbedrohungen tatsächlich auftreten, wollen wir ein realistisches Angriffsszenario analysieren - einen Angriff zur Umgehung des Malware-Erkennungsmodells:
Phase I: Erkundung
- Die Angreifer entdeckten, dass das von einem Unternehmen verwendete Malware-Erkennungsmodell auf Methoden basierte, die in akademischen Arbeiten veröffentlicht worden waren
- Die Analyse des Blogs und der technischen Dokumentation des Unternehmens ergab, dass ein spezielles Open-Source-Framework verwendet wurde
Stufe 2: Modellbesuche
- Angreifer fragen wiederholt die Sicherheits-API des Unternehmens ab, um die Reaktion des Modells auf verschiedene Eingaben zu beobachten
- Die Klassifizierungsentscheidungsgrenze des Modells wird durch statistische Analyse abgeleitet
Stufe III: Vorbereitung auf den Angriff
- ein ähnliches Modell in seinem eigenen Umfeld nachgebaut hat
- Entwicklung negativer Muster unter Verwendung von Gradientenabstiegsmethoden, die Modelle dazu bringen können, Malware als legitime Software zu klassifizieren
- Das Hinzufügen von generischen Bypass-Merkmalen zu den gegnerischen Stichproben stellt sicher, dass sie für das Zielmodell funktionieren
Stufe IV: Umsetzung
- Übermittlung sorgfältig erstellter Malware-Muster (mit Umgehungsfunktionen) an das Erkennungssystem des Unternehmens
- Das Modell stufte sie fälschlicherweise als legitime Software ein, und die Malware umging erfolgreich die Schutzmaßnahmen
Offenbarung der Verteidigung:
- Um das Modell unempfindlich gegenüber solchen subtilen Störungen zu machen, muss ein Robustheitstraining für den Gegner durchgeführt werden.
- Einführung einer Verhaltensanalyse zur Erkennung von Software, die legitim erscheint, sich aber abnormal verhält
- Häufigkeitsbegrenzung und Erkennung anomaler Muster für API-Abfragen, um ein großflächiges Sondieren durch Angreifer zu verhindern
7.2 Best-Practice-Empfehlungen für den Aufbau von KI-Sicherheit im Unternehmen
Auf der Grundlage der KI-Sicherheitsbedrohungsmatrix und des Verteidigungsrahmens sollten Unternehmen beim Aufbau eines KI-Sicherheitssystems die folgenden Grundsätze beachten:
- Risikoorientierte Prioritätensetzung: Priorisierung der Schutzmaßnahmen auf der Grundlage der Auswirkungen auf das Unternehmen und der Wahrscheinlichkeit der Bedrohung. Anstatt zu versuchen, alles für alle zu sein, sollten die Ressourcen auf Bereiche mit hohem Risiko und hoher Auswirkung konzentriert werden.
- Vollständige Abdeckung des Lebenszyklus: nicht nur die Phase der Modellinferenz, sondern auch alle Aspekte der Datenerfassung, des Trainings, der Feinabstimmung, des Einsatzes und der Wartung sind geschützt.
- Verteidigungstiefe: Eine mehrschichtige Verteidigung (wie das in diesem Papier vorgeschlagene vierschichtige Verteidigungssystem) wird verwendet, um Kontrollmaßnahmen auf mehreren Ebenen einzusetzen, um einzelne Fehlerpunkte zu vermeiden.
- Kontinuierliche Weiterentwicklung: KI-Sicherheitsbedrohungen entwickeln sich ständig weiter, und Unternehmen müssen kontinuierliche Mechanismen für die Verwaltung von Schwachstellen, Penetrationstests und die Aktualisierung der Verteidigung einrichten.
- Teamübergreifende Zusammenarbeit: KI-Sicherheit liegt nicht nur in der Verantwortung des Sicherheitsteams, sondern erfordert auch die Zusammenarbeit mehrerer Teams wie KI-Ingenieure, Produktmanager, Rechtsabteilung, Betrieb und Wartung.
- Transparenz und Interpretierbarkeit: Schaffen Sie Vertrauen, indem Sie die Fähigkeiten, Grenzen und Sicherheitsmaßnahmen von KI-Systemen für Nutzer und Interessengruppen klar beschreiben.
VIII. Schlussfolgerung: Aufbau eines zukunftssicheren KI-Sicherheitssystems
Die Matrix für KI-Sicherheitsbedrohungen bietet Unternehmen einen systematischen und umsetzbaren Rahmen, um mehrdimensionale Bedrohungen für KI-Systeme zu erkennen und auf sie zu reagieren. Im Gegensatz zur traditionellen Cybersicherheit ist die KI-Sicherheit einzigartig komplex - Angriffe können in allen Bereichen der Daten, der Modellierung und des Denkens auftreten, und die Fähigkeiten und der Wissensstand des Angreifers haben einen großen Einfluss auf die Durchführbarkeit des Angriffs.
Die Unternehmen sollten Folgendes beachten:
- KI-Sicherheit ist ein systemisches Problem, das ganzheitlich angegangen werden muss, von der Datenverwaltung über die Modellentwicklung, die Anwendungsbereitstellung und den Betrieb bis hin zur Überwachung der Wartung, anstatt sich auf eine einzige Abwehrmaßnahme zu verlassen.
- Reifegradbewertungen sind wichtig. Ein Verständnis der aktuellen Bedrohungen, die ausgereift sind (z. B. Datenvergiftung, gegnerische Stichproben) und derjenigen, die noch erforscht werden (z. B. fortgeschrittenere Angriffe auf die Privatsphäre), kann Organisationen helfen, ihre Investitionen in die Verteidigung besser zu planen.
- Verteidigung und Entwicklung müssen ausgewogen sein. Einige Verteidigungsmaßnahmen (z. B. differenzierter Datenschutz, Destillation der Verteidigung) können die Genauigkeit des Modells beeinträchtigen, und die Unternehmen müssen auf der Grundlage ihrer Geschäftsmerkmale ein Gleichgewicht finden.
- Die technische Verteidigung muss durch Systeme und Verfahren unterstützt werden. Die technische Verteidigung allein reicht bei weitem nicht aus, sie erfordert auch die Schaffung soliderAI Security GovernanceSystem, Mechanismus für die Schulung des Personals, Notfallplan für Zwischenfälle usw.
- Angleichung an Standardrahmenwerke. Die Übernahme international anerkannter Normenrahmen wie ISO/IEC 42001 und NIST AI RMF kann Unternehmen dabei helfen, systematisch KI-Sicherheitssysteme aufzubauen und sich auf die Einhaltung von Vorschriften vorzubereiten.
Angesichts der rasanten Entwicklung der KI-Technologie und der sich ständig ändernden Bedrohungslage müssen Unternehmen ein sich ständig weiterentwickelndes und anpassungsfähiges KI-Sicherheitssystem einrichten, und die KI-Sicherheitsbedrohungsmatrix ist die wichtige Grundlage dieses Systems.
Referenzzitat
- Offizielle Website der AI Security Threat Matrix:https://aisecmatrix.org/matrix
- NIST AI Risk Management Framework:https://airc.nist.gov/
- ISO/IEC 42001AI-Managementsystem-Normen, die von der Internationalen Elektrotechnischen Kommission herausgegeben werden
- MITRE ATLAS-Framework: ein ATT&CK-ähnliches Framework für KI und maschinelle Lernsysteme
Originalartikel von Chief Security Officer, bei Vervielfältigung bitte angeben: https://www.cncso.com/de/ai-security-based-on-the-attck-framework.html







