
I. Introduction:AI securityUrgency of the threat and systemic thinking
With the widespread use of large-scale language modeling (LLM) and generative AI, theAIThe system has become a matter of business continuity for the organization,Data Securityand critical infrastructure for user privacy. However, unlike traditional cybersecurity, threats to AI systems have unique characteristics: attacks can occur throughout the lifecycle of data collection, model training, fine-tuning and optimization, inference deployment, and operation and maintenance monitoring. From malicious data poisoning to contaminate the model judgment ability, to carefully designed adversarial samples to mislead system decisions, to covert cue word injection to bypass security protection, AI systems are facing unprecedented security challenges.
Referring to the AI Security Threat Risk Matrix jointly released by Tencent AI Lab, Tencent Jubilee Lab, and The Chinese University of Hong Kong (Shenzhen), it is the first time to systematically sort out the most cutting-edge research results in the field of AI security from the perspective of the whole life cycle. The matrix is based on the mature ATT&CK framework as the theoretical foundation, and elucidates the attack process and technical realization means that AI systems may encounter from the perspective of the adversary, so that enterprises can quickly locate the risk points, assess the threat level, and deploy defensive measures. In this paper, we will discussAI Security Threat Matrixs core content, systematically analyzes major attack vectors, and provides best practices for enterprise defense in multiple dimensions.
II. AI Security Threat Matrix: Core Framework and Classification System
2.1 Application of ATT&CK methodology to AI domains
The ATT&CK (Adversarial Tactics, Techniques & Common Knowledge) framework has been relatively mature in the field of cybersecurity, and is able to systematically characterize attack behaviors from an adversary's perspective.The AI Security Threat Matrix is precisely the application of this proven methodology to the field of AI, constructing a practical guidance AI Security Threat Matrix applies this proven methodology to the field of artificial intelligence and builds a technical framework with practical guidance.
The uniqueness of the AI Security Matrix compared to traditional cybersecurity threat models is:
- Full Lifecycle Coverage: from environment building, data collection, model training, fine-tuning and optimization, deployment inference to maintenance and O&M, the matrix covers every aspect of the AI system.
- Maturity Stratification: attack techniques are categorized into three maturity levels - Mature Threats (attacks that have actually occurred), Threats in Research (validated by academic research but not yet widely available), and Potential Threats (theoretically feasible but not yet seen in practice).
- Adversary perspective design: directly present how the attacker breaks through the AI system step by step to help the defense understand the attack logic chain.
- Practical guidance: In addition to describing the threats, the matrix provides targeted defense recommendations and mitigation options.
2.2 Major Classifications of AI Security Threats

The AI Security Threat Matrix categorizes threats to AI systems into nine main areas, each containing multiple specific attack vectors:
| Threat category | Core features | Key impact dimensions |
|---|---|---|
| Data poisoning/misleading (Poisoning) | Injecting malicious samples into training or fine-tuning data | Integrity, reliability |
| Adversarial | Reasoning through Fine Perturbation Misdirection Models | Integrity, reliability |
| Privacy | Extract training data or infer sensitive information | Confidentiality, privacy |
| Cue word injection (Prompt Injection) | Constructing malicious commands to bypass security | Integrity, availability |
| Model Extraction/Theft (IP Threat) | Derive the model structure and parameters from the query | Intellectual property, confidentiality |
| Misuse | Use of AI systems for harmful purposes | Compliance, reputation |
| Supply Chain Attack | Contamination of dependent models, data or components | Integrity, availability |
| Prejudice and Discrimination (Biases) | The model learns the bias in the training data | Fairness, reputation, legal risk |
| Unreliable Output | Model hallucinations, drifting or inaccurate outputs | Reliability, reputation |
III. The AI attack chain: the complete process from reconnaissance to execution
The AI Security Threat Matrix uses the attack chain as the core organizing framework, clearly mapping how attackers break through the defenses of AI systems step by step. This process is similar to the kill chain model in traditional cybersecurity, but is specifically designed for the unique characteristics of AI systems.
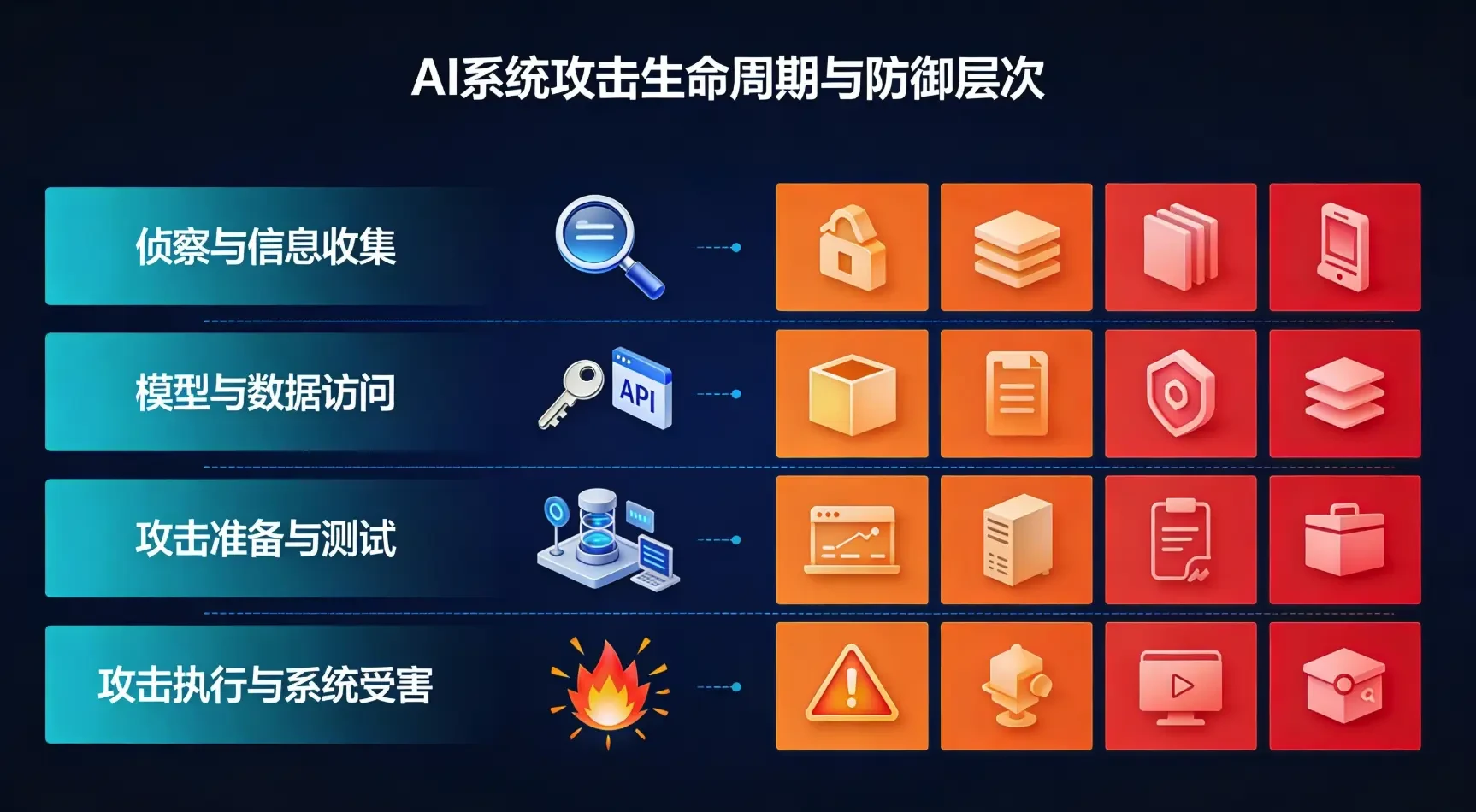
3.1 Phase I: Reconnaissance and Information Gathering (Reconnaissance)
Stage Characteristics: the attacker tries to understand the overall situation of the target AI system, including the deployment environment, the type of models used, API interfaces, and training data characteristics.
Specific technical means:
- Public information collection: obtain technical details of the target model through academic papers, technical documents, conference presentations, GitHub repositories, model cards, and other channels.
- API probing: analyzing the input and output characteristics of the model and inferring the internal architecture by calling the API of the AI service. For example, an attacker can send various types of queries and record the model's response patterns to deduce its classification logic.
- Environment identification: determining which cloud platform the AI system is deployed on, which open source frameworks or commercial models are used, and what kind of data flow methods are employed.
Defense Strategy:
- Limit the extent to which model documentation is made public to avoid over-disclosing technical details
- Implementing API query frequency limits and anomalous behavior detection
- Monitor model-related open source projects and social media discussions
3.2 Phase II: Model and Data Access (Model Access)
Phase Characteristics: the attacker gains direct or indirect access to the target AI system in preparation for subsequent deep attacks.
Specific technical means:
- Black-box access: querying the model through the API and observing the output information such as confidence scores and probability distributions. This type of query is low cost but provides limited information, but the attacker can gradually infer the model characteristics through statistical methods.
- Gray box access: obtain partial model information (e.g., middle layer outputs, gradient information), allowing for the design of more precise attacks.
- White-box access: full access to the model structure and parameters, which usually occurs after an insider leak or a model has been cracked.
Defense Strategy:
- Implement strict access control and authentication
- Limit the granularity of information returned by the API (e.g., do not return specific probability values, only classification results)
- Deployment of query frequency limits and anomaly detection
- Using privacy-enhancing technologies (such asdifferential privacy) Fuzzy output information
3.3 Phase 3: Attack Preparation and Testing (Attack Staging)
Phase Characterization: the attacker designs and tests the attack methodology in a self-constructed environment, verifies its effectiveness, and then fine-tunes it based on the information gained during the reconnaissance and access phases.
Specific technical means:
- Adversarial sample generation: using one's own data and model, design input samples that can mislead the target model. For example, adding noise to an image that is imperceptible to the human eye causes the target classifier to recognize a dog as a cat.
- Data poisoning sample construction: designing malicious training samples capable of contaminating the judgment of the target model as it learns, such as label flipping attacks or hidden backdoor injections.
- Prompt word attack template development: utilizing the features of LLM to design various types of jailbreak prompt word and injection attack templates. These templates may employ a variety of techniques, including denial of suppression, role-playing, semantic obfuscation, etc.
Defense Strategy:
- Perform adversarial robustness testing to preemptively identify and fix model vulnerabilities
- Establishment of a complete model defense distillation and adversarial training system
- Implement rigorous input validation and clean-up mechanisms
3.4 Phase 4: Attack Execution and System Victimization (Execution)
Phase Characterization: The attacker puts a carefully designed attack into a real target system in an attempt to achieve a predetermined goal. Depending on the target of the attack, this phase encompasses a variety of techniques:
3.4.1 Data Poisoning Attacks (Data Poisoning)
Principle: An attacker injects malicious samples into the model's training data or fine-tuning data, causing the model to learn the wrong mapping relationship.
Specific types:
- Label Flip Attack: Reversing the labels of normal samples, e.g., labeling "legitimate emails" as "spam". It has been shown that contaminating only about 0.0011 TP3T of data may induce significant model failure.
- Concealed labeling attack: instead of changing the label of the sample, the model is made to output the result specified by the attacker under specific conditions by inserting subtle feature triggers. This attack is much more difficult to detect.
- Hidden Feature Poisoning: Inserting false features in the training data that are highly correlated with a specific category, for example, adding visual elements related to "explosion" to the training image of "flower", causing the model to associate "flower" with "danger". This causes the model to associate "flower" with "danger".
Defense mechanisms:
- Data cleaning and validation: outlier detection and statistical analysis of training data to identify and remove samples suspected of being poisoned.
- Robust training: using techniques such as adversarial training, the model learns to be resistant to contaminated data.
- Data Diversity: Capturing training data from multiple trusted sources reduces the risk of a single data source being completely controlled.
- Differential privacy: noise is added during training to limit the impact of individual samples on the model.
3.4.2 Adversarial Samples and Adversarial Attacks (Adversarial Examples)
Principle: An attacker causes a model to make false predictions by making elaborate perturbations to the inputs that are largely invisible to humans.
Typical case:
- Image classification attack: adding carefully calculated noise to a photo to make an autopilot system misidentify a road sign.
- Speech Recognition Attacks: embedding frequencies in audio that are imperceptible to human hearing, causing voice assistants to perform unintended commands.
Defense mechanisms:
- Defensive distillation: training a student model with a more robust teacher model reduces the sensitivity of the model to adversarial samples.
- Regularization techniques: use constraints such as L1/L2 regularization to prevent the model from overfitting to specific input patterns.
- Anomaly detection: deploy anomalous sample detectors to recognize and reject inputs suspected to be antagonistic samples during inference.
- Input Transformation and Reconstruction: denoising the input before it enters the model, e.g. JPEG compression, Gaussian filtering, etc.
3.4.3 Privacy Leakage & Membership Inference Attacks (Privacy Leakage & Membership Inference)
Threat Scenarios:
- Training data extraction: the attacker gradually recovers the real data used in model training by repeatedly querying the model. For example, medical records or financial data containing users' personal information can be recovered.
- Model Inversion Attack (MIA): the attacker analyzes the output of the model to infer the features of the training data corresponding to a specific input. On the face recognition model, the attacker can reconstruct the original face image based on the model's confidence output.
- Membership Inference Attack (MIA): attackers infer whether a particular data point has been used for training or not by the behavioral characteristics of the model. This poses a serious threat to privacy protection, especially in sensitive areas such as healthcare and finance.
Defense mechanisms:
- Differential privacy training: adding carefully designed noise to the gradient or data ensures that the removal of individual samples does not significantly alter model behavior.
- Data classification and minimization: flagging sensitive data and limiting its use in model training.
- Federated Learning: decentralized training of models on multiple edge devices, making the complete training data inaccessible to the central system.
- Inference detection: building a detection pipeline to identify privacy leakage risks in model-generated text.
3.4.4 Prompt Injection & Jailbreak Attacks (Prompt Injection & Jailbreak)
Principle: Attackers attempt to bypass LLM's security safeguards by carefully constructing input prompts that induce the model to generate harmful, offending, or more-than-expected content.
Specific Attacks:
- Direct cue word injection:
- Attackers mix in special characters, strange suffixes, or meaningless symbols to confuse the model's security filtering mechanisms.
- Rejection inhibition: Inducing the model to ignore the safety rule "I can't do that" through reverse psychology or indirect representation.
- Role Play: Placing the model in a fictional story scenario makes it easier to steer it in the wrong direction.
- Indirect cue word injection:
- Web data poisoning: domains that have expired and have appeared in model training data are purchased, populated with malicious content, and contaminated when the model retrieves these domains.
- Hidden Instruction Injection: embedding special instructions in seemingly innocuous images, audio or PDFs that are activated when the model processes multimodal inputs.
- The adversarial system prompts leaks:
- The attacker forges messages that appear to come from the system and induces the model to output its hidden system cue words to learn about the model's constraints.
Defense mechanisms:
- Input filtering and cleaning: predefined blacklists and rules, but need to recognize that rules are difficult to cover all complex semantic attacks.
- Model-based anomaly detection: using detection models to identify malicious cue words is more flexible than blacklisting methods.
- Intent Recognition: Add a specialized intent recognition module to determine whether a user is attempting to perform an ultra vires operation.
- Adversarial training: Add "cue-injected-correct-response" samples to the training data to improve the resistance of the model.
- Multi-model cross-validation: process the same input in parallel with multiple LLMs and compare the consistency of the output results.
- Output Match Detection: the model output is checked for matches with the original task and responses that deviate from the expected are rejected.
3.4.5 Model Extraction and Knowledge Stealing (Model Extraction)
Principle: The attacker steals the intellectual property of the model by copying or deriving the structure, parameters or behavior of the target model through extensive querying and reverse engineering.
Specific techniques:
- Black-box model replication: training an alternative model to simulate the behavior of the target model through a statistical API call pattern.
- Gradient inversion: use the output gradient information of the model to derive the parameters of the model step by step.
Defense mechanisms:
- Model watermarking: Embedding covert watermarks in model parameters in order to verify model ownership and detect stolen copies.
- Query Control: Limit API query frequency, detect and reject abnormal query patterns.
- Output obfuscation: reduce the granularity of the information returned by the API, e.g., return only the final classification result and not the confidence level.
IV. Supply chain and ecological security: new types of threats to AI systems
As the AI adoption ecosystem booms, supply chain security has become a new dimension that cannot be ignored. Enterprises rarely build AI systems from scratch, but instead rapidly deploy them by integrating pre-trained models, open-source frameworks, third-party APIs, and cloud computing services. This highly complex supply chain system poses unprecedented risks:
4.1 Modeling supply chain risk
- Pre-trained model contamination: open source models or model weights provided by untrustworthy sources may have been poisoned or embedded with backdoors.
- Dependency Vulnerability: the deep learning framework or dependency packages used may have known or zero-day vulnerabilities that can be exploited by an attacker.
- Fine-tuning data risk: When fine-tuning based on a pre-trained model, if the fine-tuned data is contaminated, the entire model can be corrupted.
4.2 Supply Chain Defense Strategies
- Vendor Assessment and Certification: Conduct security audits of all third-party vendors to verify their compliance with company security standards.
- Bill of Materials (SBOM) Management: Maintain a detailed software bill of materials, tracking the sources and versions of models, frameworks, and dependent packages.
- Model Signature and Verification: digitally sign all deployed models to prevent tampering.
- Continuous Monitoring and Vulnerability Scanning: Vulnerability scanning and security assessment of all components of the AI system on a regular basis.
V. Layered Defense System for Enterprise AI Security Protection
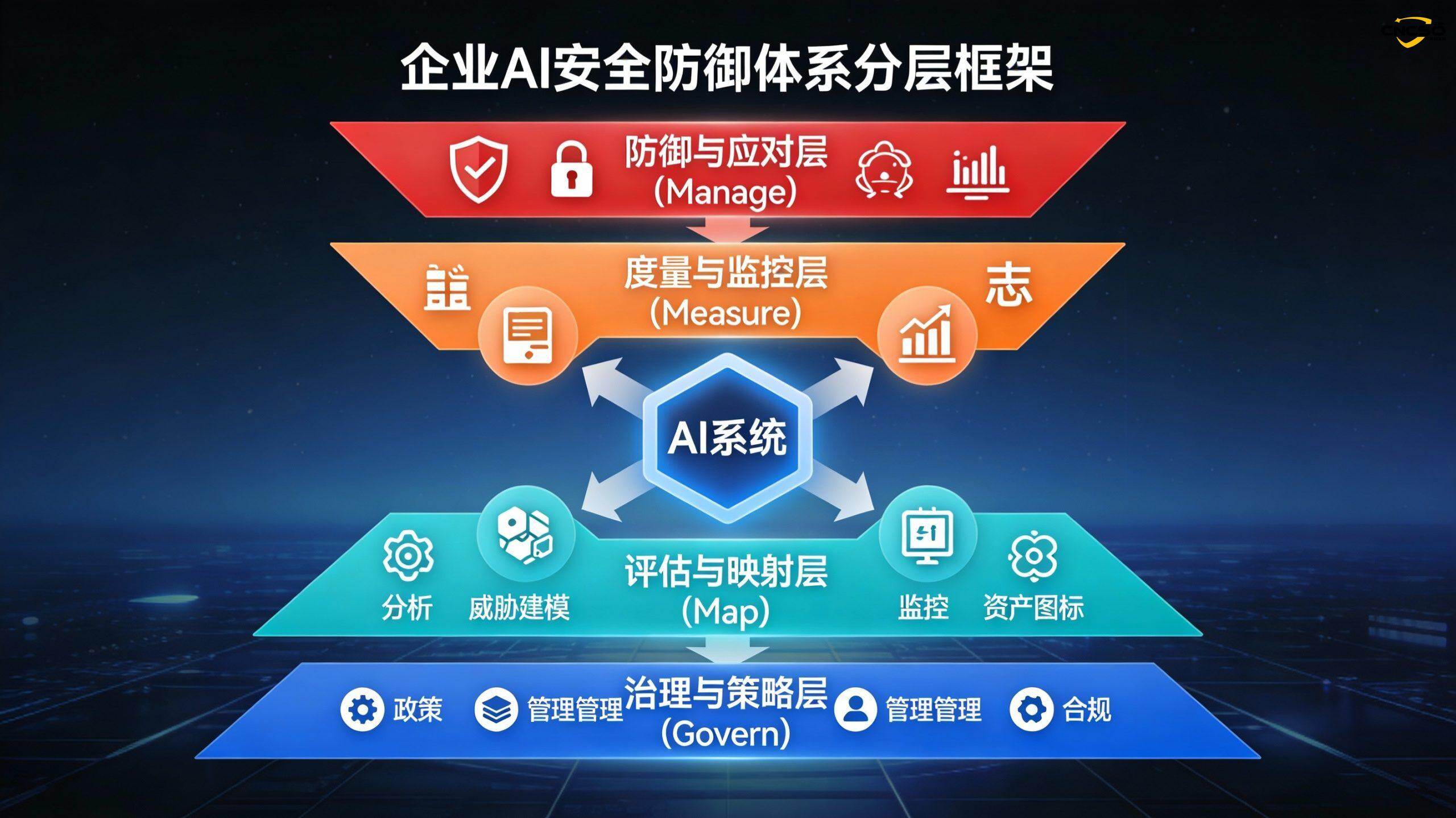
5.1 Tier 1: Governance and Strategy Tier (Govern)
Goal: Establish an organization-level AI security culture and framework to ensure that AI security is taken seriously from top to bottom.
Critical Controls:
- AI security policy development: clarifying the organization's commitment toAI system securitypositions, requirements and standards.
- Risk Management Process: Establish a standardized process for identifying, assessing, and addressing AI security risks, and ensure that all new AI applications undergo a risk review.
- Roles and Responsibilities: identify the responsible parties for AI security in the organization, including data owners, model developers, security engineers, and so on.
- Compliance requirements: develop the appropriate compliance framework in line with regulatory requirements (e.g. GDPR, AI Act, etc.), in particular privacy protection and fairness requirements.
5.2 Layer 2: Assessment and Mapping Layer (Map)
Goal: Comprehensively identify potential risk points in the AI system and provide a basis for subsequent defense measures.
Key activities:
- Asset Inventory: enumerate all AI models, datasets, applications, and infrastructure in the organization and classify and tag them.
- Threat modeling: systematic identification of possible attack scenarios using threat modeling methods (e.g., STRIDE, etc.).
- Data Flow Analysis: Track how data flows through the entire AI system and identify risk points for data exposure. For example, where sensitive user data is stored and accessed at different stages.
- Dependency analysis: mapping dependencies between models, identifying critical paths and single points of failure.
5.3 Tier 3: Measurement and Monitoring Tier (Measure)
Goal: Continuously assess the security status of AI systems through quantitative metrics and monitoring mechanisms.
Key indicators and mechanisms:
- Model performance baseline: establishes a baseline of performance (accuracy, latency, throughput, etc.) during normal operation and detects anomalies that may indicate an attack or model drift.
- Security Audit Log: Complete record of all inputs and outputs of the model, configuration changes, access privilege changes, etc. for event investigation and forensics.
- Adversarial robustness assessment: the model is periodically tested against samples to assess its resistance to attacks.
- Privacy assessment: using techniques such as membership inference attacks to assess whether a model is over-memorizing training data.
- Behavioral anomaly detection: real-time monitoring of the model's output behavior to identify significant deviations from historical patterns that may indicate a successful attack.
5.4 Layer 4: Defense and Response Layer (Manage)
Objective: To implement specific technical control measures to reduce the likelihood and impact of risks.
Specific measures:
Data Layer Protection
- Data classification and labeling: Classify data according to sensitivity and implement stricter protection for highly sensitive data.
- Access control: Enforce the principle of least privilege to limit who can access what data and manage permissions based on identity, role and context.
- Data encryption: Strong encryption is used during transmission and storage to prevent data interception or leakage.
- Data desensitization and anonymization: removing or encrypting sensitive personal information when training or presenting data.
Model Layer Protection
- Adversarial training: adversarial samples are added during the training process to improve the robustness of the model.
- Regularization and defensive distillation: reducing overfitting using regularization techniques, compressing models and enhancing robustness through distillation.
- Differential privacy: adds noise to the gradient update, limiting the impact of individual samples on the model.
- Model validation and testing: comprehensive security testing before deployment, including adversarial sample testing, privacy assessment, etc.
- Model Signature and Integrity Detection: Use digital signatures to ensure that the model has not been tampered with and hash checks to detect anomalies in real time.
application layer defense (ALD)
- Input validation and cleanup: Strict validation and cleanup of all user inputs, filtering out malicious or unusual inputs.
- Output Filtering: Perform content review to reject output containing harmful, offending or sensitive information before the model output is displayed to users.
- Rate limiting and query control: Limit the frequency and number of queries for a single user or IP to prevent abuse.
- Data source management for RAG systems: If Retrieval Augmentation Generation (RAG) is used, external data sources are strictly controlled and scrutinized to prevent the injection of malicious content.
Tissue layer protection
- Employee security training: raising technical team awareness of AI security threats and teaching secure development practices.
- Incident Response Plan: Develop a clear process for responding to incidents, including detection, isolation, investigation and recovery.
- Vendor Management: Regularly audit the security practices of third-party vendors to ensure that they meet company standards.
- Third-party assessment: External security organizations are invited to conduct independent penetration tests and security audits.
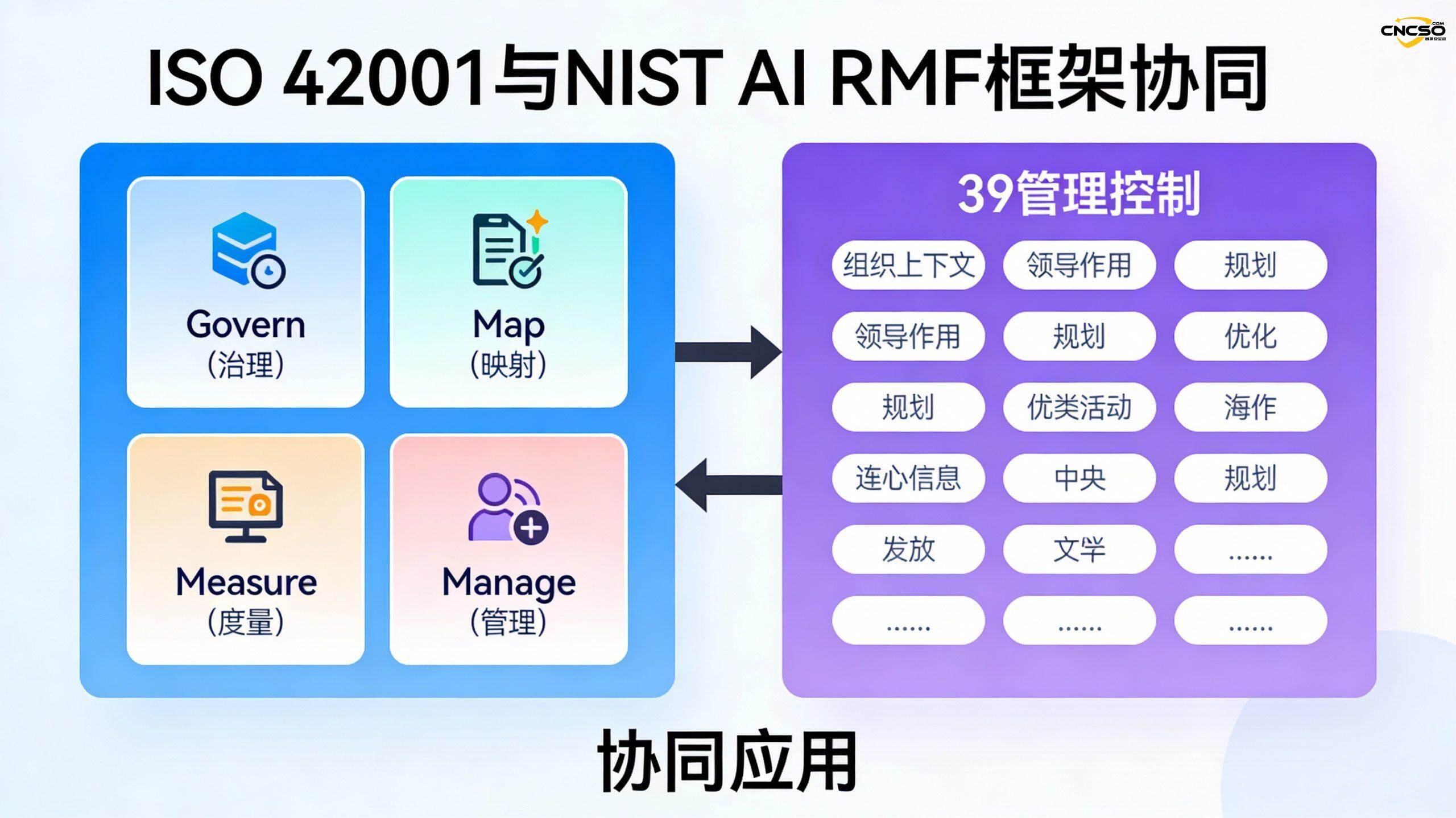
VI. Standardizing AI Security Frameworks: ISO/IEC 42001 and the NIST AI RMF
6.1 ISO/IEC 42001: AI Management System Standard
ISO/IEC 42001 is the first international standard for AI management systems and provides structured guidance for organizations to establish and maintain an AI management system. Its core features include:
- Broad scope: covers the entire lifecycle of an AI system, from planning to operations and maintenance.
- 39 management controls: covering a wide range of aspects such as AI governance, risk management, data protection, and transparency.
- Certification Audit: Supports third-party audits and certifications to help organizations validate theirAI Security Practices.
6.2 NIST AI Risk Management Framework (NIST AI RMF)
The NIST AI RMF is a voluntary framework published by the National Institute of Standards and Technology that focuses on AI risk management and contains four core functions:
- Governance: establish a risk-aware culture and define risk management policies and processes
- Map: Identifying Potential Risks in AI Systems
- Measure: Assessing the likelihood and impact of identified risks
- Manage: implementation of risk mitigation measures
6.3 Synergistic application of the two frameworks
Organizations can use ISO/IEC 42001 in conjunction with the NIST AI RMF:
- AI-specific risk identification and assessment using the NIST AI RMF
- Building a more comprehensive AI management system using ISO/IEC 42001
- The mapping relationship between the two frameworks allows organizations to achieve compliance more efficiently.
VII. Real-world cases and best practices
7.1 Case study: attack chain of an AI system from an attack perspective
To gain a deeper understanding of how AI security threats actually occur, let's analyze a realistic attack scenario - a malware detection model bypass attack:
Phase I: Reconnaissance
- Attackers discovered that the malware detection model used by a company was based on methods published in academic papers
- By analyzing the company's blog and technical documentation, it was learned that a specific open source framework was used
Stage 2: Model access
- Attackers repeatedly query the company's security API to observe the model's response to different inputs
- Inferring the model's classification decision boundaries through statistical analysis
Stage III: Preparation for attack
- Replicated a similar model in his own environment
- Designing adversarial samples using gradient descent methods that can trick models into classifying malware as legitimate software
- Adding generic bypass features to the adversarial samples ensures that they work for the target model
Stage IV: Implementation
- Submitting carefully crafted malware samples (containing bypass features) to the company's detection system
- The model incorrectly classifies it as legitimate software and the malware successfully bypasses the defenses
Defense Revelation:
- Adversarial robustness training needs to be implemented to make the model insensitive to such subtle perturbations
- Introducing behavioral analysis to detect software that appears legitimate but behaves abnormally
- Frequency limitation and anomalous pattern detection for API queries to prevent large-scale probing by attackers
7.2 Best Practice Recommendations for Building Enterprise AI Security
Based on the AI security threat matrix and defense framework, enterprises should follow the following principles when building an AI security system:
- Risk-driven prioritization: Prioritize defenses based on business impact and threat likelihood. Rather than seeking to be all things to all people, resources should be focused on high-risk, high-impact areas.
- Full lifecycle coverage: not only focusing on the model inference phase, but also protecting every aspect of data collection, training, fine-tuning, deployment and maintenance.
- Defense depth: Layered defense (such as the four-layer defense system proposed in this paper) is used to deploy control measures at multiple levels to avoid a single point of failure.
- Continuous evolution: AI security threats are constantly evolving, and organizations need to establish continuous vulnerability management, penetration testing and defense update mechanisms.
- Cross-team collaboration: AI security is not only the responsibility of the security team, but also requires the cooperation of multiple teams such as AI engineers, product managers, legal, operations and maintenance.
- Transparency and Interpretability: Build trust by clearly explaining the capabilities, limitations, and safety measures of AI systems for users and stakeholders.
VIII. Conclusion: building a future-oriented AI security system
The AI Security Threat Matrix provides organizations with a systematic and actionable framework for identifying and responding to multi-dimensional threats to AI systems. Unlike traditional cybersecurity, AI security is uniquely complex-attacks can occur in all aspects of data, modeling, and reasoning, and the attacker's capabilities and level of knowledge have a huge impact on the viability of the attack.
Businesses should recognize the following:
- AI security is a systemic issue that needs to be addressed in a comprehensive manner from data governance, model development, application deployment, operation and maintenance monitoring, rather than relying on a single defense measure.
- Maturity assessments are important. Understanding current threats that are mature (e.g., data poisoning, adversarial samples) and those that are still being researched (e.g., more advanced privacy attacks) helps organizations better plan defense investments.
- Defense and development need to be balanced. Some defenses (e.g., differential privacy, defense against distillation) may reduce the accuracy of the model, and companies need to find a balance based on their business characteristics.
- Technical defense needs to be supported by systems and processes. Technical defense alone is far from enough, but also need to establish a soundAI Security Governancesystem, staff training mechanism, and incident response plan.
- Alignment to standards frameworks. Adopting internationally recognized standards frameworks such as ISO/IEC 42001 and NIST AI RMF can help organizations systematically build AI security systems and prepare for regulatory compliance.
In the face of the rapid evolution of AI technology and the constant changes in the threat situation, enterprises need to establish a continuously evolving and adaptive AI security system, and the AI security threat matrix is the important foundation of this system.
reference citation
- Official AI Security Threat Matrix website:https://aisecmatrix.org/matrix
- NIST AI Risk Management Framework:https://airc.nist.gov/
- ISO/IEC 42001 standard: AI management system standards issued by the International Electrotechnical Commission
- MITRE ATLAS Framework: an ATT&CK-like framework for AI and machine learning systems
Original article by Chief Security Officer, if reproduced, please credit https://www.cncso.com/en/ai-security-based-on-the-attck-framework.html







